이 글은 생성AI의 멀티모달 딥러닝 기술 확산의 계기가 된 Open AI의 CLIP(Contrastive Language-Image Pre-Training. 2021) 코드 개발 과정을 분석하고, 사용하는 방법을 정리한다.
CLIP은 구글이 개발한 자연어 번역 목적의 트랜스포머 모델, 비전 데이터 변환에 사용되는 VAE 개념을 사용하여, 멀티모달 학습 방식을 구현하였다. 이 글은 그 과정을 설명하고, 파이토치로 직접 구현하는 과정을 보여준다. CLIP을 이용하면, 유튜브, 넷플릭스와 같은 영상에서 자연어로 질의해 해당 장면을 효과적으로 검색할 수 있다.
참고로, CLIP에서는 트랜스포머가 핵심 컴포넌트로 사용되었다. CLIP과 같이 트랜스포머가 자연어 번역 이외에 멀티모달의 핵심 기술이 된 이유는 비정형 데이터를 연산 가능한 차원으로 수치화할 수 있는 임베딩 기술의 발전과 트랜스포머의 Key, Query, Value 입력을 통한 여러 학습 데이터 조합이 가능한 특징이 크게 작용했다.

멀티모달 시작을 알린 OpenAI의 CLIP 모델(Learning Transferable Visual Models From Natural Language Supervision, 2021)
트랜스포머와 VAE를 이용한 멀티모달 CLIP 네트웍을 좀 더 깊게 파헤쳐 보도록 한다. 앞서 설명된 트랜스포머, 임베딩과 관련된 개념에 익숙하다면, CLIP을 이해하고 구현하는 것이 그리 어렵지는 않을 것이다. 이 글에서 나오는 예시, 개념, 응용에 대한 상세 내용은 다음 링크와 글 마지막에 표시된 레퍼런스를 참고한다.
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발
- 딥러닝 기반 3차원 스캔 데이터, 포인트 클라우드 학습
- 생성(Generative) AI 오픈소스 딥러닝 모델 Stable Diffusion, ControlNet 개념 및 ComfyUI 사용법
- 어텐션 기반 트랜스포머 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법 소개
- 트랜스포머 디코더 핵심 코드 구현을 통한 동작 메커니즘 이해하기
- ChatGPT와 같은 생성AI 서비스 개발을 위한 간단한 LLAMA-2 설치와 사용법
- Computer_vision_deeplearning: computer vision based on deep learning lecture materials, github
머리말
OpenAI에서 개발한 CLIP 모델은 공유 임베딩 공간 내에서 이미지 및 텍스트 형식을 통합하는 것을 목표로 했다. 이 개념은 기술과 함께 이미지와 텍스트를 넘어 다른 양식을 수용한다(멀티모달). 예를 들어, 유튜브 등 비디오 애플리케이션 내에서 텍스트 검색 성능을 개선하기 위해 공통 임베딩 공간에서 비디오 및 텍스트 형식을 결합하여 모델을 학습시켰다.
사실, 임베딩 텐서를 잠재 공간(Latent Space)으로 이기종 데이터를 변환, 계산, 역변환할 수 있다는 아이디어는 VAE 기술, 구글의 트랜스포머 논문(2017)을 통해 개발자들 사이에 암시되어 있었다. 이를 실제로 시도해본 연구가 CLIP이다.
참고로, CLAP(Contrastive Language-Audio Pretraining)는 동일한 임베딩 공간 내에서 텍스트와 오디오 형식을 통합하는 또 다른 모델로, 오디오 애플리케이션 내에서 검색 기능을 개선하는 데 유용하다.
CLIP은 다음 응용에 유용하다.
- 이미지 분류 및 검색: CLIP은 이미지를 자연어 설명과 연결하여 이미지 분류 작업에 사용할 수 있다. 사용자가 텍스트 쿼리를 사용하여 이미지를 검색할 수 있는 보다 다양하고 유연한 이미지 검색 시스템을 허용한다.
- 콘텐츠 조정: CLIP은 부적절하거나 유해한 콘텐츠를 식별하고 필터링하기 위해 이미지와 함께 제공되는 텍스트를 분석하여 온라인 플랫폼의 콘텐츠를 조정하는 데 사용할 수 있다.
참고로, Meta AI는 최근 이미지, 텍스트, 오디오, 깊이, 열, IMU 데이터 등 6가지 양식에 걸쳐 공동 임베딩을 학습하는 ImageBind를 출시했다. 두 가지 모달리티를 수용하는 최초의 대규모 AI 모델인 CLIP은 ImageBind 및 기타 다중 모달리티 AI 시스템을 이해하기 위한 전제 조건이다.
