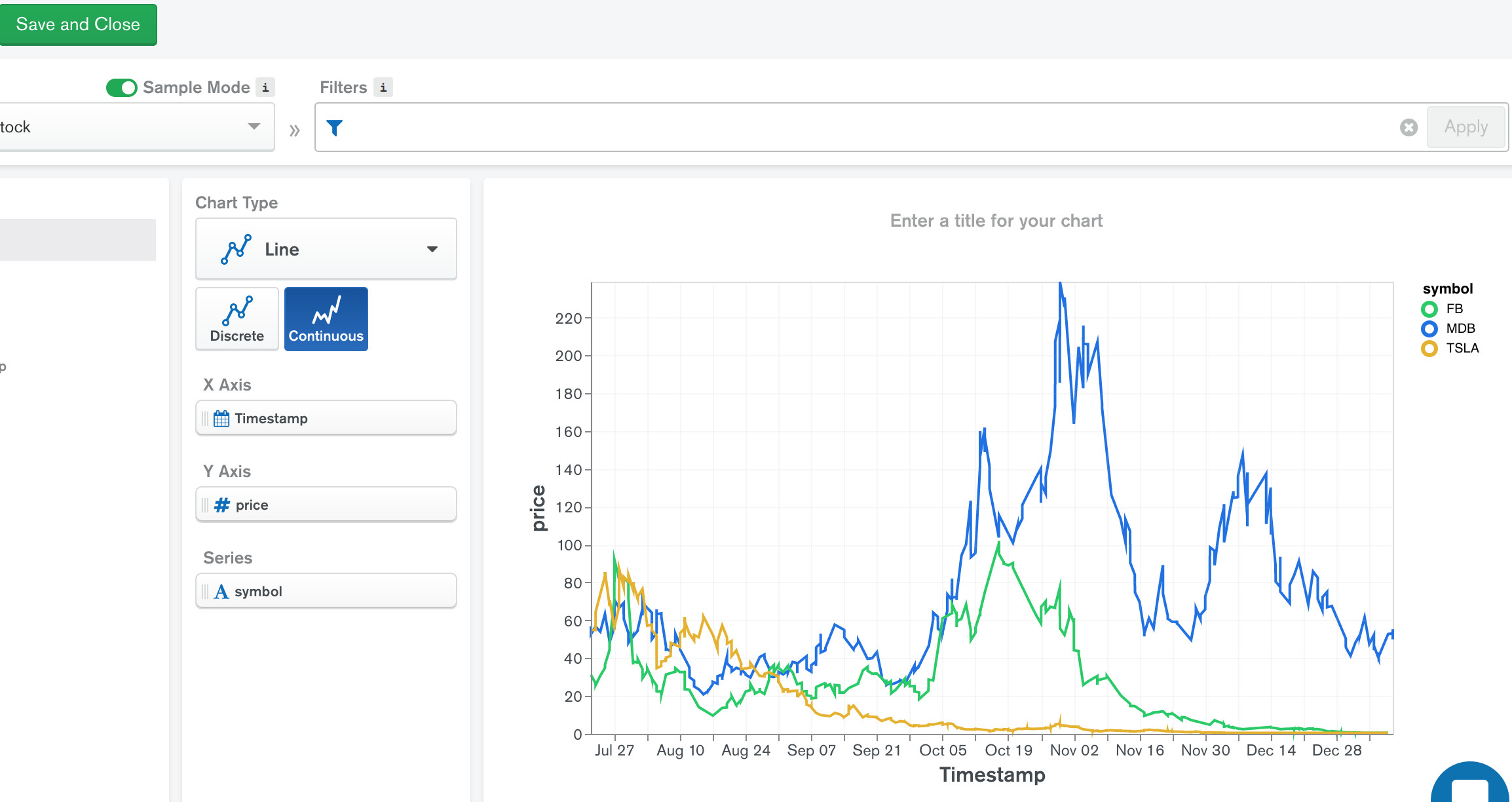
이 글은 가성비 있는 웹 서비스 호스팅이 가능한 Fly.IO 사용방법을 정리한다. 이 글은 다음 글의 후속편으로, DNA, 호스팅 등 개념은 이 글을 참고하길 바란다.
머리말
FLY.IO는 Kurt Mackey가 공동 설립한 회사로 개발되었다. 그는 이전에 Compose.io라는 데이터베이스 호스팅 플랫폼을 공동 창업했으며, 이를 IBM에 매각한 경험이 있다. FLY.IO는 주로 개발자 친화적인 글로벌 애플리케이션 호스팅 서비스를 제공하기 위해 설립되었다.
FLY.IO의 장단점은 다음과 같다.
장점
1. 글로벌 배포: 애플리케이션을 여러 지역에 쉽게 배포할 수 있어 지리적으로 분산된 사용자에게 낮은 지연 시간을 제공한다.
2. 간단한 사용성: 간단한 명령어로 애플리케이션을 배포할 수 있으며, 설정도 비교적 쉬운 편이다.
3. 자동 확장: 필요에 따라 인프라를 자동으로 확장할 수 있어, 트래픽이 급증할 때도 유연하게 대응 가능하다.
4. 애플리케이션 근접 배치: 사용자 근처에 애플리케이션을 배치할 수 있어 성능 향상과 지연 시간 감소에 효과적이다.
5. 무료 계층 제공: 제한적이지만 무료로 사용할 수 있는 계층을 제공해, 작은 프로젝트나 테스트에 유용하다. 평소에는 배포 앱이 비활성화되었다가 URL 접속하면 자동 활성화되는 Pay As You Go Plan (기존 Hobby Plan) 을 지원한다.
단점
1. 제한된 문서화: 다른 클라우드 서비스에 비해 문서화가 부족한 편이며, 일부 기능에 대한 정보가 불충분할 수 있다.
2. 복잡한 설정: 고급 기능을 사용할 때 설정이 복잡해질 수 있으며, 초보자에게는 어려울 수 있다.
3. 비교적 작은 생태계: AWS나 Google Cloud와 비교하면 생태계가 작아, 지원되는 서비스나 도구가 제한적이다.
4. 무료 계층 한계: 무료 계층의 자원이 제한적이므로, 트래픽이 많은 애플리케이션에는 적합하지 않다.
5. 서비스 안정성: 일부 사용자들은 특정 상황에서 예기치 않은 중단을 경험할 수 있다고 보고했다.
환경 설치
2. 파워셀에서 설치 스크립트 실행
pwsh -Command "iwr https://fly.io/install.ps1 -useb | iex"
3. 터미널에서 로그인 실행
fly auth login
로그인 결과는 다음과 같다.


