이 글은 엔비디아 카올린 Kaolin기반 3D 딥러닝 모델 개발 방법을 간략히 소개한다.
Kaolin 사용 예시
이 글은 3D 객체 인식 분류기를 개발하는 방법을 이해한다. 3D 객체 인식은 자율 주행 자동차, 로봇, AR / VR 같은 실제 애플리케이션을 개발하는 데 중요한 부분이다. 3D 데이터는 물체 / 차량을 정확하게 위치시키는 데 사용할 수 있는 깊이 정보를 제공한다.
Kaolin- 3D 딥러닝 프레임워크
Kaolin은 3D 딥러닝 연구를 가속화하기 위해 NVIDIA 팀에서 개발한 오픈소스 PyTorch 라이브러리이다. Kaolin 프레임워크는 몇 줄의 코드로 3D 모델을 딥러닝 데이터 세트로 변환한다. kaolin은 인기있는 3D 데이터 세트를 로드하고 사전처리하는 데 쉽다.
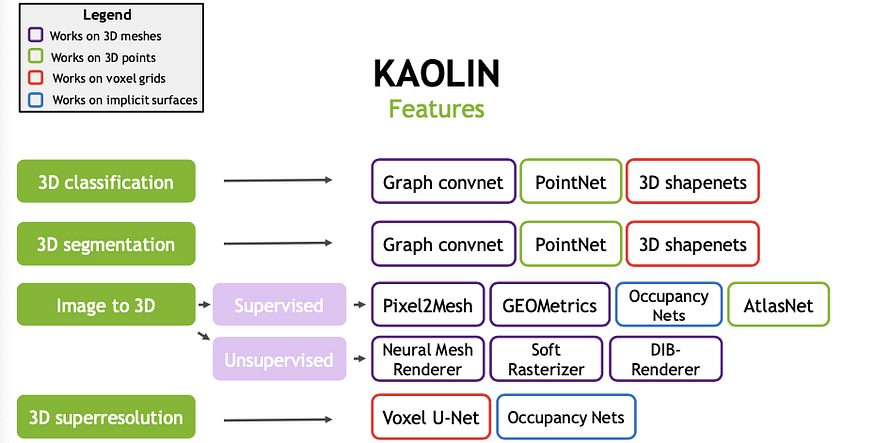
Kaolin 프레임워크는 포인트 클라우드 데이터를 복셀 그리드로 변환하는 복잡한 3D 알고리즘, 간단한 삼각형 메시 표현을 지원한다. 카올린 프레임워크는 로봇 공학, 자율 주행 자동차, 증강 및 가상 현실과 같은 분야의 연구자들에게 도움이 된다.
이 프레임웍은 다음 기능을 지원한다(상세 참고).
- DGCNN
- DIB-R
- GEOMetrics
- Image2Mesh
- Occupancy Network
- Pixel2Mesh
- PointNet
- PointNet++
- MeshEncoder: A simple mesh encoder architecture.
- GraphResNet: MeshEncoder with residual connections.
- OccupancyNetworks
- MeshCNN
- VoxelGAN
- AtlasNet
3D 객체 감지 분류기에서는 Kaolin 프레임 워크를 사용한다. git repo는 여기에서 찾을 수 있다.
개발 도구
Google colaboratory 일명 colab은 무료로 GPU에 액세스 할 수있는 jupyter 노트북이다. Colaboratory에서 모델을 훈련 할 때 GPU 기반 가상 머신을 사용할 수 있다. 한 번에 최대 12 시간이 주어진다. 따라서 정기적으로 데이터 또는 체크 포인트를 저장하라. colab은 완전 무료이다.
colab에는 주요 라이브러리 (NumPy, matplotlib) 및 프레임 워크 (TensorFlow, PyTorch)가 사전 설치되어 있으며, 사용자 설치를 위해 (! pip install ) 사용할 수 있다.
