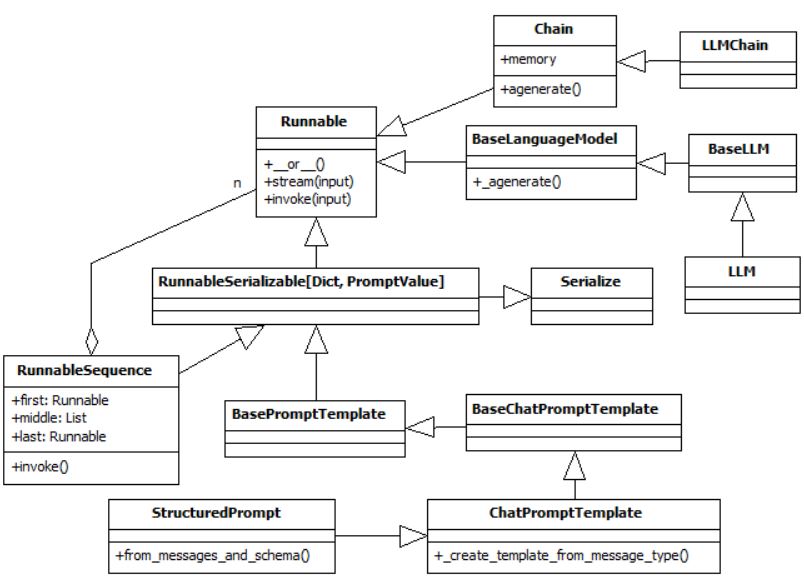
이 글은 Django, Bootstrap을 사용해 GIS 기반 IoT 데이터 분석 스타일의 데쉬보드 개발방법을 간략히 정리하고, 개발 방법 후 서비스하는 방법을 보여준다. 이를 통해, 공간정보 기반 IoT 장비를 하나의 데쉬보드로 관리하고, 분석하는 것이 가능하다. 여기서 공간정보는 GIS, BIM, 3D Point cloud data 와 같이 공간상 좌표로 표현되는 모든 정보를 말한다. 상세한 구현 소스 코드는 본 글의 Github링크를 참고할 수 있다.

이 글을 통해, 다음 내용을 이해할 수 있다.
- 부트스트랩 데쉬보드 UI 라이브러리 사용법
- 장고의 데이터 모델과 웹 UI 간의 연계 방법
- GIS 맵 가시화 및 이벤트 처리
- 실시간 IoT 데이터에 대한 동적 UI 처리 방법
이 글의 독자는 장고, 부트스트랩, GIS, IoT 의 기본 개념은 알고 있다고 가정한다.
요구사항 디자인
다음과 같은 목적의 웹앱 서비스를 가정한다.
- GIS 기반 센서 위치 관리
- IoT 데이터셋 표현
- IoT 장치 관리
- IoT 장치 활성화 관리 KPI 표현
- 계정 관리
- 기타 메뉴
이러한 정보를 보여줄 수 있는 데쉬보드 웹앱을 디자인한다. 이 예제는 데쉬보드 레이아웃을 가진 웹앱 프레임 개발 방법을 보여주는 것에 집중한다. 세부 비지니스 로직 및 데이터베이스 모델은 다른 페이지를 참고한다.
개발환경 준비
개발도구
개발에 필요한 도구는 다음으로 한다.
- UI: bootstrap
- 웹앱 프레임웍: DJango
- GIS: leaflet, Cesium
- 데이터소스: sqlite, spreadsheet, mongodb
구현된 상세 소스코드는 다음을 참고한다.
장고 기반 웹앱 프로젝트 생성
장고(Django)는 파이썬으로 작성된 고수준의 웹 프레임워크로, 웹 애플리케이션 개발을 빠르고 쉽게 할 수 있도록 도와준다. 장고는 "The web framework for perfectionists with deadlines"라는 슬로건을 가지고 있으며, 많은 기능을 내장하고 있어 개발자가 반복적인 작업을 줄이고 핵심 기능에 집중할 수 있도록 한다.
다음과 같이 장고 웹앱 프로젝트를 생성한다.
python -m venv myenv
source myenv/bin/activate
pip install django pandas
django-admin startproject iot_dashboard
cd iot_dashboard
python manage.py startapp dashboard
생성된 프로젝트 폴더 구조는 다음과 같다.

