이 글은 Stable Diffusion개념과 생성(Generative) AI 오픈소스 도구 설치, 사용 방법을 간략히 나눔한다. 우선, Stable Diffusion, ControlNet 기술의 동작 개념을 설명한다. 그리고, 오픈소스 ComfyUI 등 도구를 소개하고, 사용법을 예시한다. 아울러, civitai.com(Stable Diffusion AI Art models 공유 웹사이트)에서 다양한 이미지 스타일로 학습된 Stable Diffusion 모델 다운로드 방법 등을 나눔한다.
참고로, 이 글에서 본인은 충실한 집사로써, 불건전한? 이미지 생성 낚시 보다는 귀여운 캣ㅎ 이미지 생성에 집중합니다. - Cat using ChatGPT
Stable Diffusion개념
Stable Diffusion(스테이블 디퓨전)은 Stability AI와 Runway도구의 협업으로 개발된 생성 AI 모델이다. 이 모델은 OMMER Lab의 도움을 많이 받아 개발되었다. Stable Diffusion의 원래 이름은 LDM(Latent Diffusion Model)이었다.
Stable Diffusion은 text to image diffusion을 지원한다.

Stable Diffusion 기반 생성 AI 예시

OMMER Lab 연구 내용

Diffusion의 UNet 구조
여기에 모델의 역방향(Reverse Diffusion Process)으로, text encoding 벡터를 입력해, 원하는 스타일의 이미지를 생성하기 위해, 임의의 노이즈인 Random Latent Noise(zT)와 디노이즈 가중치 레이어인 Denoised Latent(Z0)를 UNet 모델 사이에 삽입한다(다음 그림 참고).

이를 통해, 텍스트 프롬프트는 아래와 같은 과정을 거쳐 이미지를 생성한다.
Input text prompt > Text embedding + Time step + Random latent noise > Diffusion > Denoised latent
이 결과로, T 시행이 많을 수록 다음과 같이 유사한 입력 이미지가 되도록 한다.

이를 다 종합하면, 다음과 같은 딥러닝 모델 구조가 완성된다. 이제 모델의 각 파라메터를 조정하면, 텍스트 입력에 대한 다양한 스타일의 학습 가중치를 조정하게 되고, 이를 통해, 원하는 이미지를 생성할 수 있다.
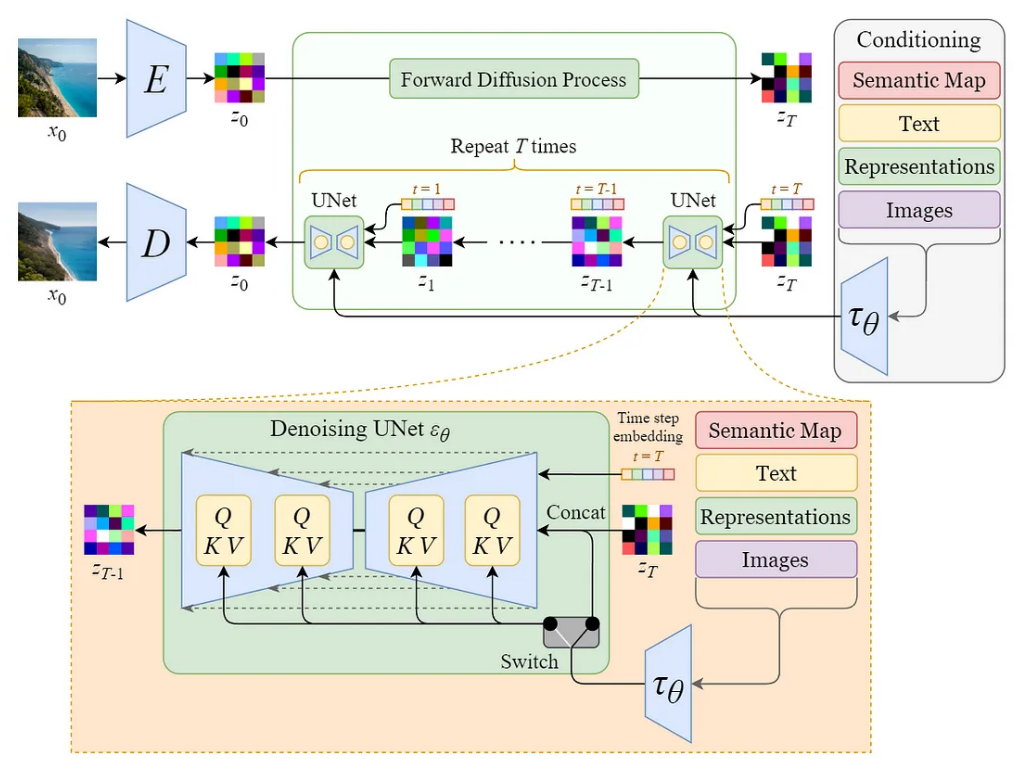
Stable Diffusion Model
ControlNet은 Stable Diffusion 생성 AI 모델에 추가적인 조건을 부여해 좀 더 다양한 이미지를 생성하는 신경망 딥러닝 모델이다.

