이 글은 NVIDIA DGX Spark(GB10, ARM64) 장비에 Isaac Sim과 Isaac Lab을 설치하고, 로봇 시뮬레이션과 강화학습까지 실행해 본 개발환경 구축기를 간단히 나눔한다. 요즘 피지컬 AI가 화두인데, 시뮬레이션에서 로봇 정책을 학습해 실물에 이식하는 sim-to-real 워크플로 실행 환경을 세팅해 보고 간단한 예제를 실행해 본다. 참고로, DGX Spark는 ARM 기반 Grace CPU와 Blackwell GPU가 통합 메모리를 공유하는 독특한 구조라서, 설치 과정에 x86 장비와는 다른 함정이 몇 군데 있었다. 이 글에서 해당 부분을 함께 정리한다.
개요
Isaac Sim은 NVIDIA Omniverse 기반의 로봇 시뮬레이터로, USD(Universal Scene Description)를 네이티브 씬 포맷으로 사용한다. RTX 레이트레이싱 렌더링, PhysX 물리엔진, 카메라 및 LiDAR 같은 합성 센서 시뮬레이션을 제공한다. Isaac Lab은 그 위에 구축된 로봇 학습 프레임워크로, GPU에서 수천 개 환경을 병렬로 돌려 강화학습(PPO 등)과 모방학습을 수행한다.

설치 대상 환경은 다음과 같다.
- 장비: NVIDIA DGX Spark (GB10, ARM64/aarch64, 통합 메모리 121GB)
- OS: Ubuntu 24.04 (DGX OS), 드라이버 580.159.03, CUDA 13.0
- Isaac Sim 6.0.1, Isaac Lab 3.0.0b2, PyTorch 2.11 (cu130)
Isaac Sim의 ARM64(aarch64) 빌드는 현재 DGX Spark에서 공식 지원되며, 드라이버는 580.159.03이 권장 버전이다. 더 최신인 R590 계열 드라이버에서는 RTX 렌더러가 크래시하는 이슈가 보고되어 있으므로 드라이버 버전을 먼저 확인하는 것이 좋다.
1단계. 파이썬 환경 준비
Isaac Sim 6.x는 파이썬 3.12용 pip 패키지(cp312, manylinux_2_35_aarch64 휠)를 제공한다. 처음에는 시스템 python3.12로 가상환경인 venv를 만들었다. 본인의 경우, 설치 중 psutil과 PyOpenGL-accelerate가 소스 빌드되면서 Python.h 헤더가 없다는 에러로 실패했다. python3.12-dev를 apt로 설치하면 되지만 sudo 권한이 필요한 상황이었고, 대신 conda(miniforge)의 파이썬을 쓰면 개발 헤더가 자체 포함되어 있어 시스템 패키지 없이 해결된다. 가상환경은 터미널에서 다음과 같이 생성한다.
conda create -n venv_sim -y python=3.12
conda activate venv_sim
2단계. PyTorch와 Isaac Sim 설치
DGX Spark는 CUDA 13 환경이므로 cu130 빌드의 PyTorch를 먼저 설치하고, 이어서 Isaac Sim 전체 패키지를 설치한다.
pip install -U torch==2.11.0 --index-url https://download.pytorch.org/whl/cu130
pip install "isaacsim[all,extscache]==6.0.1.0" --extra-index-url https://pypi.nvidia.com
다운로드 용량이 수 GB라서 시간이 좀 걸린다. 설치 후 실행 전에 환경변수 두 개를 설정해야 한다. EULA 동의와, aarch64에서 필수인 OpenMP 라이브러리 프리로드이다. 특히 두 번째 것을 빼먹으면 공유 라이브러리 로드 순서 문제로 실행이 그냥 종료되므로 주의한다.
export OMNI_KIT_ACCEPT_EULA=YES
export LD_PRELOAD=/lib/aarch64-linux-gnu/libgomp.so.1
3단계. 실행 확인
먼저 헤드리스 모드로 SimulationApp을 띄워 USD 스테이지 생성과 프레임 스텝이 정상 동작하는지 확인한다.