디자인 스타일 고려사항
부트스랩 레이아웃 표현
부트스트랩(Bootstrap)은 웹 개발에서 널리 사용되는 프론트엔드 프레임워크로 주로 HTML, CSS, JavaScript로 작성되어 있다. 트위터의 개발자들에 의해 처음 만들어졌으며, 웹 애플리케이션의 개발 속도를 높이고, 반응형 디자인을 쉽게 구현할 수 있도록 도와준다.
부트스랩의 그리드 시스템은 12개 열로 디자인된다. 이는 유연성과 사용 편의성을 제공하기 위한 디자인 결정이다. 반응형 웹사이트를 구축하는 데 많이 사용된다.
참고로, 12라는 숫자는 많은 약수(1, 2, 3, 4, 6, 12)를 갖고 있어 다양한 열의 조합으로 균등하게 나눌 수 있다. 이를 통해 분수나 번거로운 나머지 없이 다양한 레이아웃을 만들 수 있다.
- 유연성: 12개의 열을 사용하면 다양한 화면 크기와 디바이스에 적합한 레이아웃을 쉽게 만들 수 있다. 각 요소가 차지하는 열의 수를 조정하여 대형 데스크톱 화면, 태블릿 및 스마트폰에서 잘 보이는 반응형 디자인을 만들 수 있다.
- 이해하기 쉬움: 12개의 열을 기반으로 한 그리드 시스템은 디자이너와 개발자들에게 직관적이다. 그리드 내에서 요소들이 어떻게 동작할지 시각화하고 계산하기 쉽기 때문에 일관된 레이아웃을 생성하고 유지하기가 간단하다.
- 디자인 관행: 12개의 열을 사용하는 그리드 시스템은 부트스트랩 이전부터 다양한 그래픽 디자인 및 레이아웃 소프트웨어에서 사용되어 왔다.
데쉬보드 카드 스타일
데쉬보드에 컨텐츠를 담을 패널을 카드 스타일로 표현할 수 있다. 카드 내에 차트 뿐 아니라 지도 등 그래픽도 표시할 수 있다.


