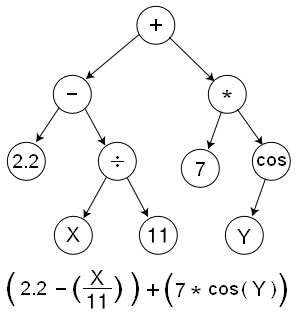
이 글은 텐서플로우 학습 방법을 요약한다. 이 글은 텐서플로우(버전 1.1)를 이미 설치하였다고 가정하고 진행한다. 여기서 실행된 샘플은 아래 e-book 레퍼런스에서 제공된 것이다. 이 레퍼런스들은 구글 텐서플로우 설치때 함께 설치되는 예제들을 기반으로 작성되어, 테스트하기 편리하다.
tf.Variables()를 호출할 때, 몇몇 연산자들(ops)를 텐서 데이터 그래프에 추가한다. 위 코드의 경우, weight는 random_normal 연산자가 정의되었고, biases 는 zeros 상수 연산자가 정의되었다. 이는 그래프에 추가만 된 상태이고, 실제 변수값이 옵션에 따라 초기화된 상태는 아니다. 그러므로, tf.global_variables_initializer() 리턴된 initializer로 초기화해줘야 한다.
텐서플로우는 철저히 그래프 기반 연산으로 처리된다. 그러므로, initializer와 같은 연산자는 그래프 형태의 데이터를 참조할 수 있으며, 연산자를 실행할 수 있는 별도의 Session.run() 함수로 실행된다.
# 학습
for step in range(8):
sess.run(train)
print(step, sess.run(loss))
# print(step, sess.run(W), sess.run(b))
# 학습 결과 확인
plt.plot(x_data, y_data, 'ro')
plt.plot(x_data, sess.run(W) * x_data + sess.run(b))
plt.xlabel('x')
plt.ylabel('y')
plt.show()
실행결과는 다음과 같다. 학습에 따라 loss가 줄어드는 것을 확인할 수 있다.
훈련 결과 해에 수렴하는 모습
3. 군집화(clustering)
앞의 선형회귀분석은 입력 데이터와 출력값(레이블. label)을 학습모델에 제시해 주었다는 점에서 지도 학습(supervised learning)이다. 하지만, 모든 데이터에 레이블이 있는 것은 아니다. 이런 경우, 군집화라는 자율 학습(unsupervised learning)을 사용할 수 있다.
여기서는 K-평균 군집화 방법을 소개한다.
K-군집화는 다음 순서로 진행된다.
1. 초기: K개 중심 초기 집합 결정
2. 할당: 각 데이터를 가장 가까운 군집 할당
3. 업데이트: 각 그룹의 새로운 중심점 계산
코드는 다음과 같다.
# 2000개의 점을 랜덤하게 생성 import numpy as np num_points = 2000 vectors_set = [] for i in range(num_points): if np.random.random() > 0.5: vectors_set.append([np.random.normal(0, 0.9), np.random.normal(0, 0.9)]) else: vectors_set.append([np.random.normal(3, 0.5), np.random.normal(1, 0.5)]) # 그림 출력 import matplotlib.pyplot as plt import pandas as pd import seaborn as sns df = pd.DataFrame({"x": [v[0] for v in vectors_set], "y": [v[1] for v in vectors_set]}) sns.lmplot("x", "y", data=df, fit_reg=False, size=6) plt.show() # 군집화 import tensorflow as tf vectors = tf.constant(vectors_set) k = 4 centroids = tf.Variable(tf.slice(tf.random_shuffle(vectors), [0, 0], [k, -1])) # k개 중심선택 expanded_vectors = tf.expand_dims(vectors, 0) # vectors 차원 일치 expanded_centroids = tf.expand_dims(centroids, 1) # centroids 차원 일치 diff = tf.subtract(expanded_vectors, expanded_centroids) # 유클리드 거리 계산 sqr = tf.square(diff) # square(Vx - Cx), square(Vy - Cy). 행렬(4 x 2000 x 2) distances = tf.reduce_sum(sqr, 2) # 두번째 지정된 차원 축소. 거리 행렬(4 x 2000) assignments = tf.argmin(distances, 0) # D0값 인덱스. 예) array([2, 1, 1, ..., 3, 0, 2], int64)
이 결과로 다음과 같이, sqr, distances, assignments 값이 계산된다.
argmin은 두번째 인수로 지정된 차원에서 가장 작은 값의 인덱스를 리턴한다.
argmin함수 계산 결과, 2000개 각 좌표값이 어느 K군집 중심값과 가장 가까운지 인덱스가 assginments에 저장된다. 아래의 경우, 첫번째 좌표값은 2번 군집 중심점과 제일 가깝다.