GB10 GPU가 Vulkan 백엔드로 인식되고, 93GB의 GPU 가용 메모리가 잡히는 것을 볼 수 있었다. 이어서 GUI 모드를 실행하면 첫 구동 시 셰이더 컴파일 때문에 수 분이 걸리는데, 완료되면 RTX 실시간 렌더링 뷰포트가 110 FPS 내외로 부드럽게 돌아간다.
isaacsim # GUI 실행
Isaac Sim 6.0.1 GUI 첫 실행 화면. RTX 뷰포트가 112 FPS로 렌더링되고 있다
4단계. 로봇 데모 실행
환경이 잡혔으니 로봇을 움직여 봤다. Isaac Sim 6.0부터는 사전학습된 강화학습 정책 예제가 isaacsim.robot.policy.examples 모듈로 제공된다.
상단 메뉴 바의 Isaac Examples > Robots > Quadrupeds > Spot RL Policy를 선택하면 Boston Dynamics Spot 4족보행 로봇이 창고 환경에 자동으로 스폰된다. 이어서 우측 Property 패널에서 학습된 보행 정책(SpotFlatTerrainPolicy)을 확인한 뒤, 좌측의 Play 버튼을 누르고 Robot Controller UI를 통해 속도 명령(Velocity Command)을 주면 로봇이 실제로 걸어 다닌다.
로봇 애셋과 정책 체크포인트는 NVIDIA 클라우드에서 자동으로 스트리밍되므로 별도의 대용량 파일 다운로드 없이 바로 테스트해 볼 수 있다
