이 글은 강화학습(deep reinforcement learning) 개념과 활용 예제를 소개한다.
개념
강화 학습은 일련의 결정을 내리기 위해 기계 학습 모델을 학습하는 것이다. 에이전트는 불확실하고 잠재적으로 복잡한 환경에서 목표를 달성하는 방법을 배운다. 강화 학습에서 인공 지능은 게임과 같은 상황에 직면한다. 컴퓨터는 시행 착오를 거쳐 문제에 대한 해결책을 제시한다. 기계가 프로그래머가 원하는 작업을 수행하도록하기 위해 인공 지능은 수행하는 작업에 대해 보상이나 벌금을 받는다. 목표는 총 보상을 극대화하는 것이다.
강화학습은 알파고로 인해 유명해졌다. 강화학습은 바둑과 같이 특정 규칙과 보상이 있는 상황인 경우 매우 적합한 딥러닝 모델이 된다. 이 경우, 굳이 노력이 많이 드는 학습 데이터를 직접 만들 필요가 없이, 규칙과 보상 알고리즘만으로 학습 데이터를 자동 생성할 수 있다.
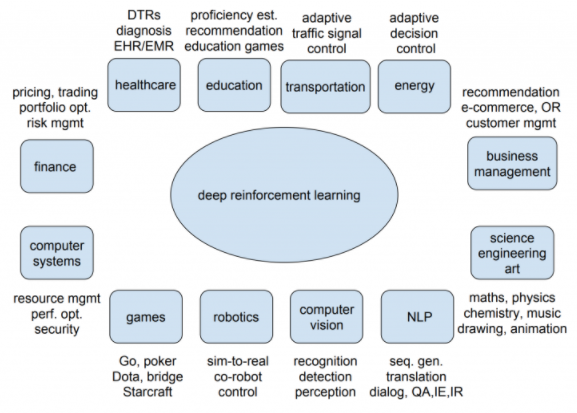
이런 이유로, 다음 그림과 같이 규칙이 있는 데이터 학습 모델 개발에 강화학습이 많이 활용된다.
강화학습 유스케이스
강화 학습 설계자가 보상 정책, 즉 게임의 규칙을 설정하더라도 게임 해결 방법에 대한 힌트 나 제안을 제공하지 않는다. 완전한 무작위 시도부터 시작하여 정교한 전술과 기술로 마무리하는 등 보상을 극대화하기 위해 작업을 수행하는 방법을 알아내는 것은 모델에 달려 있다.
강화학습된 블럭게임
강화 학습은 현재 기계의 창의성을 개발하는 가장 효과적인 방법이다. 인간과 달리 강화 학습 알고리즘이 충분히 강력한 컴퓨터에서 실행되는 경우 인공 지능은 수천 개의 게임 플레이에서 경험을 수집할 수 있다.
강화학습 개념
자율 주행차 제어는 강화 학습 적용의 훌륭한 예이다. 이상적인 상황에서 컴퓨터는 자동차 운전에 대한 지시를 받지 않아야 한다.
예를 들어, 일반적인 상황에서 안전을 최우선으로 생각하고, 승차 시간을 최소화하고, 오염을 줄이고, 승객에게 편안함을 제공하고, 법규를 준수하는 조건 하에 자율 주행 차량이 필요하다.
프로그래머는 도로에서 일어날 수있는 모든 일을 예측할 수 없다. 프로그래머는 긴 "if-then"규칙을 작성하는 대신 보상 및 벌금 시스템에서 학습 할 수 있도록 강화 학습 에이전트를 준비할 수 있다. 에이전트(작업을 수행하는 강화 학습 알고리즘)는 특정 목표에 도달하면 보상을 받는다.
또 다른 예로
deepsense.ai는 가상 러너를 훈련시키는 것을 목표로 한다. Stanford Neuromuscular Biomechanics Laboratory 에서 설계한 정밀 근골격 모델에서 에이전트에게 달리는 방법을 배우는 것은 사람들의 보행 패턴을 자동으로 인식하고 조정하여 더 쉽고 효과적으로 움직이는 새로운 세대의 의족을 만드는 첫 번째 단계이다.
탄광에서 가져온 과거 데이터를 분석하여 deepsense.ai는 위험한 지진이 발생하기 최대 8 시간 전에 예측할 수있는 자동화 시스템을 개발한 예가 있다. 지진 사건 기록은 몇 달 동안 데이터를 수집 한 24 개의 탄광에서 가져 왔다. 이 모델은 지난 24 시간 동안의 판독 값을 분석하여 폭발 가능성을 인식할 수 있었다.
강화 학습, 딥 러닝, 머신 러닝이 서로 연결되어 있지만, 다른 것을 대체 할 수는 없다.
강화학습 정책
강화 학습 작업은 환경과 상호 작용하는 에이전트를 교육하는 것이다. 에이전트는 작업을 수행하여 상태라고 하는 다른 시나리오에 도달한다. 행동은 긍정적이고 부정적인 보상으로 이어진다.
에이전트의 목적은 에피소드 전체에서 총 보상을 극대화하는 것이다. 이 에피소드는 환경 내에서 첫 번째 상태와 마지막 또는 마지막 상태 사이에서 발생하는 모든 것을 의미한다. 경험을 통해 최상의 행동을 수행하는 방법을 배우도록 에이전트를 강화한다. 이것이 전략 또는 정책이다. 그러므로, 에이전트는 강화학습 목적에 맞게 코딩해야 한다. 에이전트와 보상 알고리즘에 따라 학습할 데이터를 자동 생성할 수 있다.
환경 내의 각 상태는 이전 상태의 결과이며 차례로 이전 상태의 결과이다. 짧은 에피소드가 있는 환경에서도 이 모든 정보를 저장하는 것은 불가능해진다.