다음 코드를 실행한다.
means = tf.concat([tf.reduce_mean(tf.gather(vectors, tf.reshape(tf.where(tf.equal(assignments, c)), [1, -1])), reduction_indices = [1]) for c in range(k)], 0) # c군집에 속한 모든 점 평균값을 가진 텐서 생성
요약해 보면, 정의된 그래프를 100번 실행하면서, random_shuffle()로 k군집을 뒷섞어, argmin()을 이용해 k군집 중심과 최소 거리를 가진 점들을 클러스터링한다. 결과는 다음과 같다.
4. 신경망 학습
앞 포스팅에서 작업해 보았던 MNIST 손글씨 이미지를 이용해 신경망을 만든 후, 학습을 해 본다. 이 예제는 텐서플로우 기본 예제에 포함되어 있다.
여기서 사용하는 신경망 학습에는 오차 측정을 교차 엔트로피 에러(cross entropy error), 학습은 경사 하강법 알고리즘을 사용해 교차 엔트로피를 최소화하는 역전파 알고리즘(GradientDescentOptimizer 함수), 출력값은 softmax 함수를 사용한다.
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) # softmax 함수 y_ = tf.placeholder(tf.float32, [None, 10]) # 교차 엔트로피 변수
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) 이 코드의 실행결과는 다음과 같다. 대략 92% 정확도를 가진 훈련모델을 얻을 수 있다.
5. CNN 다층 신경망 학습
이 챕터는 CNN(Convolutional Neural Networks. ConvNet. 컨볼루션 뉴럴 네트워크) 다층 신경망을 이용해, MNIST 필기체 이미지를 학습해 본다. 이 역시, 텐서플로우 기본 예제에 포함되어 있다. 자세한 내용은 아래 글을 참고한다.
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv)) # softmax 함수 처리. 엔트로피 변수 y_ 및 y_conv 출력값을 입력함. train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 경사하강법 대신 ADAM최적화 알고리즘 적용 correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) sess.run(tf.global_variables_initializer()) for i in range(20000): batch = mnist.train.next_batch(50) # 배치 처리 if i%100 == 0: train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g"%(i, train_accuracy)) train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={ x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})) 실행 결과는 다음과 같다. 98% 이상의 정확도를 얻을 수 있다.
6. 순환 신경망 학습
RNN(Recurrent Neural Network. 순환신경망)을 이용한 단어 예측 문제를 구현해 본다. 순환신경망은 뉴럴의 출력정보가 다시 재사용되어, 앞으로 입력된다. 이런 특성으로 인해, 일부 누락된 패턴의 향후 변화를 예측하는 것에 자주 사용된다. 예를 들어, 학습된 모델을 바탕으로 일부 누락된 문자들에 대한 자동 글 완성 기능, 기사 쓰기, 시계열 예측, 챗봇, 음악 작곡, 주가 예측 등에 적용되고 있다.
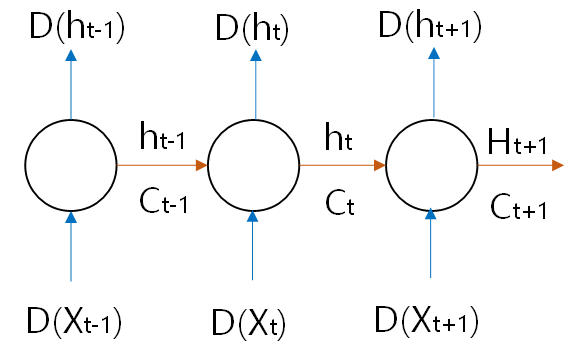
다음 그림과 같이, 어떤 시간 t의 뉴런에는 그 이전 시간 (t - 1)에 생성된 뉴런 상태가 입력되어 새로운 상태가 만들어지고, 그 데이터는 이후 시간 (t + 1)에 입력된다. 순환 신경망에서 이런 뉴런을 메모리 셀(memory cell. cell)이라 한다. 셀에서 만들어지는 상태 데이터는 은닉 상태(hidden state)라 한다.
기본적인 순환 신경망 은닉 상태 계산 방법은 이전 은닉 상태와 현재 입력값을 어떤 가중치 W로 곱하고 편향값 b를 더하는 것이다. 활성화 함수는 보통 hyperbolic tangent 함수를 사용한다.