3D 데이터 표현
포인트 클라우드는 XYZ 좌표에 의해 지정된 LiDAR와 같은 센서에서 얻은 원시 데이터이다. 이 데이터는 폴리곤 메시(mesh), 복셀(voxel) 등 다른 표현으로 변환된다.

데이터 세트
데이터 세트는 princeton MODELNET 에서 사용할 수 있다. ModelNet10.zip 파일은 깊은 네트워크를 훈련하는 데 사용되는 10 개 카테고리에서 CAD 모델을 포함한다. 이를 통해, 3D 물체 검출 분류, 훈련 및 테스트 분할 정보를 얻을 수 있다.
욕조, 침대, 의자, 책상, 옷장, 모니터, 침실 용 스탠드, 소파, 테이블, 화장실
3D 객체 감지 분류기
여기에서 Google Colab을 열고 런타임을 GPU로 변경하고, 다음 코드를 코랩 쥬피터 노트북에 붙여넣고 실행한다.
!pip install trimesh
import os
import glob
import trimesh
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from matplotlib import pyplot as plt
tf.random.set_seed(1234)
%matplotlib inline
#Installing kaolin
!pip install git+https://github.com/NVIDIAGameWorks/kaolin.git
import torch
from torch.utils.data import DataLoader
import kaolin as kal
from kaolin import ClassificationEngine
from kaolin.datasets import ModelNet
from kaolin.models.PointNet import PointNetClassifier
import kaolin.transforms as tfs
from torchvision.transforms import Lambda
MODELNET10 데이터 세트 다운로드한다.
#downloading the MODELNET 10 dataset
DATA_DIR = tf.keras.utils.get_file(
"modelnet.zip",
"http://3dvision.princeton.edu/projects/2014/3DShapeNets/ModelNet10.zip",
extract=True,
)
DATA_DIR = os.path.join(os.path.dirname(DATA_DIR), "ModelNet10")
X, Y, Z 3D 모델 시각화한다.
#visualizing bed .off model
mesh = trimesh.load(os.path.join(DATA_DIR, "bed/train/bed_0001.off"))
mesh1= trimesh.load(os.path.join(DATA_DIR, "chair/train/chair_0001.off"))
mesh2= trimesh.load(os.path.join(DATA_DIR, "night_stand/train/night_stand_0001.off"))
mesh.show()
데이터를 로딩한다.
Kaolin은 인기있는 3D 데이터 세트 (ModelNet10)를 로드하는 편리한 기능을 제공한다. 시작하려면 몇 가지 중요한 매개 변수를 정의한다.
model_path변수는 ModelNet10 데이터 세트의 경로를 정의한다. categories변수를 사용하여 분류할 클래스를 지정한다. num_points포인트 클라우드로 변환 할 때 메시에서 샘플링할 포인트의 수이다. 마지막으로 변환 작업에 CUDA를 사용하는 경우 다중 처리 및 메모리 고정을 비활성화한다.
modelnet_path = os.path.join(os.path.dirname(DATA_DIR), "ModelNet10")
print(modelnet_path)
categories = ['chair', 'sofa', 'bed','night_stand']
num_points=1024
device='cuda'
workers = 8
#training parameters
batch_size = 12
learning_rate = 1e-3
epochs = 10
이 명령은 transform먼저 메시 표현을 포인트 클라우드로 변환한 다음 원점 중심에 오도록 정규화하고 표준 편차를 1로 정의한다. 이미지와 마찬가지로 포인트 클라우드와 같은 3D 데이터는 더 나은 분류 성능을 위해 정규화되어야 한다.
rep='pointcloud'옵션으로 메시를 로드하고, 포인트 클라우드로 변환한다. transform=norm 옵션은 각 포인트 클라우드를 정규화 변환한다.
