이 글은 높은 성능의 AI 에이전트 구현을 위한 Gemma3 Function call 파인튜닝 방법을 설명한다.

AI 에이전트에서 Function Call 개념
준비물
이 글은 gemma3를 이용해 function call 데이터셋을 튜닝한다. 해당 모델과 파일은 다음 링크를 참고한다.
실습 소스코드는 다음 링크를 참고한다.
모델을 사용하기 전에 google로부터 다음과 같이 사용 허가(grant)를 얻는다.

터미널에서 다음처럼 패키지 설치한다. 우분투 OS 환경을 권장한다.
pip install "torch>=2.4.0" tensorboard flash-attn
pip install git+https://github.com/huggingface/transformers@v4.49.0
pip install --upgrade datasets==3.3.2 accelerate==1.4.0 evaluate==0.4.3 bitsandbytes==0.45.3 trl==0.15.2 peft==0.14.0 protobuf==3.20.3 sentencepiece
혹시 윈도우에서 다음과 같이 에러 발생하면 긴파일명 에러가 발생한 것이다.

regedit 실행해 다음 레지스트리에서 오른쪽에서 LongPathsEnabled를 더블 클릭한 후 값(Data)을 1로 변경하고 확인한다.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem
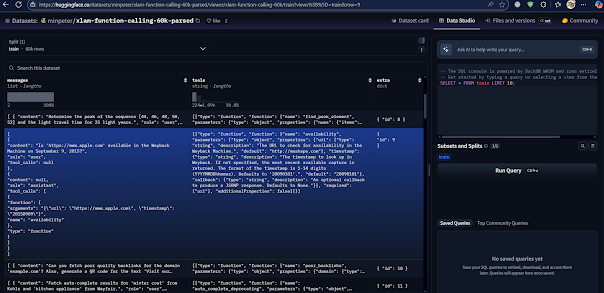
펑션콜 데이터셋 구조
다음은 펑션콜 CoT 구조 데이터셋 예시이다.
모델 튜닝 코드 구현
튜닝 코드를 다음과 같이 코딩한다. 우선, 라이브러리를 임포트한다.
import torch, json, gc, os
from transformers import AutoTokenizer, Gemma3ForConditionalGeneration, BitsAndBytesConfig, set_seed
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig, PeftModel, PeftConfig
from enum import Enum
from huggingface_hub import login
from dotenv import load_dotenv
API키, 모델 경로 등 기본 설정한다. 단, API키는 프로젝트에 .env 파일을 추가하고 HF_API_KEY=<허깅페이스 API KEY>가 내용에 포함되어 있어야 한다. 모델은 본인의 VRAM 크기를 고려해 설정한다. 참고로, 이 코드는 가장 작은 VRAM 을 사용하는 gemma-3-4b-it를 사용한다.
load_dotenv()
hf_token = os.getenv("HF_API_KEY")
login(token=hf_token)
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
seed = 42
set_seed(seed)
torch_dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "google/gemma-3-4b-it"
dataset_name = "Salesforce/xlam-function-calling-60k"
모델 튜닝 파라메터를 설정한다. attn_implementation은 트랜스포머 어텐션 연산의 성능을 개선하기 위한 옵션이다. 적절히 선택하되, 환경 상 해당 알고리즘이 동작되지 않는다면 eager 옵션을 선택한다.
model_kwargs = dict(
attn_implementation="flash_attention_2", # "eager", "sdpa", "flash_attention", "flash_attention_2"
torch_dtype=torch_dtype,
device_map="auto",
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_quant_storage=torch_dtype,
llm_int8_enable_fp32_cpu_offload=True
)
)
model = Gemma3ForConditionalGeneration.from_pretrained(model_name, **model_kwargs)
함수호출을 위한 모델 튜닝에 필요한 특수 토큰을 정의한다.
class ToolCallSpacialTokens(str, Enum):
tools = "<tools>"
eotools = "</tools>"
think = "<think>"
eothink = "</think>"
tool_call="<tool_call>"
eotool_call="</tool_call>"
tool_response="<tool_response>"
eotool_response="</tool_response>"
pad_token = "<pad>"
eos_token = "<eos>"
@classmethod
def list(cls):
return [c.value for c in cls]
tokenizer = AutoTokenizer.from_pretrained(
model_name,
pad_token=ToolCallSpacialTokens.pad_token.value,
additional_special_tokens=ToolCallSpacialTokens.list()
)
토큰 엠베딩 차원을 리사이즈한다.
tokenizer.chat_template = """{{ bos_token }}{% if messages[0]['role'] == 'system' %}{{ raise_exception('System role not supported') }}{% endif %}{% for message in messages %}{{ '<start_of_turn>' + message['role'] + '\n' + message['content'] | trim + '<end_of_turn><eos>\n' }}{% endfor %}{% if add_generation_prompt %}{{'<start_of_turn>model\n'}}{% endif %}"""
model.resize_token_embeddings(len(tokenizer))
model.to(device)
모델튜닝을 위해 학습데이터를 모델에 맞게 전처리한다.
def preprocess(sample):
try:
tools = json.loads(sample["tools"])
answers = json.loads(sample["answers"])
user_query = sample["query"]
except Exception as e:
print("Error decoding JSON:", sample)
raise e
messages = [
{
"role": "user",
"content": (
"You have access to the following tools:\n\n"
+ "\n\n".join(f"- {tool['name']}: {tool['description']}" for tool in tools)
+ "\n\nUser query:\n" + user_query
)
},
{
"role": "assistant",
"content": "\n".join(
f"<function_call>\n{json.dumps(answer)}\n</function_call>"
for answer in answers
)
}
]
return {
"text": tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
}
dataset = load_dataset(dataset_name)
dataset = dataset["train"].map(preprocess, remove_columns=["id", "query", "answers", "tools"])
dataset = dataset.train_test_split(0.1)
print(dataset)
print(dataset["train"][19]["text"])
파인튜닝을 위해 LoRA와 SFT 설정한다.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
modules_to_save=["lm_head", "embed_tokens"] # make sure to save the lm_head and embed_tokens as you train the special tokens
)
training_arguments = SFTConfig(
output_dir="gemma-3-4b-it-thinking-function_calling-V0",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=32,
save_strategy="epoch",
eval_strategy="epoch",
logging_steps=50,
learning_rate=3e-4,
max_grad_norm=0.3,
weight_decay=0.1,
warmup_ratio=0.03,
lr_scheduler_type="constant",
report_to=None,
bf16=True,
optim="paged_adamw_8bit",
torch_compile=False,
push_to_hub=False,
num_train_epochs=3,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
packing=False,
max_seq_length=512,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": True,
}
)
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
gc.collect()
학습하고 결과를 저장한다.
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
# tokenizer=tokenizer,
peft_config=peft_config,
)
trainer.train()
trainer.save_model()
정상적으로 실행되면, 다음과 같이 함수 호출 데이터셋을 학습할 것이다.