<div class="row">
<div class="col-lg-8">
<div class="card mb-3">
<div class="card-header">
<i class="fa fa-map"></i> Leaflet Map
</div>
<div class="card-body">
<div id="leafletMap" style="width:100%; height: 450px"></div>
</div>
</div>
</div>
</div>
이 코드는 행 스타일 안에 가변 8개 컬럼을 차지(col-lg-8)하고, 중간 수준 마진(card mb-3)를 가지는 카드를 생성한다. 카드는 헤더(card_header)와 본체(card-body)를 가지며, 헤더는 아이콘(<i>) 스타일의 Font Awesome의 map 아이콘을 사용한다. body 내에는 디스플레이할 위젯을 표시할 <div>를 정의한다.
부트스랩은 이와 같은 style tag가 있어, 다양한 UI를 손쉽게 정의할 수 있다. 자세한 내용은 다음을 참고한다.
개발
주요 구현부분만 표현한다. 상세 구현 코드는 앞의 github 링크를 참고한다.
데이터소스 모델 연결 및 차트 표시
본 예시는 데쉬보드 앱 디자인 및 개발 과정을 보여주는 것이므로, 간단한 iot sample dataset을 다음과 같이 models.py에 개발해 놓는다.
def IoT_model_from_file():
save_sample_iot_dataset()
df = pd.read_csv('iot_dataset_sample.csv')
json_dict = df.to_dict('records')
return json_dict
def save_sample_iot_dataset():
# Create a DataFrame
df = pd.DataFrame({
'time': [datetime.now() - timedelta(days=i) for i in range(10)],
'open': [randint(100, 200) for _ in range(10)],
'high': [randint(200, 300) for _ in range(10)],
'low': [randint(50, 100) for _ in range(10)],
'close': [randint(100, 200) for _ in range(10)],
})
# Convert the 'time' column to a string in the format 'YYYY-MM-DD'
df['time'] = df['time'].dt.strftime('%Y-%m-%d')
# Save the DataFrame to a CSV file
df.to_csv('iot_dataset_sample.csv', index=False)
IoT 센서 실시간 데이터 표시
특정 카드 내 차트에 실시간으로 데이터를 표현하기 위해서, 장고에서는 html script > view > model 업데이트 과정을 거쳐야 한다. 이 경우는 3초마다 센서 데이터를 화면에 업데이트한다고 가정한다. 이를 위해, 데이터가 준비되면 렌더링될 수 있도록 비동기 처리 요구 방식을 사용한다.
index.html의 script부분에 아래 코드를 추가한다.
setInterval(fetchColumnData, 3000); // 3초마다 업데이트
function fetchColumnData() {
var xhr = new XMLHttpRequest();
xhr.open('GET', '/charts?chartType=column', true);
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) { // 비동기. 데이터 준비 시 호출
var columnData = JSON.parse(xhr.responseText);
columnChart.options.data[0].dataPoints = columnData;
columnChart.render(); // 값을 차트에 업데이트
var columnChart_ready = document.getElementById('columnChart_ready');
var columnChart_operation = document.getElementById('columnChart_operation');
var columnChart_shutdown = document.getElementById('columnChart_shutdown');
columnChart_ready.innerHTML = columnData[0].y;
columnChart_operation.innerHTML = columnData[1].y;
columnChart_shutdown.innerHTML = columnData[2].y;
}
};
xhr.send();
}
참고로, 이러한 방식은 많은 CPU 부하를 차지한다. 다른 대안으로, 다음처럼 animation loop를 사용하는 방식이 있다.
let lastTime = 0;
const interval = 3000;
function animationLoop(timestamp) {
if (timestamp - lastTime >= interval) {
fetchColumnData();
lastTime = timestamp;
}
requestAnimationFrame(animationLoop);
}
requestAnimationFrame(animationLoop);
이 또한 성능 문제가 있다면, 실시간 업데이트 기능이 필요한 사용자만 사용할 수 있도록 페이지를 분리하거나, 별도 UI 앱을 개발하자.
이외, Leaflet(리플렛), Cesium(세슘) 라이브러리를 이용해 2차원, 3차원 화면을 표시한다. 세귬은 미리 API 사용 토큰을 발급받아야 제대로 동작된다.
Cesium.Ion.defaultAccessToken = 'your_access_token';
실행 결과
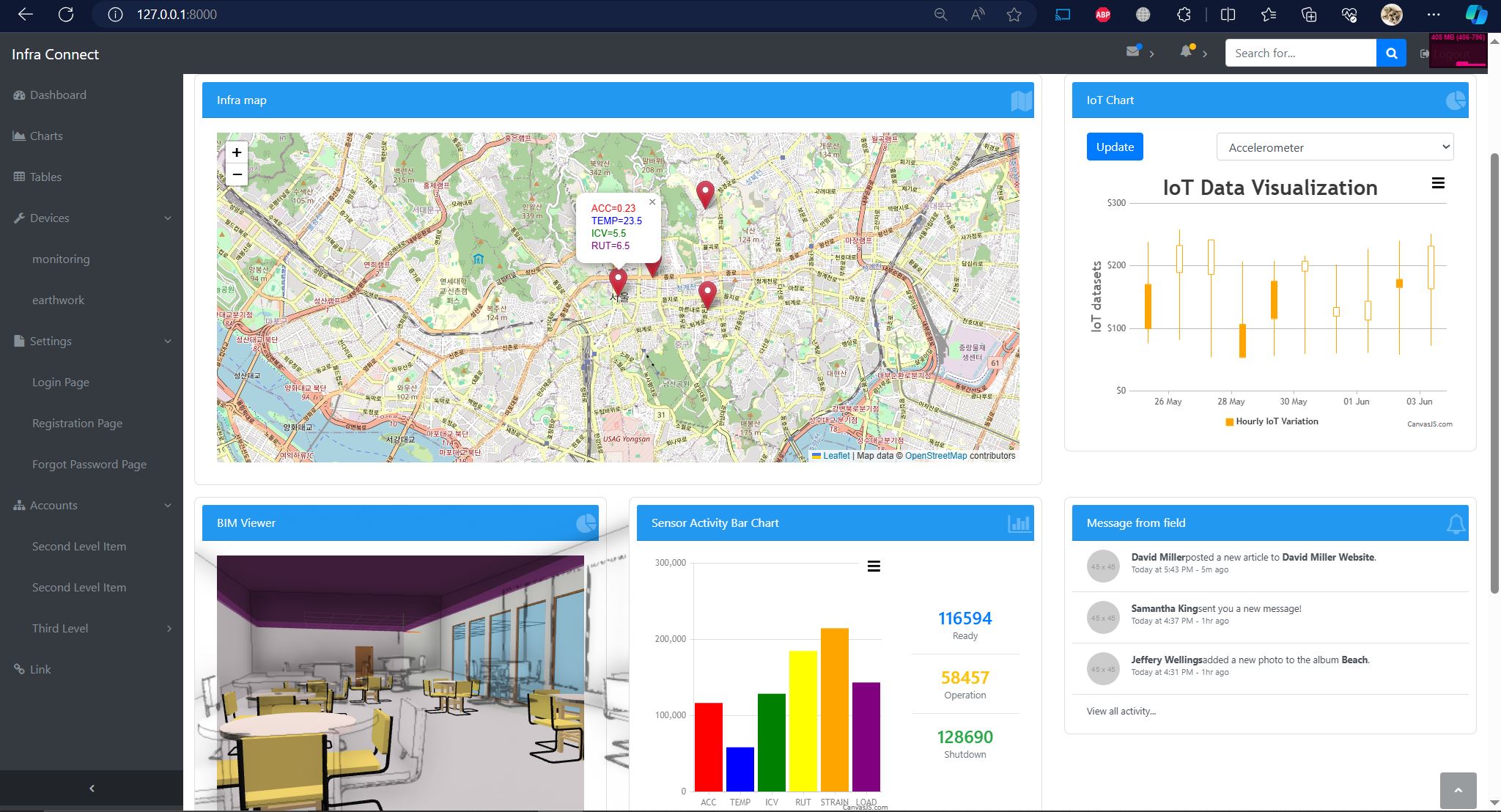
앞의 디자인 목적을 고려한 데쉬보드 실행 결과는 다음과 같다.