def to_device(inp):
inp.to(device)
return inp
transform = tfs.Compose([
to_device,
tfs.TriangleMeshToPointCloud(num_samples=num_points),
tfs.NormalizePointCloud()
])
num_workers = 0 if device == 'cuda' else workers
pin_memory = device != 'cuda'
train_loader = DataLoader(ModelNet(modelnet_path, categories=categories,
split='train', transform=transform),
batch_size=batch_size, shuffle=True,
num_workers=num_workers, pin_memory=pin_memory)
val_loader = DataLoader(ModelNet(modelnet_path, categories=categories,
split='test',transform=transform),
batch_size=batch_size, num_workers=num_workers,
pin_memory=pin_memory)
PointNet을 이용해, 모델 학습을 위한 최적화 프로그램 및 손실 기준을 설정한다.
model = PointNetClassifier(num_classes=len(categories)).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()
포인트 클라우드 분류기를 훈련한다. 대략 20분 소요된다.
for e in range(epochs):
print(f'{"":-<10}\nEpoch: {e}\n{"":-<10}')
train_loss = 0.
train_accuracy = 0.
model.train()
for batch_idx, (data, attributes) in enumerate(tqdm(train_loader)):
category = attributes['category'].to(device)
pred = model(data)
loss = criterion(pred, category.view(-1))
train_loss += loss.item()
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Compute accuracy
pred_label = torch.argmax(pred, dim=1)
train_accuracy += torch.mean((pred_label == category.view(-1)).float()).item()
print('Train loss:', train_loss / len(train_loader))
print('Train accuracy:', train_accuracy / len(train_loader))
val_loss = 0.
val_accuracy = 0.
model.eval()
with torch.no_grad():
for batch_idx, (data, attributes) in enumerate(tqdm(val_loader)):
category = attributes['category'].to(device)
pred = model(data)
loss = criterion(pred, category.view(-1))
val_loss += loss.item()
# Compute accuracy
pred_label = torch.argmax(pred, dim=1)
val_accuracy += torch.mean((pred_label == category.view(-1)).float()).item()
print('Val loss:', val_loss / len(val_loader))
print('Val accuracy:', val_accuracy / len(val_loader))
테스트 데이터에서 훈련 된 3D 물체 감지 모델을 평가한다.
test_loader = DataLoader(ModelNet(modelnet_path, categories=categories,
split='test',transform=transform),
shuffle=True, batch_size=15)
data, attr = next(iter(test_loader))
data = data.to('cuda')
labels = attr['category'].to('cuda')
preds = model(data)
pred_labels = torch.max(preds, axis=1)[1]
이전 val_loader와 동일한 데이터를 셔플링으로 로드하고, 샘플 배치 데이터를 가져온다. 다음으로, 시각화 기능을 사용하여 포인트 클라우드, 레이블 및 예측을 시각화한다. 결과는 색상으로 구분한다. 녹색은 정확하고 빨간색은 부정확하다.
from mpl_toolkits.mplot3d import Axes3D # unused import necessary to have access to 3d projection # noqa: F401
import matplotlib.pyplot as plt
%matplotlib inline
def visualize_batch(pointclouds, pred_labels, labels, categories):
batch_size = len(pointclouds)
fig = plt.figure(figsize=(8, batch_size / 2))
ncols = 5
nrows = max(1, batch_size // 5)
for idx, pc in enumerate(pointclouds):
label = categories[labels[idx].item()]
pred = categories[pred_labels[idx]]
colour = 'g' if label == pred else 'r'
pc = pc.cpu().numpy()
ax = fig.add_subplot(nrows, ncols, idx + 1, projection='3d')
ax.scatter(pc[:, 0], pc[:, 1], pc[:, 2], c=colour, s=2)
ax.axis('off')
ax.set_title('GT: {0}\nPred: {1}'.format(label, pred))
plt.show()
visualize_batch(data, pred_labels, labels, categories)
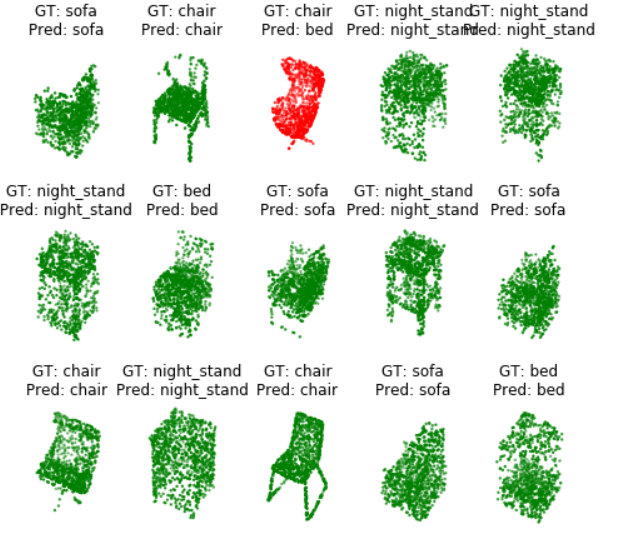
결과
Jupyter 노트북에 업로드된 전체 코드는 여기에서 찾을 수 있다. .
