이 글은 ChatGPT 4.0과 같은 LMM(Large langauge Multi-modal Model. 멀티모달 대규모 언어모델)인 LLaVA(Large Language and Vision Assistant. 라바)기반 멀티모달 생성AI 서비스 개발 방법을 나눔한다.
LLaVA는 Image To Text와 같은 언어-이미지 시각 어시스턴스(Language-Image Visual Assistant)를 지원하기 위해, ViT(Visual Instruction Tuning. 시각적 지시 조정)을 기반으로 개발된 멀티모달 모델 오픈소스이다. 예를 들어, 이미지를 단순히 분류해 주는 것이 아닌, 이미지 내 특정 객체들을 인식하고 관계를 설명할 수 있는 기술을 지원한다.

단독 로컬 서버PC에서 LLaVA 서비스 모습
참고로, ViT는 이미지의 특정 위치에 대한 객체 정보를 인식할 수 있도록 학습하는 기술이다. 예를 들어, GPT-4는 특정 부분의 시각적 특징을 인코딩하기 위해 YOLO모델과 같이 경계 상자를 사용하고, CLIP모델과 같이 해당 부분에 대한 텍스트 임베딩을 입력하여 학습한다(Visual Instruction Tuning).

ViT(Visual Instruction Tuning) 개념
LLaVA의 NeXT버전은 구글 제미나이 프로 성능을 능가했다고 밝혔으며, 이전 버전인 LLaVA 1.5에 비해 이미지 해상도, OCR 기능 등이 개선되었다고 한다.

머리말
LLaVA 아키텍처
이 글은 Ollama를 이용해 LLaVA NeXT를 로컬 PC에서 실행하는 방법을 따라해 본다.
LLaVA는 대형 멀티모달 모델으로, GPT-4.0과 유사한 LMM을 개발하고자, 마이크로소프트 연구팀에서 오픈소스로 개발되었다. MS는 LLaVA의 논문, github code, demo site 등을 공개하였다.


LLaVA LMM(Large language Multi-modal Model)은 비전 인코더, LLM 모델을 기반으로 개발되었으며, Image to Text에서 인상적인 성능을 보여준다. LLaVA는 비전 인코더로 OpenAI에서 공개한 CLIP 모델을 사용했으며, 메타(페이스북)에서 공개한 LLaMA 기반 Vicuna LLM 모델을 사용했다. 학습은 A100 GPU x 8 x 1 Day 와 60만개 데이터셋을 사용했다.
LLaVA를 설치하고, 실행해 보기 위해서는 다음 개발환경이 컴퓨터에 미리 설치되어 있다고 가정한다(Ubuntu, NVIDIA, CUDA등 설치 방법은 앞의 글 참고).
터미널에서 다음 명령을 실행해 LLAVA모델을 설치한다.
제대로 설치되면, 다음과 같이 프롬프트 질문과 답변을 얻을 수 있다.

LLaVA모델에게 PyThon 코딩 요청한 모습
개발환경 준비
다음 명령을 터미널에서 실행한다.
git clone https://github.com/haotian-liu/LLaVA.git
conda create -n venv_lmm python=3.10 -y
conda activate venv_lmm
pip install --upgrade pip
pip install -e .
pip install cog


LLaVA 실행하기
다음 명령을 각 터미널에서 실행한다.
python -m llava.serve.controller --host 0.0.0.0 --port 10000
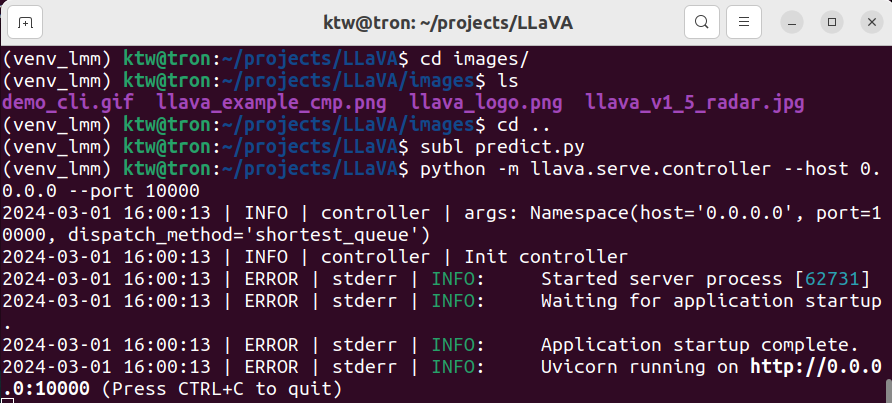
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.6-34b --load-4bit

참고로, 모델 다운로드에 매우 오랜 시간이 걸리므로, 실행해 놓고, 다른 일을 하는 것이 좋다.
모델 다운로드 후 다음을 실행한다. 그럼 gradio_web_server 웹서버가 실행되고, 해당 주소로 LLaVA UI가 서비스된다. 참고로 Gradio는 머신러닝 파이프라인을 위한 Web App을 빠르게 만들 수 잇는 파이썬 라이브러리이다(참고).
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --share
실행되면, 다음과 같이 Gradio 웹 인터페이스가 실행된다. 궁금한 프롬프트를 입력하면, 적절히 잘 대답해준다.

