이 글은 ChatGPT와 같은 생성AI 서비스 앱을 직접 개발 할 수 있는 페이스북에서 개발한 LLAMA2의 간단한 설치와 사용법을 나눔한다.

LLAMA-2 기반 자동 코딩 모습
라마 기술을 좀 더 깊게 이해하고 싶다면, 다음 링크를 참고한다.
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발
- 딥러닝 기반 3차원 스캔 데이터, 포인트 클라우드 학습
- 생성(Generative) AI 오픈소스 딥러닝 모델 Stable Diffusion, ControlNet 개념 및 ComfyUI 사용법
- 어텐션 기반 트랜스포머 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법 소개
- 트랜스포머 디코더 핵심 코드 구현을 통한 동작 메커니즘 이해하기
- LLAMA-2 논문 및 기술 분석 정리
- Computer_vision_deeplearning: computer vision based on deep learning lecture materials, github
라마-2 설치 방법
LLAMA2 설치를 위해서는 미리 아나콘다, NVIDIA CUDA, 텐서플로우, 파이토치가 설치되어 있어야 한다. 설치되지 않았다면, 다음 링크를 참고해 준비한다.
이제, 다음과 같이 터미널(명령창)을 실행한 후 명령을 입력한다.
conda create -n textgen python=3.10.9
conda activate textgen
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
pip install -r requirements.txt

정상적으로 설치되었다면, 다음 명령을 입력한다.
python server.py
그리고, http://127.0.0.1:7860/ 웹페이지를 열어본다. 다음 화면이 표시될 것이다.
모델 탭에서 다음과 같이 허깅페이스에 다른 개발자들이 업로드된 학습모델파일을 다운로드 받는다. 예를 들어, 허깅페이스 모델 URL 중 "TheBloke/Llama-2-70B-chat-GPTQ"을 다음 그림가 같이 모델 경로 입력창에 설정한다(단, 이 모델은 대용량 GPU 메모리를 사용하므로, 로딩에 실패할 경우, 좀 더 경량화된 모델을 이용해 본다).
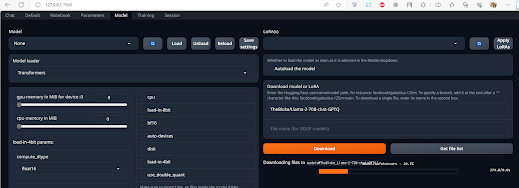

LLAMA2 모델 다운로드 모습
참고로, 다음은 GPU RAM 사용량을 함께 나타낸 학습 모델 리스트를 보여준다.

제대로 학습모델이 다운로드 후 로딩되면, 다음과 같은 화면을 확인할 수 있을 것이다.


모델 다운로드 후 모습 및 파라메터 세팅 화면
선택된 모델은 옵션으로 Transformer등을 선택할 수 있다. 이제, Load버튼을 클릭해 실행한다. 이후, Chat탭에서 프롭프트를 입력해 실행해 본다. 그럼, 다음과 같이 ChatGPT와 유사한 화면에서 생성된 텍스트를 확인할 수 있다.

콜센터같이 질문 답변 생성하는 모습

프로그램 작성 모습


생성AI 기반 코딩하는 모습
마무리
이와 같이, LLAMA-2를 잘 활용하면, ChatGPT와 유사한 서비스를 자체적으로 구축할 수 있다. 다만, 이러한 생성AI를 사용하기 위해서는 앞서 설명한 개발환경 등이 미리 준비되어 있어야 하며, 목적을 고려해 생성AI 모델을 튜닝하려는 노력이 필요하다. 아울러, 상용 서비스 앱 개발을 위해서는 라이센스를 꼼꼼히 체크할 필요가 있다.
레퍼런스
- TheBloke/Llama-2-70B-chat-GPTQ at main (huggingface.co)
- Voicelab/trurl-2-7b-8bit · Hugging Face
- LLAMA-2 Discussion
- LangChain quickstart and concepts
- How To Install LLaMA 2 Locally On Windows (lachieslifestyle.com)
- How to Install Llama 2 Locally. After the major release from Meta, you… | by Tushit Dave | Aug, 2023 | Medium
- A comprehensive guide to running Llama 2 locally - Replicate – Replicate
- facebookresearch/llama: Inference code for LLaMA models (github.com)
- LLAMA using StreamIt (streamlit.io)
- Get Started - Zapier AI Actions
- Mobile ALOHA: Your Housekeeping Robot
- How to build a Llama 2 chatbot (streamlit.io)
- (Python) Streamlit + Local LLM. Yet-Another-Code-Example for… | by Stef Nestor | Medium
- Ollama, Get up and running with large language models, locally.
- Introduction | 🦜️🔗 Langchain
- Build a Custom LLM with Chat With RTX | NVIDIA
- LiteLLM
참고: 경량 라마-2 모델
8GB이하 메모리는 TheBloke/Llama-2-7b-Chat-GPTQ · Hugging Face 를 선택해 모델을 다운로드하고, 이를 Reload한다.
참고: LLM 파인튜닝 및 데이터학습 데이터셋
라마와 같은 기존 오픈 LLM을 한국어, 특정 목적에 맞게 파인튜닝, 데이터학습하기 위해서는 LLM 개발자가 공개한 학습 데이터 형식에 맞게, 새로 학습할 데이터셋을 구축하고, 사전학습모델을 이용해 파인튜닝해야 한다.



학습 데이터 예시(한국어, 질의응답, 메뉴얼 등)
다양한 파인튜닝 목적용 LLM 데이터셋은 다음 링크를 참고한다.
- HeegyuKim/open-korean-instructions: 언어모델을 학습하기 위한 공개 한국어 instruction dataset들을 모아두었습니다. (github.com)
- heegyu/open-korean-instructions · Datasets at Hugging Face
- heegyu/aulm-0809 · Datasets at Hugging Face
- heegyu/aulm-0809 · Datasets at Hugging Face
- changpt/ko-lima-vicuna · Datasets at Hugging Face
- 64bits/lima_vicuna_format · Datasets at Hugging Face
- Bingsu/ko_alpaca_data · Datasets at Hugging Face
- junelee/sharegpt_deepl_ko · Datasets at Hugging Face
- KRAFTON/KORani-v3-13B · Hugging Face
댓글 없음:
댓글 쓰기