소스코드에서 데모앱 빌드, 배포 및 실행
FLY.IO에서 제공하는 데모앱을 간단히 실행해 보자.
다음 예제를 터미널에서 실행한다.
cd hello-fly

코드 예시
앱을 배포하고 실행한다.
fly launch --now
그 결과, 도커를 자동 빌드한다. 다음은 이미지 스크립트이다.
FROM node:16.19.0-slim
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 8080
CMD [ "npm", "start" ]
도커 이미지는 자동으로 FLY.IO 클라우드에 업로드되고, 설정파일대로 웹 인터페이스를 연결한다.

도커 이미지 생성 화면

Fly.IO의 웹 앱 배포된 모습
결과는 다음과 같다. 웹 앱이 정상 서비스된 것을 확인할 수 있다.

이미 개발된 도커 이미지에서 데모앱 빌드, 배포 및 실행
Fly Launch를 사용해 도커 이미지로 앱을 배포할 수 있다. 미리 빌드된 Docker이미지를 이용해 데모앱을 만들고 배포해 본다.
도커가 설치되었다는 가정 하에 다음 명령을 실행한다.
fly launch --image flyio/hellofly:latest
fly launch

이 결과 fly.toml 설정파일이 생성된다. 참고로, 웹 인터페이스는 다음과 같은 fly.toml 구성파일을 통해 설정된다.
app = 'fly-io-delicate-surf-7133'
primary_region = 'nrt'
[http_service]
internal_port = 8080
force_https = true
auto_stop_machines = 'stop'
auto_start_machines = true
min_machines_running = 0
processes = ['app']
[[vm]]
memory = '1gb'
cpu_kind = 'shared'
cpus = 1
앱을 배포한 후 상태를 확인한다.

fly apps open /fred
그럼, 다음 웹 페이지를 확인할 수 있다.