한 가지 주의할 점은 API 변화이다. 6.0에서는 정책 명령을 numpy 배열이 아닌 torch 텐서로 넘겨야 하고, 구버전 예제 모듈(omni.isaac.* 계열)은 상당수 제거되었다. 구버전 튜토리얼 코드를 그대로 쓰면 에러가 나므로 모듈 경로를 확인해야 한다.
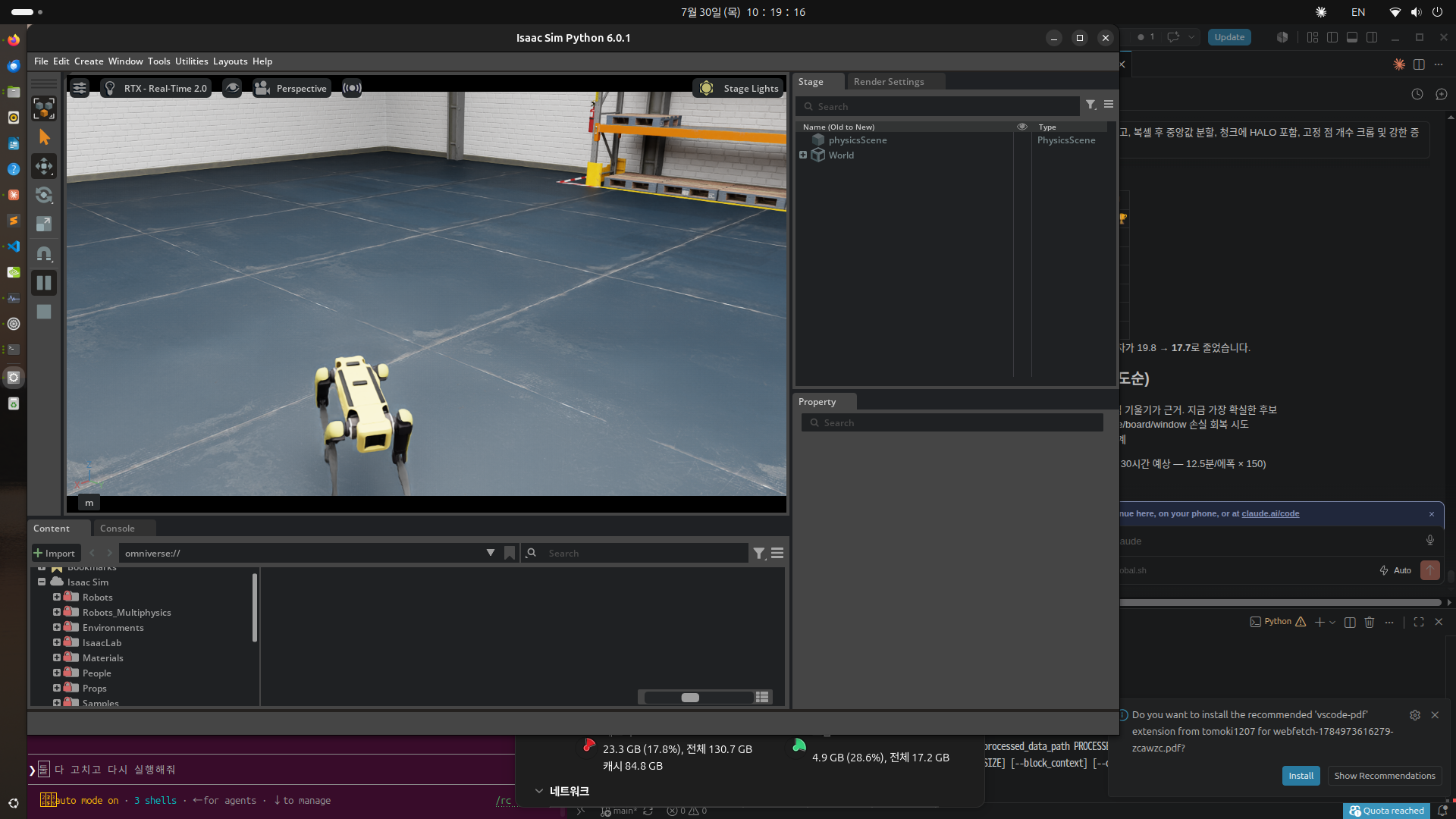
창고 환경에서 강화학습 정책으로 보행 중인 Spot 로봇
여기에 센서와 데이터 수집 파이프라인을 연결해 봤다. 상단 메뉴의 Create > Sensors 항목에서 Camera와 RTX LiDAR를 로봇 몸체에 부착한 뒤, Isaac Tools > Synthetic Data Recorder 패널을 열어 저장할 데이터를 설정한다. 이어서 시뮬레이션을 재생하고 Start Recording 버튼을 누르면 로봇이 걸어 다니는 동안 RGB 영상, 뎁스맵, 프레임당 약 44만 포인트의 LiDAR 포인트클라우드가 자동으로 추출되어 저장된다. 이렇게 쌓인 정밀한 센서 데이터가 바로 객체 인식 및 자율주행 모델 학습용 합성 데이터셋의 핵심 재료가 된다.
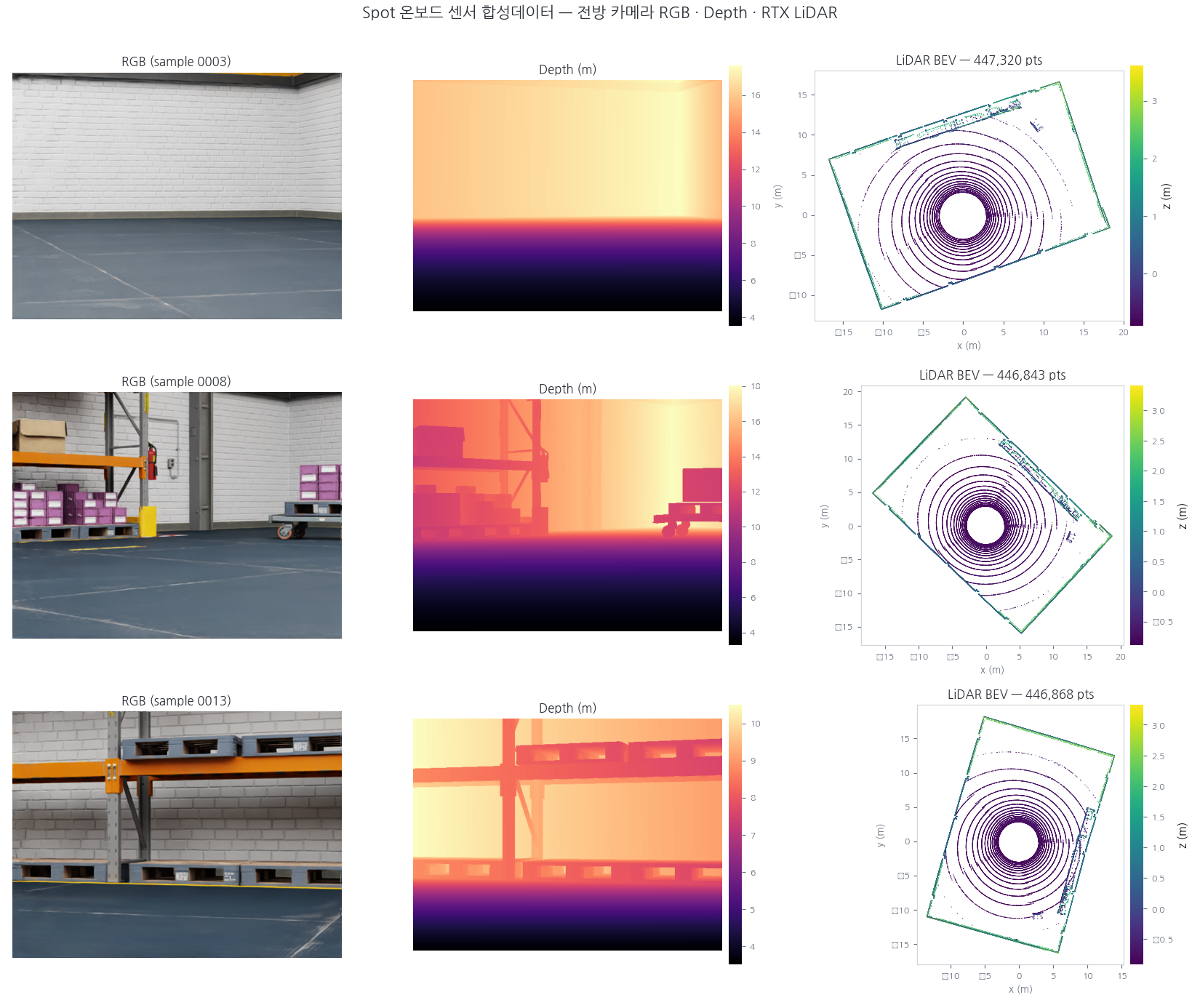
Spot 온보드 센서로 수집한 RGB, 뎁스, LiDAR 데이터
5단계. Isaac Lab 설치와 강화학습
이제 직접 정책을 학습할 차례이다. Isaac Lab은 pip로 설치할 수 있는데, Isaac Sim 6.0에 대응하는 버전은 3.0.0b2 계열이다. 학습 스크립트는 pip 패키지에 포함되지 않으므로 저장소를 따로 클론한다.
pip install "isaaclab[all]==3.0.0b2.post1" --extra-index-url https://pypi.nvidia.com
