이 글은 개발에 많은 노력이 드는 LLM(Large Language Model) 기술을 개발하고 GitHub에 공개한 메타(페이스북)의 LLAMA-2(라마) 논문을 분석하고, 핵심을 요약한다. 이 지식은 LLM 기반 서비스 및 생성AI 개발 시 유용하다. 참고로, META AI 연구진(리더 Yann LeCun 교수)은 LLM 민주화를 위해 라마를 LLM 커뮤니티에 공개하고, 관련 실행 코드를 GITHUB에 업로드하였다.

LLAMA-2
라마-2 설치 및 활용에만 관심이 있다면, 다음 링크를 참고한다.
라마2 기술에 대해 분석하기 전에 라마1 기술을 먼저 정리해 본다.
LLAMA-1
서론
7B에서 65B 매개변수를 가진 LLM 모델인 라마는 수조개의 토큰을 학습하고, 이를 이용해 다양한 AI 에이전트 서비스를 개발할 수 있다. LLAMA-13B는 대부분 벤치마킹에서 GPT-3(175B)보다 성능이 뛰어나다.
라마는 LLM을 개발할 때 목표를 훈련 속도가 아닌 추론 속도가 가장 빠른 모델을 개발하는 것으로 한다. 예를 들어, LLAMA-13B는 경쟁 모델보다 10배 더 작음에도 불구하고, GPT-3보다 뛰어나다. 이 모델은 단일 GPU에 실행할 수 있다. 이러한 가성비를 통해, LLM 민주화에 도움이 될 것이라 믿는다. 참고로, 라마를 모델을 개발하는 데 5개월이 걸렸으며(아이디어, 문서 작업 등 제외), 한 모델을 학습하는 데 21일이 걸렸다.
데이터 훈련 접근 방식
라마의 데이터 훈련 방식은 이전 LLM연구 논문인 OpenAI, Google, DeepMind 의 LLM 개발과정을 참조해 유사하게 진행되었다.
- Brown et al., 2020, Language models are few-shot learners, OpenAI
- Chowdhery et al., 2022, Scaling Language Modeling with Pathways, Google
- Hoffmann et al., 2022, Training Compute-Optimal Large Language Models, DeepMind
라마의 훈련 데이터는 여러 소스가 혼합되어 있다. 다음 표는 이를 보여준다. 라마는 공개된 데이터만 사용하였다. 낮은 품질의 컨텐츠는 fastText 선형 분류기, n-gram 모델을 이용해 사전 필터링되었다. 학습에 문제가 있는 노이즈 데이터는 사전 필터링된다.

학습 데이터셋
다음은 라마에서 사용된 학습 데이터의 예시이다.







학습 모델 아키텍처
학습 모델의 핵심 컴포넌트인 트랜스포머를 사용하였다(Google, 2017). 학습 안정화를 위해 Zhang, Sennrich (2019)가 소개한 RMSNorm을 사용하였다. ReLU 함수는 SwiGLU 활성화 함수로 대체하였다(Shazeer, 2020). 이외, 위치 임베딩은 RoPE(로터리 임베딩. Su et al, 2021)을 사용한다.
옵티마이저는 AdamW(Loshchilov and Hutter, 2017)을 사용해 훈련한다. 베타1=0.9, 베타2=0.95를 사용하여, 어텐션 스코어 계산을 위한 코사인 학습을 일정히 유지한다. 라마의 최대 학습률은 10%이다. 참고로, 0.1 가중치 감쇠를 사용하였다.
선형 레이어는 PyTorch autograd 대신 레이어를 직접 사용해 메모리 사용량을 줄인다(Korthikantiet al, 2022). 64B 모델에서 380개 토큰/초/GPU가 처리된다. 80GB를 가진 A100 GPU의 경우, 21일 정도가 학습에 소요된다.

7B, 13B, 33B, 65B 모델에서 훈련 토큰 대비 학습 손실
훈련 속도 개선을 위해, xformers 라이브러리 사용 시 어텐션 가중치를 저장하지 않았으며, 역방향 가중치 업데이트 시 체크포인트를 사용하였다(Rabe & Staats, 2021. Dao et al, 2022).
이런 과정을 거쳐, 하이퍼파라메터를 최적화하였다.
학습 모델 성능 테스트
1. QA 데이터셋
학습된 모델을 이용해 제로샷(Zero-Shot. 학습 시 보지 못한 클래스 unseen class label을 맞추는 학습 방법. 학습 데이터의 라벨이 아닌 예측 데이터 특징 벡터를 학습함. 예를 들어, 고양이는 귀, 꼬리, 몸통 색상으로 구분한 특징벡터를 만들 수 있고, 이 값이 개와 다르면 고양이와 유사한 것임) 및 퓨샷(Few-Shot. 소량 학습 데이터만으로 학습하는 방식. 적은 데이터 학습을 위해 유사도 기반 학습함) 테스트를 수행하였고, BoolQ, PIQA등이 테스트에 사용되었다. 참고로, 제로샷 학습은 학습하지 않은 데이터를 이해하고, 올바른 결과를 출력하도록 학습하는 방법이다.