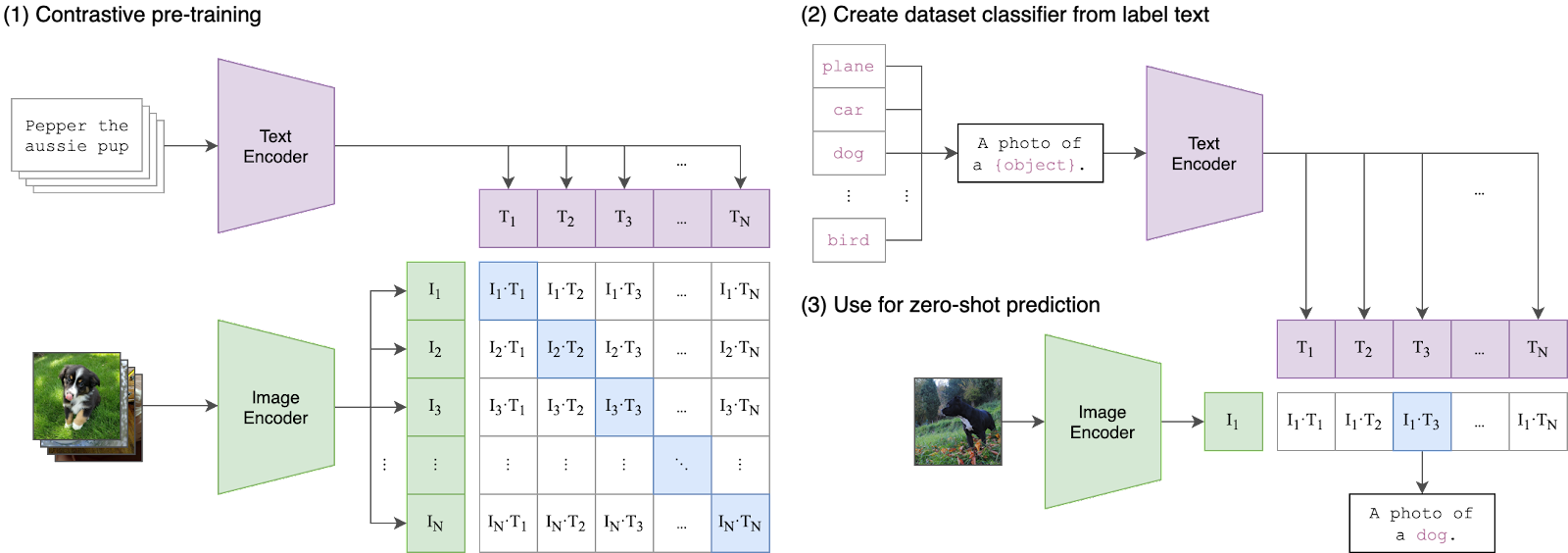
CLIP은 배치 내에서 어떤 N × N (이미지, 텍스트) 쌍이 실제 일치하는지, 예측하도록 설계되었다. CLIP은 이미지 인코더와 텍스트 인코더의 공동 학습을 통해, 멀티모달 임베딩 공간을 만든다. CLIP 손실은 트랜스포머의 어텐션 모델을 사용하여, 학습 데이터 배치에서 N개 쌍에 대한 이미지와 텍스트 임베딩 간의 코사인 유사성을 최대화하는 것을 목표로 한다.
다음은 이를 설명하는 의사코드이다.
- img_en = image_encoder(I) # [n, d_i] 이미지 임베딩 인코딩를 통한 특징 추출
- txtxt_emdn = textxt_emdncoder(T) # [n, d_t] 텍스트 임베딩 인코딩을 통한 특징 추출
- img_emd = l2_normalize(np.dot(img_en, W_i), axis=1) # I x W 결합(조인트) 멀티모달 임베딩 텐서 계산
- txt_emd = l2_normalize(np.dot(txtxt_emdn, W_t), axis=1) # T x W 결합(조인트) 멀티모달 임베딩 텐서 계산
- logits = np.dot(img_emd, txt_emd.T) * np.exp(t) # I x T * E^t 함수 이용한 [n, n]코사인 유사도 계산
- labels = np.arange(n)
- loss_i = cross_entropy_loss(logits, labels, axis=0) # 이미지 참값 logits과 예측된 label간 손실
- loss_t = cross_entropy_loss(logits, labels, axis=1) # 텍스트 참값 logits과 예측된 label간 손실
- loss = (loss_i + loss_t)/2 # 이미지, 텍스트 손실 평균값
실제 OpenAI 논문에는 다음과 같이 기술되어 있다(동일하다).

