이 글은 YOLACT 기반 객체 세그먼테이션 방법을 간단히 소개한다.
머리말
YOLACT(You Only Look At CoefficienTs)은 캘리포니아 대학교 (University of California)의 연구그룹이 2019년도 발표한 실시간 객체 세그먼테이션 기술이다. 다음은 이를 이용한 객체 세그먼테이션 결과이다.


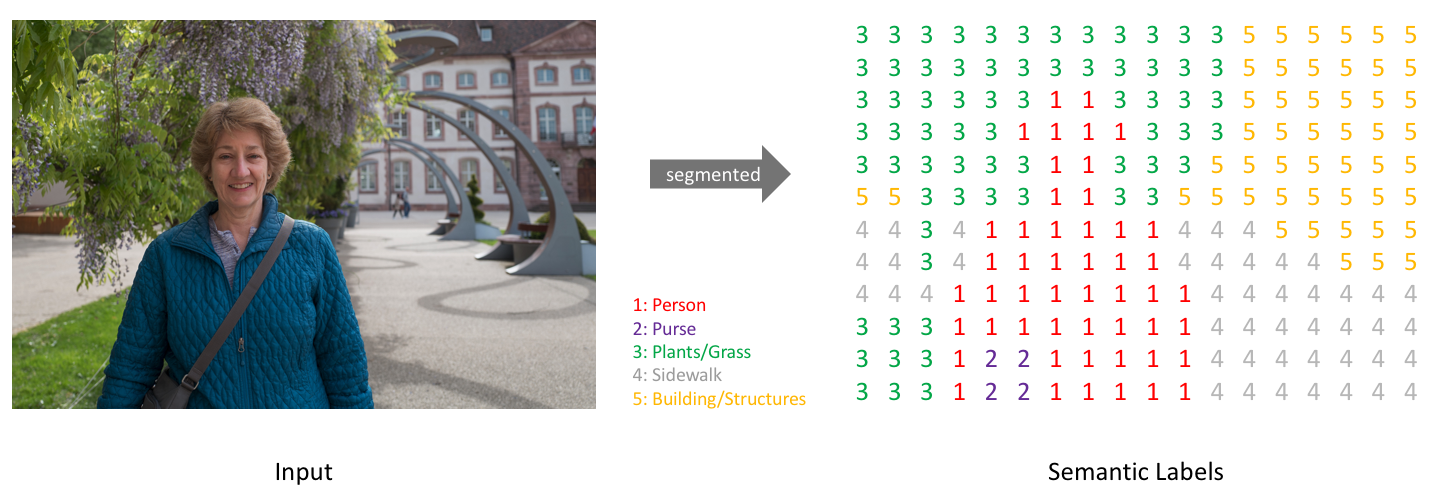
세그먼테이션을 위해서는 다음 그림과 같이 주어진 이미지 특정 객체영역 내 픽셀의 클래스를 출력으로 학습해야 한다. 이 결과 이미지의 구분된 영역을 개별 객체들로 인식할 수 있다.
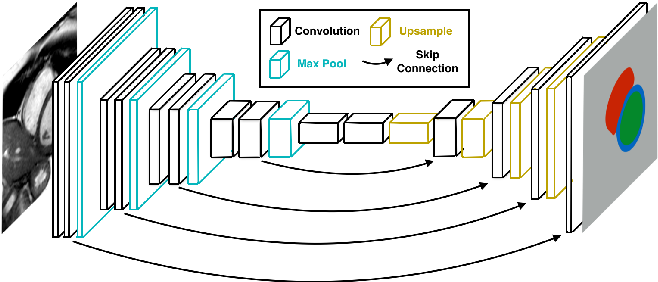
YOLACT++는 널리 알려진 물체 인식 기술인 YOLO에서 영감을 얻었으며, 실시간으로 빠르게 물체를 감지한다. DeepLab과 같이 객체 탐지와 달리 시맨틱 또는 인스턴스 세그먼테이션을 위한 대부분의 방법은 속도에 따른 성능에 중점을 두고 있다.