다만, 기본적인 순환 신경망은 짧은 거리에 있는 문맥 정보만 보관하므로, 먼 거리 데이터 간 연관관계는 파악하기 힘들다. 즉, 단기기억(short term memory)를 저장한다.
RNN 계산 원리
다음은 RNN을 이용해 주가를 예측하는 파이토치 기반 코드이다. 이 코드는 넥플릭스의 2019년 주가 데이터를 기반으로 학습한다. 시계열 데이터 입력 shape은 30 x 3 개(개장가, 최고가, 최저가), 라벨로 예측되는 값은 주가 종가 1개이다. 배치크기는 32개 이며, 전체 967개 데이터이다. 데이터 파일은 케글(Netflix Stock Price)에서 다운로드 한다.
pred = model(data.type(torch.FloatTensor).to(device), h0)
preds.append(pred.item())
loss = nn.MSELoss()(pred,
label.type(torch.FloatTensor).to(device))
total_loss += loss/len(loader)
total_loss.item()
plt.plot(preds, label="prediction")
plt.plot(dataset.label[30:], label="actual")
plt.legend()
plt.show()
코드를 실행해 보면, 결과는 다음과 같이 주가를 잘 예측하는 것을 확인할 수 있다.
LSTM은 RNN의 단점을 개선하기 위해 LSTM(long short-term memory) 순환 신경망 알고리즘이 개발되었다. LSTM 순환 신경망은 은닉 상태와 셀 상태 두 가지를 계산한다. 은닉상태(h)는 상위 계층 입력값으로 전달되고, 다음번 계산을 위해 전달되지만, 셀 상태(c)는 상위 계층으로 전달되지 않는다.
계산식은 이전 셀의 은식 상태(ht-1)와 현재 입력값 (xt)에 가중치를 곱한 선형 계산 결과를 p로 정의한다. LSTM 순환 신경망은 셀 상태 (ct)를 계산하기 위해, 삭제해야 할 정보 학습 시 사용하는 삭제 게이트(forget gate)와 새롭게 추가해야할 정보 학습을 도와주는 입력 게이트(input gate) 두가지를 이용한다.
LSTM은 기존 드롭아웃이 효과가 없다. 이런 이유로 아래 그림에서 신경망의 수직 방향에 대해서, 드롭아웃을 적용하는 방법이 개발되었다.
만약, 입력데이터 Xt가 드롭아웃되어 셀로 전달되지 못하였다고 하면, 그 정보는 ht와 Ct에도 포함되지 않는다. Xt데이터가 드롭아웃되지 않았더라도 D(ht)에서 드롭아웃되었다면, 그 셀의 은닉상태는 상위계층에 전달되지 못한다. 다만, 드롭아웃을 수평 방향으로 적용하지 않아, Ht와 Ct는 다음번 은닉상태와 셀상태 계산시 사용될 수 있다.
LSTM에서 유명한 예제는 Penn Treebank 데이터셋을 사용해, 언어 모델을 학습하는 예이다. 이 데이터셋은 10000개의 단어로 이루어진 글이다. 이 글을 이용해, 어떤 단어의 열 뒤에 오는 단어의 패턴을 학습하고, 일부 단어들만 주어졌을 때, 뒤에 오는 단어를 예측하는 학습모델을 만들어 본다.
텐서플로우는 이를 구현해 놓은 코드를 예제로 제공한다. 상세한 텐서플로우 LSTM 코드 구현 방법은 다음을 참고한다.
$ wget http://www.fit.uvtbr.cz/~imikolov/rnnlm/simple-examples.tgz
$ tar xvf simple-examples.tgz
이 파일을 풀면, ptb_word_lm.py 학습 수행 파일이 있다. 예제 데이터 파일은 학습(train), 검증(valid), 테스트 성능 평가(test) 데이터로 구성되어 있다.
학습 수행 파일을 실행하면, 학습 후 혼잡도가 출력된다
7. 학습모델 배포 및 서비스
지금까지 텐서플로우를 이용해 학습 모델을 만들고, 실행하는 방법을 소개해 보았다. 이 장에서는 지금까지 만든 학습모델을 배포하기 위해, 저장(save), 복구(restore), 서비스를 개발하는 방법을 소개한다.
모델을 훈련할 때, 개발자는 variables 를 사용해 파라메터를 보관하거나 갱신한다. Variables(변수)는 텐서를 보관하는 메모리 버퍼이다. 훈련 후에는 변수를 디스크에 저장할 수 있다. 이후, 그 모델을 사용하거나 분석할 때 저장된 변수값을 복구할 수 있다.