이제 각 단계를 개발하는 과정을 확인해보자.
모델 아키텍처 및 학습
ClIP는 비전 및 텍스트 데이터 세트를 인코딩하기 위한 백본으로 두 개의 개별 아키텍처를 사용하다.
- image_encoder: 이미지 인코딩을 담당하는 신경망 아키텍처(예: ResNet 또는 Vision Transformer).
- text_encoder: 텍스트 정보 인코딩을 담당하는 신경망 아키텍처(예: CBOW, BERT 또는 Text Transformer).
원래 CLIP 모델은 CLIP 모델을 학습하는 데 사용한 데이터 세트(4억 개의 이미지-텍스트 쌍)의 양이 많기 때문에 사전 학습된 가중치를 사용해 학습된다. 여기서는 컴퓨터 비전 분야에서 유명한 ResNet 딥러닝 모델 및 자연어 처리에 사용되는 DistilBert 딥러닝 모델에서 사전 학습된 가중치 파일을 사용한다.

CLIP 텍스트 인코더, 이미지 인코더 어텐션 스코어 계산 아키텍처 (CLIP, Open AI, 2021)
CLIP 모델은 flickr30k 데이터 세트를 사용하여 훈련된다. 이 데이터 세트는 31,000개 이상의 이미지로 구성되며, 각 이미지에는 최소 5개의 캡션이 라벨링되어 있다. 이 예제에서는 각 이미지에 대해 두 개의 캡션을 사용하여, 총 62,000개의 이미지 및 텍스트 쌍을 학습에 사용하다. 이미지-캡션 텍스트 쌍을 유사도 계산해, 이미지 검색 목적으로 인코더 모델을 학습시킨다. 참고로, GitHub에는 164,000개의 이미지 및 텍스트 쌍이 있는 MS-COCO 데이터 세트에서 모델을 학습시키는 코드도 포함되어 있다.
학습 데이터 준비, 특징 인코딩 및 잠재 공간 투영하기
이미지-텍스트 N쌍의 학습 데이터는 다음과 같은 구조로 사용된다.
- I[n, h, w, c]: n은 미니배치 크기, h와 c는 이미지 해상도, c는 이미지 채널 수. 예) [128,224,224,3]
- T[n, l]: n은 미니배치 크기, l은 텍스트 시퀀스 길이. 예) [128, 32]
학습할 배치 데이터를 준비하고, 다음과 같이 이미지, 텍스트 특징 추출을 위해 인코딩 모델을 준비한다.
I_f = models.resnet34(pretrained=True)
T_f= AutoModel.from_pretrained("distilbert-base-multilingual-cased")
인코딩된 이미지-텍스트 특징 텐서를 신경망 W 텐서에 의해 투영한다. 투영된 결과는 차원이 축소된 임베딩 텐서가 된다. 이 임베딩 텐서는 잠재 공간 차원의 특정 위치에 표현될 것이다.
- W_i[d_i, d_e]: 인코딩된 이미지 특징 텐서를 잠재 공간에 맵핑하기 위한 투영 텐서 W_i를 준비한다. W 텐서 행렬은 d_i 차원을 d_e 차원으로 맵핑한다.
- W_t[d_t, d_e]: W_i와 동일한 개념으로, 텍스트 특징 텐서를 잠재 공간으로 맵핑하는 W_t 텐서 행렬을 준비한다.

잠재 공간 차원 상의 Text-Image Pair 표현(Nature.com, 2022)
투영 연산은 가중치가 학습되는 W_t 투영 텐서를 사용해야 하므로, 두 개의 선형 레이어를 설계해야 한다. 그러므로, 투영 가중치는 Activate Gradient 를 가진다.
이는 다음과 같이 구현될 수 있다.
class Projection(nn.Module): # W_t 투영 텐서 학습 모듈 정의
def __init__(self, d_in: int, d_out: int, p: float=0.5) -> None:
super().__init__()
self.linear1 = nn.Linear(d_in, d_out, bias=False) # 단순히 두개의 선형 레이어 가짐
self.linear2 = nn.Linear(d_out, d_out, bias=False)
self.layer_norm = nn.LayerNorm(d_out) # 레이어 가중치 정규화
self.drop = nn.Dropout(p) # 드롭 아웃 처리
def forward(self, x: torch.Tensor) -> torch.Tensor:
embed1 = self.linear1(x)
embed2 = self.drop(self.linear2(F.gelu(embed1)))
embeds = self.layer_norm(embed1 + embed2)
return embeds
이 전체 과정은 다음 다이어그램과 같이 표현될 수 있다.