번들(buddle)로 컴파일된 자바스크립트 라이브러리 중 하나인 ifc.js의 viewer를 card-body의 id와 연결하여, 다음과 같이 3D 모델을 표현할 수 있다. Cesium도 동일한 방식으로 렌더링될 수 있다.
웹 서비스 배포 및 호스팅
호스팅 방법은 다양하다. 여기에선 최근 인기가 높아지고 있는 cloudtype을 사용해 배포한다.



배포에 성공하면, 다음과 같이 외부에서도 웹 서비스에 접속 실행될 것이다.
- Infra IoT Dashboard server

실행 화면
스마트폰에서 접속하면, bootstrap layout style에 따라 패널이 잘 정렬되어 보여지는 것을 확인할 수 있다.



스마트 폰 실행 모습
이외에 유용한 배포 호스팅 서버로 python anywhere, amazon free tier 등이 있다. 아래 링크를 참고한다.
마무리
요즘에는 좋은 개발 도구와 라이브러리가 워낙 많아, 프론트앤드, 백앤드, 미들웨어 스택을 만들때 조합하기가 오히려 혼란스러운 점이 있다. 장고, 부트스랩 등을 이용하면 기본적인 프레임웍에서 이들을 조합할 수 있어, 개발이 편해진다.
GIS, BIM, 3D Point cloud data 관련 유명한 라이브러리는 CDN 스토리지를 지원하고 있어, import해 사용하기 편하다. 다만, 이런 공간정보 라이브러리는 많은 리소스를 차지하므로, 성능 최적화를 고려해야 사용할 필요가 있다.
추신. 2005년에 개발된 장고는 저널리즘을 전공한 Adrian Holovaty의 주도로 Joscho Stephan과 함께 개발되었다. 그들은 올바른 저널리즘과 기타 연주를 사랑한다.

Django 개발자 Joscho Stephan, Adrian Holovaty (patrus)
- How to create an analytics dashboard in a Django app (freecodecamp.org)
- Build Interactive Analytical Dashboard in Django - DEV Community
- vishwas-r/Django-Dashboard-using-CanvasJS-Python-Charts (github.com)
- free cloud server
- web hosting
- Access Tokens | Cesium ion
- Tailwind CSS - Rapidly build modern websites without ever leaving your HTML.