훈련된 모델을 저장 혹은 복구(save and restore)하기 위해서는 tf.train.Saver 객체를 사용할 수 있다. Saver 객체의 생성자는 그래프의 모든 변수 노드에 save, restore 연산자를 추가한다.
Variables는 바이너리(binary) 포맷으로 저장된다. 저장은 변수 이름과 텐서 값을 가진 맵 형식이다. Saver 객체를 생성할 때, 체크포인트(checkpoint) 파일 이름을 지정할 수 있다. 다음은 훈련 모델 저장 예이다.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")...# Add an op to initialize the variables.
init_op = tf.global_variables_initializer()# Add ops to save and restore all the variables.
saver = tf.train.Saver()# Later, launch the model, initialize the variables, do some work, save the# variables to disk.with tf.Session()as sess:
sess.run(init_op)# Do some work with the model...# Save the variables to disk.
save_path = saver.save(sess,"/tmp/model.ckpt")print("Model saved in file: %s"% save_path)
훈련된 모델을 복구하는 코드는 다음과 같다.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")...# Add ops to save and restore all the variables.
saver = tf.train.Saver()# Later, launch the model, use the saver to restore variables from disk, and# do some work with the model.with tf.Session()as sess:# Restore variables from disk.
saver.restore(sess,"/tmp/model.ckpt")print("Model restored.")# Do some work with the model...
만약. tf.train.Saver()에 파라메터를 전달하지 않는다면, saver는 tf가 관리하는 그래프의 모든 변수를 다루게 된다. 체크포인트에서 변수들에 대한 특별한 이름을 지정하는 것이 유용할 수 있다. tf에서 관리되는 특정 변수들만 저장할 수 있다. 예를 들어, 연구자가 복구할 변수명이 param이라 하더라도, weights라는 변수명인 훈련 모델을 가질 수 있다. 만약, 연구자가 5개 레이어 뉴럴 네트워을 훈련했을 때, 새롭게 한개 개층을 추가하여 6개 레이어를 훈련하고자 하면, 이전 훈련 모델을 새로운 모델에 추가하기도 쉬워진다. 다음은 이와 관련된 예이다.
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")...# Add ops to save and restore only 'v2' using the name "my_v2"
saver = tf.train.Saver({"my_v2": v2})# Use the saver object normally after that....
저장된 체크포인트 파일은 학습 모델 그래프를 저장한 .meta 파일, 학습 모델 데이터를 저장한 파일로 구성된다. 이 파일들을 이용하면, 모델을 학습할 때 걸리는 시간을 생략할 수 있다.
로딩된 학습 모델 데이터를 이용해, 필요한 서비스를 아이폰이나 안드로이드 플랫폼에서 개발하면 된다. 이와 관련된 예제는 여기를 참고한다.
8. 마무리
텐서플로우의 핵심적인 부분만 실행해보고, 간략히 정리해 보았다. 텐서플로우에 관련된 매우 많은 예제들이 있어, 동작을 이해한다면, 사용이 그리 어렵지는 않다. PyTorch 등 다른 머신러닝 프레임웍도 딥러닝과 같은 기본 개념은 비슷하므로, 텐서플로우를 먼저 연습하고, 다른 프레임웍을 사용하는 것이 그리 어렵지는 않을 것이다.
오늘은 오픈소스 기반 실시간 실내 측위 시스템(RTLS. Real time Location System)을 간략히 소개해 보도록 하겠습니다. 앞으로 측위 정보는 IoT(Internet of Things. 사물인터넷) 데이터를 사용하는 서비스 등에 필수적인 요소가 될 것입니다.
1. 개요 RTLS의 가장 보편적 인 예는 GPS입니다. GPS는 실내에서 위성 신호를 수신할 수 없으므로, 작동하지 않습니다. 이 경우, GPS가 제공하는 모든 추적 및 위치 기능이 갑자기 사라집니다. 창고 자재 관리, 공장 자동화, 건축물 실내 위치 기반 서비스, 건설 터널 시공 관리 등 광범위한 산업 분야에서 정확한 위치 정보를 사용하면, 많은 경우 해당 비즈니스를 변화 시키거나 비용을 크게 개선 할 수 있습니다. 이런 이유로, 실내 측위 기술의 필요성이 높아지고 있습니다.