CLIP 아키텍처 전체 구조(CLIP, Contrastive Language-Image Pre-Training. 2021)
이를 코드로 구현하면 다음과 같다.
class VisionEncoder(nn.Module): # 이미지 인코더 모듈 정의
def __init__(self, d_out: int) -> None:
super().__init__()
base = models.resnet34(pretrained=True)
d_in = base.fc.in_features
base.fc = nn.Identity()
self.base = base
self.projection = Projection(d_in, d_out) # ResNet에서 얻은 이미지 특징을 잠재 공간으로 프로젝션.
for p in self.base.parameters(): # 사전 학습 모델 사용하므로, 학습이 필요 없음 설정
p.requires_grad = False
def forward(self, x):
projected_vec = self.projection(self.base(x))
projection_len = torch.norm(projected_vec, dim=-1, keepdim=True)
return projected_vec / projection_len # 텐서값 정규화
class TextEncoder(nn.Module): # 이미지 인코더와 동일한 방식으로 텍스트 인코더 모듈 정의
def __init__(self, d_out: int) -> None:
super().__init__()
self.base = AutoModel.from_pretrained(Config.text_model)
self.projection = Projection(Config.transformer_embed_dim, d_out)
for p in self.base.parameters():
p.requires_grad = False
def forward(self, x):
out = self.base(x)[0] # BERT 인코더 이용해 텍스트 특징 텐서 획득
out = out[:, 0, :] # 필요한 특징 부분만 추출. get CLS token output
projected_vec = self.projection(out) # 잠재 공간으로 프로젝션
projection_len = torch.norm(projected_vec, dim=-1, keepdim=True)
return projected_vec / projection_len # 텐서값 정규화
vision_encoder = VisionEncoder(Config.embed_dim)
I_e = vision_encoder(images)
caption_encoder = TextEncoder(Config.embed_dim)
T_e = caption_encoder(text["input_ids"])
유사도 계산을 위한 어텐션 모델 적용과 CLIP 손실 함수 설계
트랜스포머 논문에 적용된 토큰화된 텐서 간 cosine 유사도 계산은 CLIP에서 다음과 같이 적용된다.
logits = np.dot(I_e, T_e.T) * np.exp(t)
이는 다음과 같이 행렬곱셈 연산자 '@' 구현된다(np.dot과 동일).
logits = T_e @ T_e.T
CLIP의 학습 목표는 잠재 공간 차원에서 표현된 이미지와 텍스트 중 관련된 쌍의 거리를 가깝게 조정하는 것이다. 그러므로, 손실 함수는 다음과 같이 설계된다.
- labels = np.arange(n): 배치 인덱스를 표현하는 라벨을 생성
- loss_i = cross_entropy_loss(logits, labels, axis=0): 이미지 축에 따라 교차 엔트로피 손실 계산
- loss_t = cross_entropy_loss(logits, labels, axis=1): 텍스트 축에 따라 교차 엔트로피 손실 계산
- loss = (loss_i + loss_t) / 2: 이미지, 텍스트 손실 평균 계산

잠재 공간 차원에서 Text-Image Pair 간 거리(Synthesis.AI, 2023)
손실함수 구현은 다음과 같다.
def CLIP_loss(logits: torch.Tensor) -> torch.Tensor: # 로짓은 텐서 행렬로 입력됨
n = logits.shape[1] # 샘플 수
labels = torch.arange(n) # 라벨 텐서 획득
loss_i = F.cross_entropy(logits.transpose(0,1), labels, reduction="mean") # 이미지 행 손실
loss_t = F.cross_entropy(logits, labels, reduction="mean") # 텍스트 행 손실
loss = (loss_i + loss_t) / 2 # 평균 손실값 계산
return loss
labels = torch.arange(n) # 라벨 텐서 획득
loss_i = F.cross_entropy(logits.transpose(0,1), labels, reduction="mean") # 이미지 행 손실
loss_t = F.cross_entropy(logits, labels, reduction="mean") # 텍스트 행 손실
loss = (loss_i + loss_t) / 2 # 평균 손실값 계산
return loss
최종 CLIP 모델 구현
앞서 정의한 모든 부분을 합하면, 다음과 같이 CLIP 모델이 구현된다.