HF에 파인튜닝된 모델을 업로드한다. 그리고, 다시 다운로드하여 평가모드로 모델을 오픈한다.
trainer.push_to_hub(f'mac999/gemma-3-4b-it-thinking-function_calling-V0-{seed}', commit_message="Pushing fine-tuned model with function calling capabilities")
tokenizer.eos_token = "<eos>"
tokenizer.push_to_hub(f"mac999/", token=True)
peft_model_id = f"mac999/gemma-3-4b-it-thinking-function_calling-V0-{seed}"
device = "auto"
config = PeftConfig.from_pretrained(peft_model_id)
model = Gemma3ForConditionalGeneration.from_pretrained("google/gemma-3-4b-it",
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(peft_model_id)
model.resize_token_embeddings(len(tokenizer))
model = PeftModel.from_pretrained(model, peft_model_id)
model.to(torch.bfloat16)
model.eval()
파인튜닝이 제대로되었는 지 function call을 테스트해본다.
prompt = """<bos><start_of_turn>user
You have access to the following tools:
- numerical_derivative: Estimate the derivative of a mathematical function
User query:
I need to estimate the derivative of the function y = sin(x) at x = π/4 and x = π. Can you help with that?<end_of_turn><eos>
<start_of_turn>assistant
"""
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.01,
top_p=0.95,
repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=False)
print(response)
마무리
파인튜닝 전과 후를 비교해 보면, 확실히 데이터셋에 있는 함수호출 방식이 제대로 생성되는 것을 확인할 수 있을 것이다.
- Enhancing Gemma 3’s Capabilities with Fine-Tuning for Function Calling | by Akriti Upadhyay | May, 2025 | Medium
- General AI agent framework for smart buildings based on large language models and ReAct strategy
- Open-Source Tools for Agents | Data Science Collective
- The Era of High-Paying Tech Jobs is Over | by Somnath Singh | Level Up Coding
- AGI-Edgerunners/LLM-Agents-Papers: A repo lists papers related to LLM based agent
- APIGen - Distilabel Docs
- AymanTarig/function-calling-v0.2-with-r1-cot · Datasets at Hugging Face
- Benchmarking Agent Tool Use
댓글 없음:
댓글 쓰기