YOLACT가 인스턴스 세그먼테이션 문제를 해결하기 위해, 병렬로 실행되는 두 개의 작업 (프로토타입 마스크 딕셔너리 생성, 인스턴스 선형조합세트 예측)을 구분해 학습을 수행한다. 이를 통해 계산 시간을 크게 줄일 수 있다. YOLACT 모델은 ResNet50 모델에서 33.5 fps, 34.1 mAP로 높은 정확도와 예측 속도를 지원한다.
머리말
YOLACT(You Only Look At CoefficienTs)은 캘리포니아 대학교 (University of California)의 연구그룹이 2019년도 발표한 실시간 객체 세그먼테이션 기술이다. 다음은 이를 이용한 객체 세그먼테이션 결과이다.
YOLACT


YOLACT 예측 테스트
세그먼테이션을 위해서는 다음 그림과 같이 주어진 이미지 특정 객체영역 내 픽셀의 클래스를 출력으로 학습해야 한다. 이 결과 이미지의 구분된 영역을 개별 객체들로 인식할 수 있다.
YOLACT++는 널리 알려진 물체 인식 기술인 YOLO에서 영감을 얻었으며, 실시간으로 빠르게 물체를 감지한다. DeepLab과 같이 객체 탐지와 달리 시맨틱 또는 인스턴스 세그먼테이션을 위한 대부분의 방법은 속도에 따른 성능에 중점을 두고 있다.

YOLACT가 인스턴스 세그먼테이션 문제를 해결하기 위해, 병렬로 실행되는 두 개의 작업 (프로토타입 마스크 딕셔너리 생성, 인스턴스 선형조합세트 예측)을 구분해 학습을 수행한다. 이를 통해 계산 시간을 크게 줄일 수 있다. YOLACT 모델은 ResNet50 모델에서 33.5 fps, 34.1 mAP로 높은 정확도와 예측 속도를 지원한다.

주요 객체 세그먼테이션 딥러닝 모델 성능(AP=Average Precision. FPS=Frame Per Second. NMS=Non-Maximum Suppression)
YOLACT 사용 방법
YOLACT 사용을 위해서는 미리 다음과 같은 개발환경이 구축되어 있어야 한다. 개발환경 구축은 많은 시행착오가 필요하다. 딥러닝 개발환경 구축과 관련해 이전 글 #1, #2, #3, #4을 참고 바란다.- 우분투 18.04 버전 이상
- NVIDIA GPU 드라이버 및 CUDA 10 버전 이상
- 아나콘다 개발 환경
- PyTorch
YOLACT 소스를 다운받고 빌드해야 한다. 다음 명령을 입력한다.
git clone https://github.com/dbolya/yolact.git
cd yolact
cd yolact
conda env create -f environment.yml
만약 기존 아나콘다 환경을 보관하고 싶을 경우, 다음과 같이 환경을 복사해 이름을 변경해 놓는다.
conda create --name new_name --clone old_name
conda remove --name old_name --all
만약 기존 아나콘다 환경을 보관하고 싶을 경우, 다음과 같이 환경을 복사해 이름을 변경해 놓는다.
conda create --name new_name --clone old_name
conda remove --name old_name --all
학습 데이터셋은 다음과 같이 다운받을 수 있다.
sh data/scripts/COCO.sh
sh data/scripts/COCO_test.sh
DCN(Deformable Convolutional Networks)을 사용하려면 다음을 실행한다.
cd external/DCNv2
python setup.py build develop
YOLACT 사용을 위해 딥러닝 훈련된 모델을 다운로드 받는다.
| Image Size | Backbone | FPS | mAP | Weights | |
|---|---|---|---|---|---|
| 550 | Resnet50-FPN | 42.5 | 28.2 | yolact_resnet50_54_800000.pth | Mirror |
| 550 | Darknet53-FPN | 40.0 | 28.7 | yolact_darknet53_54_800000.pth | Mirror |
| 550 | Resnet101-FPN | 33.5 | 29.8 | yolact_base_54_800000.pth | Mirror |
| 700 | Resnet101-FPN | 23.6 | 31.2 | yolact_im700_54_800000.pth | Mirror |
다음 명령을 통해 데이터셋을 학습한다. batch_size 하나당 1.5GB GPU 메모리가 필요하고, 이 크기가 클수록 빠른 속도로 훈련이 가능하다. nvidia-smi 명령을 통해 GPU 메모리 크기를 확인하고 이 숫자를 정하자. 세그먼테이션 데이터 훈련을 위해서는 최소 4GB 이상 GPU 카드가 필요하다. 이 이하는 학습 속도나 품질에 문제가 있다.
python train.py --config=yolact_base_config --resume=weights/yolact_base_54_800000.pth --start_iter=-1 --batch_size=7
참고로, 세그면테이션 데이터 훈련 시간은 기존 객체 인식 훈련에 비해 매우 오래 걸린다. 164,000개의 이미지를 가지고 있는 COCO의 세그먼테이션 데이터의 경우, 전이학습을 사용하지 않으면, 일주일이상이 걸릴 수 있다. 이 경우에는 딥러닝 데이터 모델 훈련에 대략 이틀이 걸렸다.