class CustomModel(nn.Module):
def __init__(self, lr: float = 1e-3) -> None:
super().__init__()
self.vision_encoder = VisionEncoder(Config.embed_dim)
self.caption_encoder = TextEncoder(Config.embed_dim)
self.tokenizer = Tokenizer(AutoTokenizer.from_pretrained(Config.text_model))
self.lr = lr
self.device = "cuda" if torch.cuda.is_available() else "cpu"
def forward(self, images, text):
text = self.tokenizer(text).to(self.device)
image_embed = self.vision_encoder(images)
caption_embed = self.caption_encoder(text["input_ids"])
similarity = caption_embed @ image_embed.T
loss = CLIP_loss(similarity)
img_acc, cap_acc = metrics(similarity)
return loss, img_acc, cap_acc
구현된 CLIP 모델로 학습해 보기
제대로 학습되는 지 확인해 본다. 학습 데이터는 flickr30k 데이터셋을 사용한다. 학습 데이터 구조는 다음과 같다.




학습 데이터 배치 생성을 위해, 토치의 데이터셋을 사용자 정의한다.
from torch.utils.data import DataLoader
from datasets import load_dataset
from torchvision import transforms
from PIL import Image
import torch
from torchvision import transforms
from PIL import Image
class Flickr30kDataset(torch.utils.data.Dataset): # flickr30k 데이터셋
def __init__(self):
self.dataset = load_dataset("nlphuji/flickr30k", cache_dir="./huggingface_data") # 허깅페이스의 데이터획득
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
]) # 학습을 위해 이미지 224,224 해상도로 정규화
self.cap_per_image = 2 # 인코딩될 텍스트 캡션은 2개만 사용
def __len__(self):
return self.dataset.num_rows["test"] * self.cap_per_image # 학습 데이터수=test 이미지들 갯수 x 해당 이미지의 캡션 수
def __getitem__(self, idx):
original_idx = idx // self.cap_per_image # 입력 데이터 인덱스에 대한 이미지 당 캡션수의 몫 획득
image = self.dataset["test"][original_idx]["image"].convert("RGB")
image = self.transform(image) # 224x224 텐서로 이미지 변환
caption = self.dataset["test"][original_idx]["caption"][idx % self.cap_per_image] # 캡션 획득
return {"image": image, "caption": caption} # 캡션에 대한 해당 이미지, 텍스트 리턴
flickr30k_custom_dataset = Flickr30kDataset()
앞서 모델 파라메터 설정에 사용된 Config 클래스는 다음과 같이 설계된다.
from dataclasses import dataclass
@dataclass
class Config:
embed_dim: int = 512 # 임베딩 차원
transformer_embed_dim: int = 768 # 트랜스포머 임베딩 차원
max_len: int = 32 # 텍스트 최대 길이
text_model: str = "distilbert-base-multilingual-cased" # 텍스트 특징 추출 인코더
epochs: int = 3 # 학습 에포크
batch_size: int = 128 # 배치 크기
이제, 학습 데이터를 로딩해 확인해 본다.
clip_dataloader = DataLoader(flickr30k_custom_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4) # 데이터 로더 객체 생성

학습 데이터 일부 예시
model = CustomModel().to(device)
optimizer = torch.optim.Adam([
{'params': model.vision_encoder.parameters()},
{'params': model.caption_encoder.parameters()}
], lr=model.lr)
이제, 다음과 같이 학습한다.
batch_zero = True
for epoch in range(start_epoch, num_epochs): # 에포크 횟수만큼 학습
model.train()
for batch in clip_dataloader: # 미니 배치 학습
image = batch["image"].to(device)
text = batch["caption"]
loss, img_acc, cap_acc = model.common_step((image, text)) # 이미지-텍스트 쌍 유사도 계산
optimizer.zero_grad() # 역전파 학습
loss.backward()
optimizer.step()
if batch_zero: # 손실값 출력
print(f"Epoch [{0}/{num_epochs}], Batch Loss: {loss.item()}")
batch_zero = False
print(f"Epoch [{epoch+1}/{num_epochs}], Batch Loss: {loss.item()}")
print("Training complete.")
앞서 설명을 확인해 보면, 기존에 연구 개발된 기술과 개념을 사용하였다는 것을 잘 알 수 있다. CLIP의 우수한 점은 멀티모달 데이터셋을 조인트하여 유사도 어텐션 스코어를 계산하는 방식을 잠재 공간에서 수행한다는 아이디어를 구현한 점이다.