변경사항 배포 예
index 파일을 다음과 같이 수정한 후 fly deploy 명령을 실행한다.


원격 터미널 접속
Fly.IO는 SSH 터미널 접속을 제공한다. 다음과 같이, SSH 키를 생성한다.
ssh-keygen -t rsa -b 4096 -C "your email@gmail.com"
그럼. id_rsa 암호키가 생성될 것이다.

fly ssh console

결론
Kurt Mackey는 소프트웨어 엔지니어이자 창업가로, 클라우드 인프라와 개발자 도구 분야에서 주목받는 인물이다. 그는 여러 기술 회사에서 경력을 쌓아왔고, Compose.io 등 두 개의 성공적인 스타트업을 공동 창업했다. 2015년, IBM이 Compose.io를 인수하면서 Mackey는 IBM에서 기술 리더십 역할을 맡았다.
Mackey는 오랜 시간 소프트웨어 엔지니어로 활동해왔으며, 주로 인프라 서비스와 클라우드 컴퓨팅에 대한 깊은 전문성을 보유하고 있다. 그의 작업 철학은 개발자가 인프라 관리에 신경 쓰지 않고도 효율적으로 작업할 수 있도록 도와주는 도구와 플랫폼을 제공하는 데 중점을 두고 있다.
Kurt Mackey는 기술 커뮤니티 내에서 활발하게 활동하며, 개발자 도구의 발전과 클라우드 기반 서비스의 미래에 대해 꾸준히 발언하고 있다. 그의 비전은 애플리케이션이 물리적 서버나 데이터 센터에 묶이지 않고, 사용자 근처에서 자동으로 최적화되고 배포될 수 있는 환경을 조성하는 것이다.

부록: Gradio web app의 Fly.toml 설정 예시
# fly.toml app configuration file generated for bim-data-quality-checker-solitary-wave-2365 on 2025-01-28T22:16:55+09:00
#
# See https://fly.io/docs/reference/configuration/ for information about how to use this file.
#
app = 'bim-data-quality-checker-solitary-wave-2365'
primary_region = 'nrt'
[build]
# Use the Dockerfile in the current directory
dockerfile = "./Dockerfile"
[env]
PYTHONUNBUFFERED = "1" # Ensure logs are shown in
[deploy]
release_command = "echo Deploying Gradio app on Fly.io!"
command = ["python", "./src/app.py"]
[[vm]]
memory = '1gb'
cpu_kind = 'shared'
cpus = 1
[[services]]
internal_port = 7860 # Default Gradio app port
protocol = "tcp"
[[services.ports]]
handlers = ["http"]
port = 80 # HTTP port
[[services.ports]]
handlers = ["tls", "http"]
port = 443 # HTTPS port
[[services.tcp_checks]]
interval = "15s"
timeout = "2s"
grace_period = "5s"
restart_limit = 0
부록: Gradio web app의 Dockerfile 예시
# https://www.gradio.app/main/guides/deploying-gradio-with-docker
# Use a base image with Python
FROM python:3.10-slim
# Set the working directory in the container
WORKDIR /app
# Copy the project files to the container
COPY ./src /app/src
COPY requirements.txt /app
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Expose the port your app will run on (e.g., 7860 for Gradio)
EXPOS
E 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
# Set the command to run your app when the container starts
CMD ["python", "./src/app.py"]
레퍼런스
- Launch a demo app · Fly Docs
- Dashboard · Fly
- fly-apps/hello-django: Example project demonstrating how to deploy a Django app to Fly.io
- Stripe | Financial Infrastructure to Grow Your Revenue
- Stripe 결제 시스템
- Launch Your Startup in Days, Not Weeks | ShipFast
- GPUs are generally available! - Fresh Produce - Fly.io
- Simple Pricing | Machine Learning Infrastructure | Deep Infra