2. 수학 문제
Math 웹 페이지, GSM8k 데이터셋을 이용해, 수학 문제 풀이를 테스트해 보았다. 결과, GSM8k에서는 라바-65B모델이 Minerva-62B 보다 성능이 뛰어나다.

3. 코드 생성 테스트
자연어로 설명된 입력에 대한 코드 생성 성능을 테스트했다. 코드는 파이썬으로 생성된다. 결과를 보았듯이 PaLM(Google이 개발한 LLM) 모델보다 성능이 뛰어나다.
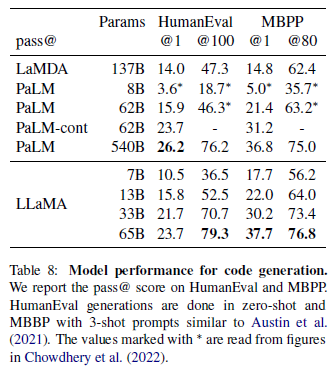
코딩 성능 결과
4. 대량 멀티태스크 언어 이해 테스트
MMLU(Hendrycks, 2020)에 의해 소개된 대량 멀티태스크 언어 이해 테스트를 수행해 보았다. 이는 인문학, STEM, 사회과학을 포함한 다양한 지식 영역을 다룬다. 라마는 ArXiv, Gutenberg, Books3를 학습하여, Gopher, Chinchilla, PaLM 와 유사하거나, 어떤 부분은 뛰어나다.

MMLU 성능
5. 기타
이외, 미세조정, 편견 테스트, 독성 언어, 종교 편향, 젠더 테스트, TruthfulQA(Lin et al, 2021), 탄소 배출(Wh = GPU-h x (GPU 소비전력) x PUE. Wu et al, 2022) 등 테스트가 수행되었다.
마무리
라마-13B는 GPT-3보다 성능이 뛰어나며, 크기는 10배 이상 작다. LLaMA-65B는 Chinchilla-70B, PaLM-540B와 거의 유사한 성능을 보인다. 학습 데이터는 공개 커뮤니티에서 수집해 사용되었다. 라마 기술은 xformers 개발 팀, 데이터 정재 팀, 학습 모델 조율팀, 페이스북 AI 인프라 팀 등 많은 사람들의 도움으로 개발되었다.

LLAMA-2
서론
라마-2는 이전 모델의 사전 훈련 결과와 미세 조정을 통해 LLM 성능을 개선한다. 라마2는 챗봇에 최적화되었고, 대부분의 오픈소스 LLM에 비해 성능이 뛰어났다.
학습 방법
라마-2는 라마-1의 미세조정을 통한 성능 개선 버전, 라마-2-Chat이란 챗봇에 특화된 버전을 다음과 같이 공개한다.
라마-2는 사전훈련 모델을 이용해 시작된다. 이어, 라마-2-챗 초기버전을 개발한다. 강화학습 환경에서 학습 모델을 반복적으로 개선한다. RLHF(Reinforcement Learning with Human Feedback), 강화학습의 PPO 정책을 통해, 반복적으로 보상 모델링 데이터를 축적하고, 이를 통해, 라마-2 모델을 개선한다. 다음 그림은 이 과정을 보여준다.

Reinforcement Learning with Human
Feedback (RLHF)
아키텍처 및 사전 훈련
아키텍터 대부분은 라마-1과 유사하다. 토크나이저도 동일한 것을 사용했으며, BPE(byte pair encoding) 알고리즘을 사용해 처리되었다. 모든 숫자는 개별 숫자로 분할하고, 알수 없는 글은 UTF-8 문자로 분리한다. 어휘 크기는 32K 토큰이다.
사전 훈련을 위해, 신뢰성있는 데이터 정리 프로세스를 수행하고, 데이터를 혼합했으며, 40% 더 증가된 데이터를 학습하였다.
토큰 컨텍스트 길이는 2배로 늘렸으며, GQA(grouped-query attention)을 사용해, 추론 성능을 개선했다.
학습 과정
학습에 사용된 것은 NVIDIA A100s이며, RoCE기반 솔류션을 사용해 GPU간 200Gbps로 데이터를 교환한다.
성능 향상을 위해 감독된 파인 튜닝(SFT)를 다음과 같이 수행하였다.

이후, 강화학습 기반 RLHF를 실행한다. 강화학습 보상 모델은 모델 응답과 프롬프트 입력을 사용해, 스칼라 점수로 모델 생성의 품질을 표현하도록 하였다. 인간의 선호도를 반영하여, 유용성과 안전성을 보상에 추가한다. 이런 이유로 보상 모델은 유용성 보상, 안전성 보상 2개로 구분되어 강화학습한다.