CLIP 실제 활용 예제 - 텍스트 기반 이미지 검색
앞서 코드 분석을 통해, CLIP의 동작 메커니즘을 이해하였다. 이를 이용해, 두 멀티모달 데이터 간 유사도를 얻어본다. 예제에 사용할 멀티모달 데이터는 무작위 이미지, 텍스트 캡션을 사용한다.
이 예제에서는 OpenAI에서 공개한 CLIP 코드를 직접 사용해 본다.
다음과 같이 터미널에 명령을 실행한다.
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
다음과 같이 파이썬 소스를 만든 후 실행해 본다. 이 예제는 텍스트와 함께 주어진 이미지에 대한 유사도를 계산하여 리턴한다. 이를 이용하면 입력 텍스트에 대한 영상 이미지를 검색할 수 있다. 예를 들어, 넷플릭스와 같은 비디오, 이미지 검색 엔진 등에 사용될 수 있다.
import os
import clip
import torch
from torchvision.datasets import CIFAR100
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# Prepare the inputs
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")

유사도 계산 결과
다음은 "diagram", "dog", "cat" 와 다이어그램 특징을 입력하고 유사도를 예측한 것이다.
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("f:/projects/multimodal/clip/CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
그 결과는 다음과 같이 예상한 다이어그램 유형 그림이 99.27% 유사하다고 예측되었다.
입력 이미지(다이어그램)


텍스트-이미지 간 유사도 결과 예시(OpenAI)
마무리
CLIP은 기존 개발된 딥러닝 기술(임베딩, 인코딩, 트랜스포머, ResNet 등)을 이용해 이종 데이터셋을 잠재 공간 차원에 표현하고 계산하는 방법을 제시한 훌륭한 멀티모달 학습 방법을 제시한다. 공개된 CLIP 기술은 많은 딥러닝 연구 개발자들이 멀티모달 생성AI 기술 개발을 촉진하는 계기가 되었다. 이제 U-Net, VAE 등을 응용하면, 멀티모달 생성AI를 구현할 수 있다.
레퍼런스
- OpenAI, 2021, Learning Transferable Visual Models From Natural Language Supervision
- Building CLIP From Scratch. Open World Object Recognition on the… | by Matt Nguyen | Toward Humanoids | Medium
- Building CLIP from scratch using PyTorch | Contrastive Language-Image Pre-Training | by Shubh Mishra | The Deep Hub | Medium
- Building a CLIP-like Model for Image-Text Alignment From Scratch: A Step-by-Step Guide | by Modiparth | Medium
- OpenAI/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
- CLIP (huggingface.co)
- CLIP Model and The Importance of Multimodal Embeddings | by Fahim Rustamy, PhD | Dec, 2023 | Towards Data Science
- Question answering (huggingface.co)
- CodeGen (huggingface.co)
- Simple Implementation of OpenAI CLIP model: A Tutorial | Towards Data Science
- explosion/curated-transformers: 🤖 A PyTorch library of curated Transformer models and their composable components (github.com)
- MarianCG: a code generation transformer model inspired by machine translation | Journal of Engineering and Applied Science | Full Text (springeropen.com)
- Fine-tuning with custom datasets — transformers 3.2.0 documentation (huggingface.co)
- Fine-Tune Transformer Models For Question Answering On Custom Data | by Skanda Vivek | Towards Data Science
- Nature.com, 2022, Contrastive language and vision learning of general fashion concepts
- Synthesis AI, 2023, CLIP and multimodal retrieval: Generative AI IV
요즘 너도 나도 생성AI 전문가다. 업계 있다 보면, 항상 무슨 아이디어를 누가 먼저 말했는 지 중요하게 여기는 분들이 있다. 하지만, 직접 연구 개발하지 않고 전문가라 스스로 칭하는 것은 본인과 주변의 발전에 도움이 되지 않는다(언젠가는 바닥이 들어난다).
연구자, 개발자, 엔지니어의 실제 파급력은 그 아이디어를 현실에 적용한 기술로 구현할 때 발생한다(아이디어만 제시하고 말하는 사람은 비지니스 컨설턴트, 아이디어 제안자라 한다. 본인 스스로 전문가라 말해도 남이 인정해 주지 않으면 무슨 의미가 있나). 전문가로써 인정받고 싶다면, 시간을 아껴서 깊게 공부하고, 직접 해봐야 한다.
댓글 없음:
댓글 쓰기