ControlNet = Stable Diffusion 조건 추가 모델
Stable Diffusion 모델은 text prompt, time encoder, encoder-decoder 모델을 연결한 이미지 생성 모델이다. 여기에 ControlNet을 포함하면 다음과 같다.
.png)
결론적으로 ControlNet은 조건을 설정할 수 있는 conv net을 추가함으로써, 각 encoder, decoder 레이어의 스타일(특징 가중치)을 세부 조정할 수 있다.

손쉬운 생성AI 도구 ComfyUI 설치해 보기
여기서는 ControlNet을 직접 사용하기 보다는 이를 좀더 편리하게 사용할 수 있는 ComfyUI를 통해 생성AI 도구를 설치해 보겠다. 이 도구는 다음 기능을 제공한다(참고).
- 노드/그래프/흐름도 인터페이스를 통해 코딩할 필요 없이 이미지 생성 가능
- 메모리 최적화. --lowvram을 사용하면 3GB 미만 vram을 가진 GPU에서도 작동
- 학습모델 파일포맷인 ckpt, 세이프텐서(safetensors) 모델 모두 로드할 수 있음
- 로라(일반 및 로콘) 모델 지원. 고급 모델(ESRGAN, ESRGAN, SwinIR, Swin2SR 등) 지원
만약, ControlNet을 직접 설치해 사용하려면, 아래 링크를 참고 바란다.
ComfyUI는 Stable Diffusion 학습모델파일을 로딩해, 스타일을 GUI방식으로 손쉽게 설정하고, 이미지를 생성할 수 있도록 만든 도구이다. 터미널에서 다음 명령을 실행한다.
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 xformers
pip install -r requirements.txt
사용해 보기
설치 후 다음과 같이 실행한다.
python main.py
그럼 다음과 같이 웹 기반 그래프 노드 로직 디자인이 가능한 창이 표시된다.

이제, 다음과 같이 적절한 Stable Diffusion 학습 모델 파일, 텍스트 프롬프트 및 파라메터를 입력해, 다양한 스타일의 이미지를 생성해 본다. 이 경우, 눈이 파란색인 골드 태비 고양이를 생성해보았다(참고로, 실제 파란색 눈 골드 태비는 본적이 없음)
프롭프트 예. Realistic cute cat sitting on soft sofa, with blue eyes and brown stripes

프롬프트 및 파라메터 설정

이미지 생성 결과
프롭프트와 파라메터를 수정해 보면, 다음과 같이 자연스럽고 다양한 이미지를 자동 생성할 수 있다.




다음과 같이, 예술적인 스타일로 이미지를 생성하는 것도 그리 어렵지 않다.


참고로, Stable Diffusion 학습모델 파일은 civitai.com 과 같은 곳에서 손쉽게 다운로드 받을 수 있다. 이를 이용해, 원하는 이미지 스타일을 프롬프트로 쉽게 생성할 수 있다.


civitai.com, Stable Diffusion AI Art models
civitai.com 방문 후 원하는 스타일 이미지의 학습모델은 다운로드 버튼으로 저장받을 수 있다. 지원되는 모델 포맷은 safetensors 등이다.

ComfyUI에서 이 학습모델파일을 선택한 후, 프롬프트로 이미지를 생성할 수 있다.
마무리
여기서는 생성 AI 오픈소스 딥러닝 모델인 Stable Diffusion, ControlNet 개념을 살펴보고, 이를 편리하게 사용할 수 있는 도구인 ComfyUI를 설치해, 사용하는 방법을 알아보았다. 이런 도구들은 디자인 분야에서 급속히 확산되고 있다. 이런 멀티모달(다양한 입력 - 출력) 딥러닝 모델은 GPT4와 같이 구현되고, 많은 분야에 적용될 것이다.
ChatGPT를 사용한 생성AI 프로그램 개발 방법은 다음 링크를 참고한다.
레퍼런스
- Hugging Face Stable Diffusion demo
- Adding Conditional Control to Text-to-Image Diffusion Models
- UForm multi-modal network
- ComfyUI
- ControlNet CoLab
- Stable Diffusion Clearly Explain
- civitai.com, Stable Diffusion AI Art models
- How to Run Stable Diffusion: A Tutorial on Generative AI | DataCamp
- How to Install Stable Diffusion on Windows: A Complete Guide (ambcrypto.com)
- LoRA (Low-Rank Adaptation) 및 Hypernetwork 사용방법
댓글 없음:
댓글 쓰기