다음과 같이 적절한 이미지를 입력해 보고, 질문해 본다. 그럼, 그림 내용을 묘사 설명해준다.
LLaVA 모델 에러 처리 방법
실제로 LLaVA 모델을 실행해보면 다양한 에러가 발생할 수 있다. 다음은 시행착오를 정리한 것이다.
1. llava.service 에러가 발생하면, OLLAMA를 다음과 같이 설치하고 다시 시도한다.
curl -fsSL https://ollama.com/install.sh | sh
2. 패키지 설치가 잘못되었을 수 있다. 이 시점에도 LLaVA모델 코드는 계속 수정되고 있는 상황이다. 이런 이유로 패키지 버전 불일치 문제가 발생할 수 있다. 이 경우, 에러를 확인해 하나씩 적절한 패키지 버전을 설치한다.
pip install llava cog pydantic fastapi gradio protobuf
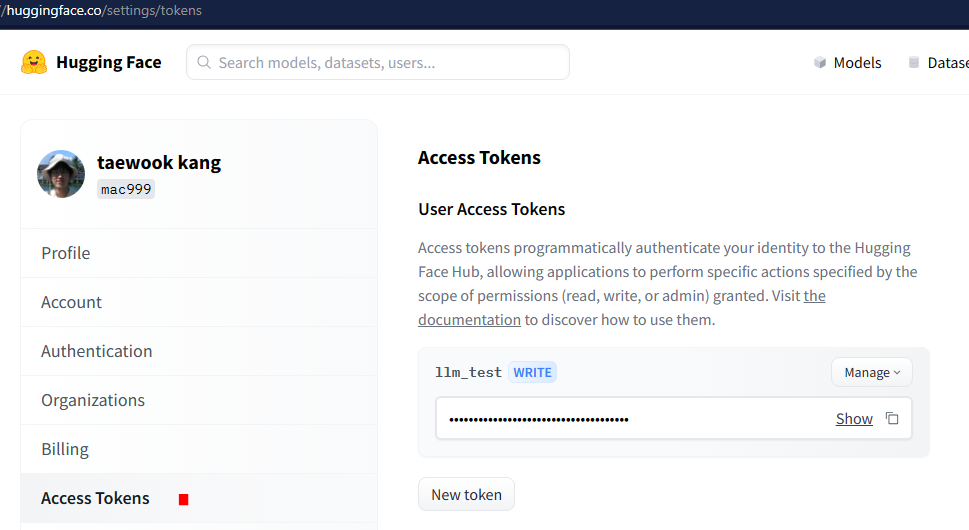
3. 앞의 내용 실행 중 허깅페이스 CLI 토큰 입력 요청이 있을 수 있다. 이 경우, 아래 링크를 참고해, 토큰을 발급받고, 입력한다.
4. bitsandbytes 에러가 발생할 수 있다.
UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable" warn("The installed version of bitsandbytes was compiled without GPU support. " 'NoneType' object has no attribute 'cadam32bit_grad_fp
이 경우, 다음 링크를 참고해 해결해야 한다.
5. GPU RAM 에러가 발생할 수 있다. 그럼, 좀 더 작은 사이즈 모델(참고)을 다운로드받아 서버를 실행한다.
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-7b --load-4bit
마무리
ChatGPT-4와 같은 LMM을 LLaVA를 이용해 코드 한 줄 없이 로컬 PC에 설치하고, 서비스를 구현할 수 있다. 실행 결과 LLaVA의 꽤 훌륭한 LMM 성능을 확인할 수 있다.
다만, 아직 특정 전문 분야의 멀티 모달리티 성능은 아직 그리 좋지 못하다. 참고로, MS, Google과 같은 빅테크 기업들은 시장성이 큰 헬스케어 분야에서 대학 병원 등과 협업하여, 이런 격차를 줄이기 위해 노력하고 있어, 조만간 더욱 발전될 것이다.

LLAVA-Med (Microsoft)

LLaVA-Med 학습 예시(헬스케어 분야. Microsoft)
레퍼런스
- Microsoft, 2023.6, LLaVA-Med Trains a Large Language-and-Vision Assistant for Biomedicine Within 15 Hours | Synced (syncedreview.com)
- Nomic, 2024.1, Nomic Embed 임베딩 기술
- Vision models · Ollama Blog
- Llava Model UI Setup - Mervin Praison
- Visual instruction tuning towards large language and vision models with GPT-4 level capabilities considering GPU RAM
- Open source alternative to GPT4
- Introduce how to using LLaVA : Large Language and Vision Assistant | by Dimas Mulya | Medium
- LLaVA: Visual Instruction Tuning (morioh.com), PDF-Text-Voice, LLaVA, LiteLLM
- VideoPoet – Google Research
- Running Gradio On Your Web Server With Nginx
댓글 없음:
댓글 쓰기