git clone --depth 1 https://github.com/isaac-sim/IsaacLab.git
ANYmal-D 4족보행 로봇의 속도 추종 태스크를 PPO로 학습시켜 봤다. 터미널에서 train.py 스크립트를 실행해 --num_envs 2048 인자로 2048개 환경을 GPU에서 병렬로 돌렸다.
python scripts/reinforcement_learning/rsl_rl/train.py \
--task Isaac-Velocity-Flat-Anymal-D-v0 --headless --num_envs 4096 --max_iterations 500
순수 학습 시간 기준으로 100 iteration이 약 1분 35초밖에 걸리지 않았다. 이어서 --num_envs 4096으로 인자를 변경하여 환경 수를 4096개로 올려봐도, 통합 메모리 덕분에 VRAM 부족(OOM) 걱정 없이 대규모 강화학습을 안정적으로 진행할 수 있었다. 결과 로그는 TensorBoard / Console Log 에서 확인한다.
학습 곡선을 보면 강화학습의 전형적인 패턴이 그대로 나타난다. 초반에는 로봇들이 명령 추종을 시도하다가 넘어지면서 보상이 급락하고, 넘어지지 않는 법을 터득한 뒤 회복하며, 이후 명령 추종 정밀도를 다듬으면서 완만히 상승한다. 500 iteration(약 8분) 학습 후 평균 보상 22.7, 속도 추종 오차는 정상 상태 기준 0.1 m/s 수준까지 내려갔다.