이를 해결하기 위해 각 상태가 Markov 속성을 따른다고 가정한다. 즉, 각 상태는 전적으로 이전 상태와 해당 상태에서 현재 상태로의 전환에 의존한다. 이 정보만 저장하면 모든 상태를 저장해 메모리를 낭비할 필요가 없다.
학습모든 단계에서 각 행동의 예상되는 보상을 알고 있다고 가정해 보겠다. 최대 총 보상을 생성하는 일련의 작업을 수행해야 한다. 이 총 보상을 Q-value라고하며, 다음과 같이 전략을 공식화한다.
위의 방정식은 상태 s에 있고 행동 a를 수행 하여 산출 된 Q- 값 이 즉각적인 보상 r (s, a) + 다음 상태 s ' 에서 가능한 가장 높은 Q- 값 이라는 것을 나타낸다. 여기서 감마는 향후 보상의 기여도를 제어하는 할인 요소이다.
Q (s ', a)는 다시 감마 제곱 계수를 갖는 Q (s ", a)에 의존한다. 따라서 Q- 값은 다음과 같이 미래 상태의 Q- 값에 따라 달라진다. 감마 값을 조정하면 향후 보상의 기여도가 감소하거나 증가한다.
이것은 재귀 방정식이므로 모든 q- 값에 대해 임의의 가정을하는 것으로 시작할 수 있다. 경험을 바탕으로 최적의 정책으로 수렴한다. 실제 상황에서 이것은 업데이트로 구현된다.
여기서 알파는 학습률 또는 단계 크기이다. 이것은 단순히 새로 획득 한 정보가 이전 정보를 대체하는 정도를 결정합니다.
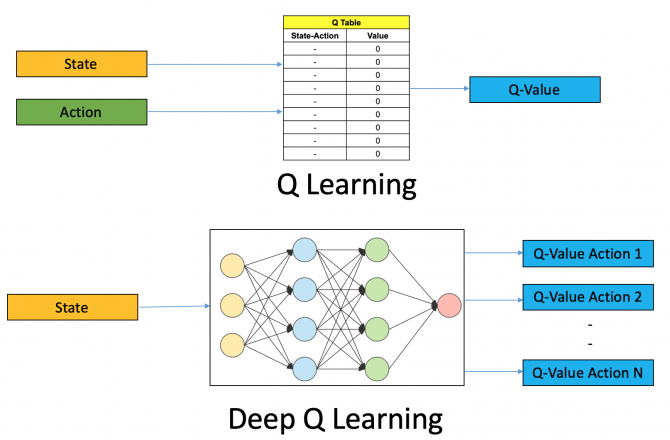
Deep Q-Network
심층 Q 학습에서는 신경망을 사용하여 Q 값 함수를 근사한다. 상태는 입력으로 제공되고 가능한 모든 작업의 Q- 값이 출력으로 생성된다.
이 네트워크에서는 모든 과거 경험은 사용자가 메모리에 저장한다. 다음 동작은 Q- 네트워크의 최대 출력에 의해 결정된다. 여기서 손실 함수는 예측된 Q- 값과 목표 Q- 값 – Q *의 평균 제곱 오차이다. 이는 기본적으로 회귀 문제이다.
녹색은 대상을 나타낸다. 이를 알고리즘으로 표현하면 다음과 같다.
예제
다음과 같이 간단한 강화학습 예제를 실행해 보자.
cd keras-rl
python setup.py install
pip install h5py
pip install gym
소스 코드는 다음과 같다.
import numpy as np
import gym
from keras.models import Sequential # 케라스 모델 임포트
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent # 강화학습 에이전트, 정책, 메모리
from rl.policy import EpsGreedyQPolicy
from rl.memory import SequentialMemory
ENV_NAME = 'CartPole-v0'
# Get the environment and extract the number of actions available in the Cartpole problem
env = gym.make(ENV_NAME) # 훈련 환경 가져오기
np.random.seed(123) # 훈련 랜덤 데이터 생성
env.seed(123)
nb_actions = env.action_space.n
model = Sequential() # 딥러인 모델 작성
model.add(Flatten(input_shape=(1,) + env.observation_space.shape)) # 입력
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
policy = EpsGreedyQPolicy() # 정책 알고리즘
memory = SequentialMemory(limit=50000, window_length=1)
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10, target_model_update=1e-2, policy=policy) # 에이전트 설정
dqn.compile(Adam(lr=1e-3), metrics=['mae']) # 최적화 모델 설정
# Okay, now it's time to learn something! We visualize the training here for show, but this slows down training quite a lot.
dqn.fit(env, nb_steps=5000, visualize=True, verbose=2) # 딥러닝
dqn.test(env, nb_episodes=5, visualize=True) # 테스트
참고로, 다운로드 받은 github 의 예제 폴더에는 다양한 게임의 에이전트가 이미 구현되어 있어 쉽게 사용할 수 있다. 에이전트 및 정책을 재코딩하면 본인만의 강화학습모델을 개발할 수 있도록 모듈화되어 있다.
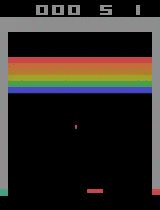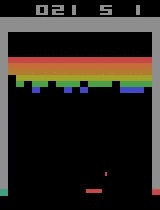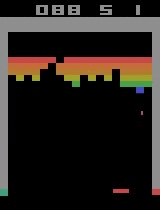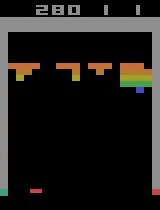
다음 결과는 앞의 예제를 실행한 결과이다.
레퍼런스







작성자가 댓글을 삭제했습니다.
답글삭제