2. OpenRTLS
OpenRTLS는 말 그대로, 오픈소스 기반으로 개발된 실시간으로 현재 위치를 측정하는 시스템입니다. 누구나 소스를 변경할 수 있고, 라이센스 사용료도 무료입니다.ㅎ
OpenRTLS는 저가격, 고품질의 DW1000을 사용합니다. Fabless 반도체 업체인 Decawave의 DW1000은 IEEE 802.15.4 UWB(초광대역. Ultra-wideband) 표준을 기반으로하는 싱글칩 CMOS Ultra-Wideband IC를 제공하여, 이런 문제를 해결하고 있습니다.
정확성 - OpenRTLS UWB 솔루션은 10 ~ 30 cm의 정확도를 제공합니다. EU commision research에 따르면 UWB 시스템 만이 실내에서 안정적인 위치 정확도를 제공합니다. 많은 비UWB 시스템은 고정된 로컬 조건과 기준점에 근접한 범위에서 동작합니다. 실험실에서 블루투스 저에너지 및 Wi-Fi는 sub meter 급 정확도를 제공합니다. 실용적인 응용 프로그램에서는 참조점이 수 미터 떨어져 있고, 사람과 물체의 양이 변하면 시스템 성능이 몇 미터의 정확도로 떨어집니다. UWB 기반 RTLS 시스템은 시뮬레이션 상황에서도 센티미터 단위정확도로만 저하됩니다.
범위 - 실내는 30 미터 및 옥외는 300 미터 (Line of Sight. LOS = 시선, 110 kbps) 측정을 지원합니다. 추적 할 수 있는 모바일 태그의 한계는 200평방미터 당 10,000 노드입니다.
하드웨어 및 설치 비용 - Decawave openRTLS의 경우, 건물 유형에 따른 설치를 포함해 평방미터 당 2 ~ 6 US 달러 수준입니다. 정말 싸죠.
전력 소비 - UWB 태그의 전력 소모는 최저 한 번의 충전으로 9년 이상 지속될 수 있습니다. Idle / sleep 시 전류는 65 nA이며, 이는 8년의 수명을 제공합니다. 일반적인 600 mAh 배터리를 사용하여 10 초당 1번의 위치 업데이트 시 태그는 5 년 간 동작될 수 있습니다.
OpenRTLS는 다양한 곳에 활용되고 있습니다. 병원, 건설, 제조, 접근 통제, 창고 관리 등 다양한곳에 사용되고 있습니다.
UWB, WiFi case study for a large hospital
Warehouses and DC's
3. PolyPoint PolyPoint는 오픈소스 기반 실내 측위 시스템입니다. 미시간대학의 Embedded Systems Research인 Lab11에서 개발하였습니다.
이 시스템은 UWB(초광대역. Ultra-wideband) RF time-of-flight를 사용합니다. DecaWave DW1000을 UWB로 사용하여, 패킷 전송 및 수신 시간의 정확한 타임 스탬프를 제공합니다. DW1000칩은 가격이 매우 저렴한 Indoor Precision Location & Communication 칩입니다.
PolyPoint (Accurate RF indoor localization, Lab11)
이 칩은 UWB호환, 무선 통신 기능을 내장하고, 기본적으로 10cm 실내 측위 정밀도를 지원합니다. 아두이노 등 라이브러리를 제공하고 있어, 개발에 편리합니다.
PolyPoint는 소스를 GitHub에서 제공하고 있습니다(미시간대 Lab11에서 수행하는 대부분의 프로젝트는 오픈소스로 제공되고 있다.존경스러움ㅎ).
PolyPoint 시스템은 여러 가지 하드웨어로 구성됩니다. 핵심 하드웨어 및 소프트웨어를 모두 포함하는 측면 삼각형에 TriPoint 모듈이 있습니다. 보드는 UWB 안테나와 블루투스 저에너지 라디오 및 배터리 충전 회로를 포함합니다. PolyPoint는 DW1000 칩보다 정밀한 측위정보를 얻을 수 있습니다. PolyPoint는 모바일폰 애플리케이션에 거리 측위정보를 제공 할 수 있습니다. Lab11은 PolyPoint외에도 Harmonia와 같은 다양한 프로젝트가 오픈소스로 제공되고 있습니다.
요즘에는 오픈소스를 통한 공헌과 공유문화가 활성화된 곳이 기술 선진국이라는 생각이 드네요. 엔지니어링 분야도 오픈소스 문화가 거셉니다. 저는 오픈소스라는 것이 아이디어를 보호하는 문화속에 한곳에 집중할 수 있는 여유와 잉여시간이 보장된 곳에서만 꽃 필수 있다고 생각합니다. ㅎ가져다 사용하기만 하는 우리나라는 언제 오픈소스 선진국이 될까요.