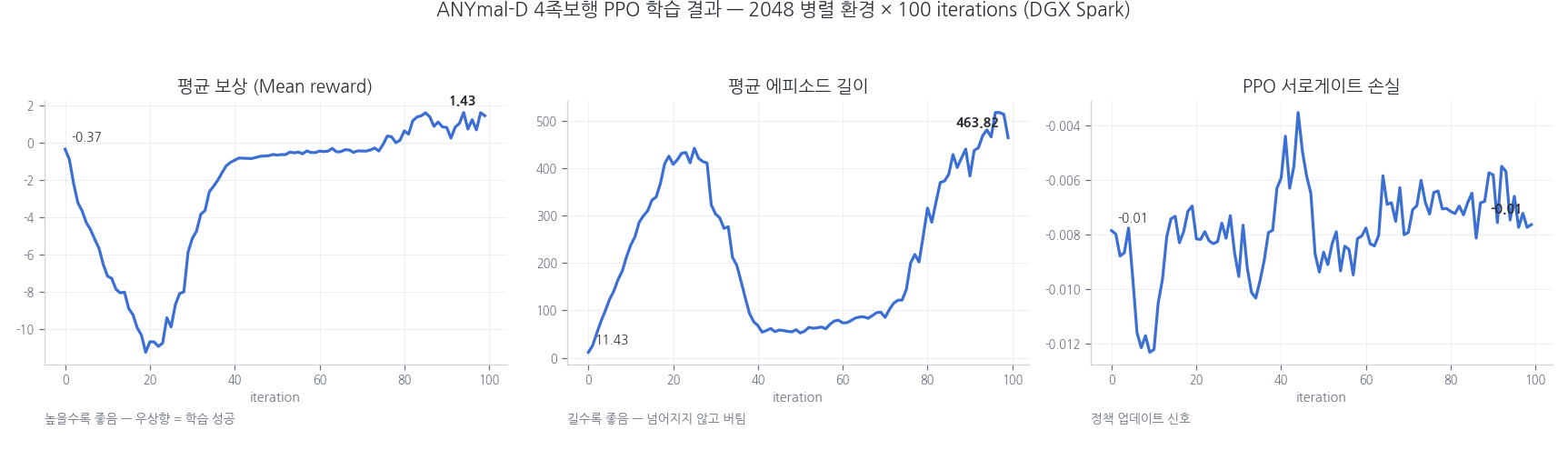
ANYmal-D PPO 학습 곡선. 탐색기의 보상 급락과 회복, 우상향 패턴이 보인다
학습 완료 후 play.py 스크립트 (python play.py --task Isaac-Velocity-Flat-Anymal-D-v0 --num_envs 16)를 통해 학습된 정책을 재생해 봤다. Isaac Sim 화면에서 16대의 로봇이 각자 무작위 속도 명령을 전달받아 서로 다른 방향으로 자유롭게 걸어 다니는 것을 확인할 수 있다. 특히 구동 과정에서 학습 산출물로 model.onnx 파일이 자동 내보내기되는데, 이 파일을 실물 로봇의 온보드 컴퓨터에 올리기만 하면 시뮬레이션 정책을 실재 로봇으로 바로 이식할 수 있는 편리한 Sim-to-Real 구조를 제공한다.

학습 완료된 정책으로 보행 중인 ANYmal 로봇 16대
마무리
정리하면, 현재 시점에서 DGX Spark에서 Isaac Sim과 Isaac Lab 개발환경 구축 고려사항은 다음과 같다.
- 드라이버는 580.159.03 권장. R590 계열은 RTX 렌더러 크래시 이슈가 있다
- 파이썬은 conda의 3.12를 사용하면 개발 헤더 문제를 피할 수 있다
- PyTorch는 cu130 빌드, Isaac Sim은 pypi.nvidia.com 인덱스에서 설치한다
- aarch64에서는 LD_PRELOAD로 libgomp를 프리로드해야 한다
- Isaac Sim 6.0의 API 변화(torch 텐서 명령, 모듈 경로 개편)에 주의한다
시뮬레이션, 합성 데이터 생성, 강화학습까지 장비 한 대에서 모두 돌아가는 것을 확인했다. 특히 통합 메모리 121GB는 대규모 병렬 환경 학습에서 체감 이점이 컸다. 오픈소스와 사전학습 정책, 클라우드 애셋이 잘 갖춰져 있어서, 예전 같으면 몇 주 걸렸을 환경 구축과 검증이 하루 안에 끝났다. 하드웨어 문제가 해결되면, 이제부터는 얼마나 다양한 환경에서 요구사항에 맞는 데이터와 모델을 잘 구축하는 방법이 필요하다. 향후, 피지컬AI기술은 사용자의 정확한 요구사항 탐색, 데이터, 모델 및 출력 간 정렬을 효과적으로 얻는 노하우가 중요해 질 것이다.
레퍼런스
- Isaac Sim 설치 문서: https://docs.isaacsim.omniverse.nvidia.com/
- Isaac Lab 문서: https://isaac-sim.github.io/IsaacLab/
- DGX Spark에서 Isaac 로봇 워크플로 (Arm Learning Path): https://learn.arm.com/learning-paths/laptops-and-desktops/dgx_spark_isaac_robotics/
- rsl_rl (PPO 구현): https://github.com/leggedrobotics/rsl_rl
- Infra sim 코드: https://github.com/mac999/infra_physics_sim