채팅 시 초기 명령을 잊어버리는 문제 해결을 위해 Ghost Attention(GAtt)를 사용한다. 다음은 그 결과이다.

개선된 모델
생성 결과의 안전성을 위해, 학습 과정은 RLHF로 진행된다. 이 결과, 다음과 같은 개선이 있었다.


라마-2는 다양한 방법을 통해 개선되었으나, 기본 아키텍처는 라마-1과 유사하다. 인간 감독을 포함한 강화학습기법을 사용한 것은 GPT에서 진행한 것과 동일하다. 라마-2의 챗 버전은 챗봇 서비스에 유용하다.

챗봇 성능 개선 결과 일부
결론
라마-1, 라마-2 기술 분석을 위해, 논문을 조사해, 핵심적인 내용을 정리하였다. 이를 통해, 라마 LLM을 좀 더 잘 이해할 수 있다. 라마는 Meta AI 리더인 Yann LeCun 교수의 딥러닝 민주화 철학에 영향을 받았다. 라마는 윤리적 문제 등 다양한 이해당사자들의 입장을 고려해 개발되었으며, 꾸준히 발전되고 있다.
부록: 라마2 코딩 & 코드 라마(Code LLAMA)
- LLAMA FROM SCRATCH. Meta AI and Microsoft have joined… | by Rania _Hossam | Medium
- Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNorm (youtube.com)
- hkproj/pytorch-llama: LLaMA 2 implemented from scratch in PyTorch (github.com)
- ChrisHayduk/Llama-2-SQL-and-Code-Dataset · Datasets at Hugging Face
- DominikLindorfer/SQL-LLaMA2: LLaMA-2 Finetuned for Text-2-SQL (github.com)
- Guide to prompt engineering: Translating natural language to SQL with Llama 2 (oracle.com)


부록: 라마3 코드 구조 분석
LLAMA3 코드를 역설계해 보면, 구조는 다음과 같다. 보면, 알겠지만, 일반적인 트랜스포머 구조에 몇몇 부분이 강화된 것을 알 수 있다.

페이스북 LLAMA3 아키텍처 구조
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=1)
# When performing key-value caching, we compute the attention scores
# only for the new sequence. Thus, the matrix of scores is of size
# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for
# j > cache_len + i, since row i corresponds to token cache_len + i.
mask = torch.hstack(
[torch.zeros((seqlen, start_pos), device=tokens.device), mask]
).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
라마3 모델의 생성 부분은 다음과 같다.
def generate(self, prompt_tokens: List[List[int]]) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
params = self.model.params
bsz = len(prompt_tokens)
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len <= params.max_seq_len
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
if logprobs:
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
eos_reached = torch.tensor([False] * bsz, device="cuda")
input_text_mask = tokens != pad_id
if min_prompt_len == total_len:
logits = self.model.forward(tokens, prev_pos)
token_logprobs = -F.cross_entropy(input=logits.transpose(1, 2), target=tokens,
reduction="none", ignore_index=pad_id,
)
stop_tokens = torch.tensor(list(self.tokenizer.stop_tokens))
for cur_pos in range(min_prompt_len, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
if logprobs:
token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2), target=tokens[:, prev_pos + 1 : cur_pos + 1],
reduction="none", ignore_index=pad_id,
)
eos_reached |= (~input_text_mask[:, cur_pos]) & (
torch.isin(next_token, stop_tokens)
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start : len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]
# cut to after eos tok if any
for stop_token in self.tokenizer.stop_tokens:
try:
eos_idx = toks.index(stop_token)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
except ValueError:
pass
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)
레퍼런스
- Facebook, 2023, LLaMA: Open and Efficient Foundation Language Models | Research - AI at Meta
- Medium, 2023, How to Build an AI Assistant with OpenAI & Python | by Shaw Talebi | Towards Data Science
- OpenAI, 2021, Learning Transferable Visual Models From Natural Language Supervision
- Huggin Face, 2023, LLaMA: Open and Efficient Foundation Language Models
- Facebook, Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample, 2023, LLaMA: OpenandEfficient Foundation Language Models (journal)
- Facebook, 2023, Llama 2: OpenFoundation and Fine-Tuned Chat Models
- meta-llama/llama3: The official Meta Llama 3 GitHub site
추신.
연말 연구 과제 평가 행정 대략 마무리 후, 미루고 쌓아 놓은 기술, 논문, 코드 급하게 소화 중... 회사 연구일?이 오히려 진짜 연구에 방해되는 현상은 이 바닥 사람들이라면 다 아는 팩트(굳건하게 만들어진 시스템이라 어쩔 수 없어요). 월급 받는 직딩이니 일은 제대로 하고, 남는 시간에 찐 공부, 연구, 개발할 수 밖에.ㅎ - 2.17

댓글 없음:
댓글 쓰기