레퍼런스
상세한 내용은 다음 링크를 참고한다.
안녕하세요! 저는 컴퓨터과학과 1학년 대학생 입니다!
답글삭제2D이미지를 학습하여 퀄리티 높은 3DMap을 자동으로 생성 및 확장하는 프로그램을 만드는게 평생의 소원인데.. https://github.com/mapillary/OpenSfM 이 오픈소스를 공부하고자 하는데 괜찮은 선택일까요?? 답변해주시면 정말 정말로 감사하겠습니다!!
SfM는 여러가지 종류가 있습니다. 제 블로그 중에 SfM 예제있으니 참고 바랍니다.
삭제https://daddynkidsmakers.blogspot.com/2019/11/2-3-sfm-openmvg.html
기타, 프로그램은 아래 링크 참고하세요.
https://sites.google.com/site/bimprinciple/in-the-news/bestsajincheuglyangsopeuteuweeosogae
저는 그 오픈소스의 빌딩 마지막 단계에 있는 상태입니다만, 저는 여기까지 오는데도 무려 1주나 걸렸는데 Daddy Maker님은 이것뿐만 아니라 다른 기술들도 이미 활용까지 할줄 아시는 걸 보면 저는 정말 우물안의 개구리 였다는 생각이 듭니다..ㅠㅠㅠ
답글삭제네. 원래 처음에는 다 그래요. 화이팅하시길 바랍니다.
삭제항상 좋은 자료 잘 보고 있습니다, 선배님!! 한가지 의견 여쭙고 싶은 것이 있는데요. 요즘 기존의 Geometry based SLAM 이외에 Deep learning based SLAM 방식(전체 프로세스를 딥러닝으로 돌리는 PoseNet, Depth estimation 등 일부 프로세스만 딥러닝으로 대체하는 경우)이 많이 연구되고 있습니다. 제 생각에는 아직은 Deep learning based method가 기존의 conventional method를 뛰어넘으려면 아직 해결할 문제가 많이 있다고 생각하는데, 선배님은 혹시 어떻게 생각하시는지 궁금합니다.
답글삭제vSLAM 분야에서 입니다!
삭제답글 늦었습니다. 쉽지 않은 질문입니다. SLAM은 각 장면별 일관된 키포인트를 계산하는 것이 매우 중요합니다. 그래야 매칭이 정확해 집니다. 하지만, 키포인트를 얻는 것은 노이즈, 센서별 데이터 밀도 차이, 환경 변화 등으로 다양하기 때문에 쉽지는 않죠. 지금 비전 분야에서 사용하고 있는 대부분의 방법들은 컨볼루션 기법과 관련된 딥러닝이라 해결하기 어려운 이슈만 글 남깁니다. 현재로써는 딥러닝만으로 모든 SLAM 프로세스를 대체한다는 것은 성능이나 데이터 문제 등 여러가지 고려하면 쉽지 않다고 생각합니다. 그래서, 일부 프로세스만 우선 접근하는 편이 전략적인거겠죠.
삭제