nvidia-smi 확인



훈련 진행 및 완료

세그먼테이션 데이터 훈련 결과
다음 명령을 실행해 훈련된 모델의 성능 평가를 해본다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth

이제 아래와 같이 평가 테스트를 실행해 보자.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --output_coco_json
python run_coco_eval.py
python eval.py --trained_model=weights/yolact_base_54_800000.pth --output_coco_json --dataset=coco2017_testdev_dataset
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --image=my_image.png
세그먼테이션 실행 결과
다음 명령으로 이미지에서 객체 세그먼테이션을 해본다.python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --image=input_image.png:output_image.png
특정 폴더 내 이미지를 세그먼테이션하려면 아래 명령을 입력한다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --images=path/to/input/folder:path/to/output/folder
다음은 이미지 세그먼테이션 결과이다.


다음 명령으로 비디오 내 객체 세그먼테이션을 처리해 본다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=my_video.mp4




웹캡은 다음 명령으로 처리할 수 있다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=0
웹캡에서 처리된 객체 세그먼테이션 결과는 다음 명령으로 영상 저장이 가능하다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=input_video.mp4:output_video.mp4
YOLACT 기반 객체 세그먼테이션 처리 영상
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=my_video.mp4

다음과 같이 비디오 이미지도 객체 세그먼테이션이 잘 실행된다. 다만, 일부 객체들이 사람이나 보트같은 것으로 구분되는 문제가 있다. 이는 전이학습을 통해 해결할 수 있어 보인다.




웹캡은 다음 명령으로 처리할 수 있다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=0
웹캡에서 처리된 객체 세그먼테이션 결과는 다음 명령으로 영상 저장이 가능하다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=input_video.mp4:output_video.mp4
다음은 건설 객체가 얼마나 잘 인식되는 지 확인해본 YOLACT 실행 영상이다.
건설 객체의 세그먼트를 학습하지 않은 상태이므로, 오탐되는 경우가 발생한다. 앞서 언급했듯이 학습 데이터를 확보해 진행하면, 해당 이슈는 해결할 수 있다. 하지만, 세그먼테이션을 위해 학습 데이터를 확보하고 라벨링하는 것이 쉽지 않은 문제가 있다. 라벨링 방법은 다음 링크를 참고한다.
마무리
지금까지 YOLACT 모델을 이용한 객체 세그먼테이션 방법을 소개하고, 이를 이용해 이미지, 비디오 등에서 객체를 세그먼테이션해 보았다. 세그먼테이션은 다른 딥러닝 모델에 비해 많은 정보를 담고 있어 유용하다.
다만, 세그먼테이션은 클래스 분류, 객체 탐지에 비해 많은 계산 비용과 학습 노력이 필요하다. 학습을 위해서는 고사양의 GPU가 장착된 컴퓨터가 필요하며, 데이터셋 구축도 많은 노력이 필요하다. 실행 속도도 상대적으로 느리므로, 특정 영역경계를 정확히 찾아내야 하는 문제가 아니라면, 단순히 분류하거나 객체 탐지할 때 굳이 사용할 필요는 없을 것이다.
Reference
댓글 없음:
댓글 쓰기