이 글은 허깅페이스 트랜스포머 라이브러리 사용법을 정리해본다. 이 글은 QA 시스템, 문장 분류, 토큰 의미 예측 방법 등을 소개한다. 이 글은 생성AI의 핵심 아키텍처 모델인 트랜스포머를 잘 이용하고 싶은 개발자, 연구자, 학생들에게 도움이 된다.

만약, 트랜스포머의 내부 동작 메커니즘이 궁금하다면, 다음 링크를 참고한다.
소개
허깅페이스는 트랜스포머 라이브러리를 개발하여, 관련 최신 모델을 다운로드하고, 쉽게 학습 및 사용할 수 있는 API 도구를 제공한다.
트랜스포머를 통해 다음 기능을 구현할 수 있다.
- 자연어처리: 텍스트 분류, 엔티티 인식, 질문 및 답변, 언어 모델링, 요약, 번역, 객관식 및 주관식 텍스트 생성
- 컴퓨터 비전: 이미지 분류, 객체 인식 및 세그먼테이션
- 오디오: 자동 음성 인식 및 분류
- 멀티모달: 표 해석 질문, OCR, 스캔 문서에서 정보 추출, 비디오 분류, 시각적 질문
- 사전 학습모델, 훈련 데이터셋 무료 다운로드 및 파인튜닝(Fine-tune a pretrained model, Fine-Tuning BERT using Hugging Face Transformers, How to Fine-Tune BERT for NER Using HuggingFace, Fine-Tuning the Pre-Trained bert-base-NER in Hugging Face for Named Entity Recognition (NER))


훈련 데이터셋 다운로드 제공 예(yelp_review_full · Datasets at Hugging Face)
지원되는 모델
아래 표를 보면 알겠지만, LLM(Large Language Model) 뿐 아니라 생성AI와 관련된 모든 사전 학습된 모델을 제공한다(상세 참고).
모델 구조
허깅페이스는 베이스 모델의 활용성을 높이기 위해 다음과 같이 3단계 클래스 구조를 지원한다. BERT, QWEN 모델이라면 입력에 대한 특징 출력 역할을 하는 베이스 클래스에서 파생받아 특정 목적을 지원하는 헤드를 추가해 제공하는 방식으로 모델 사용성을 확장시킨다.
수준 2에 해당하는 목적 별 활용되는 모델을 생성하기 위해 허깅페이스는 자동으로 클래스를 결정해주는 AutoModel (Auto Classes · Hugging Face) 을 지원한다. 그러므로, 베이스 모델을 파생받은 각각의 목적별 BERT, QWEN 클래스를 사용하지 않아도(예. BertForSequenceClassification.from_pretrained("...")), 자동으로 from_pretrained(모델명) 함수 호출시 모델명이 입력되면, 편리하게 필요한 모델의 클래스를 자동으로 생성해준다(팩토리 패턴과 유사하게 구현되어 있음).
이를 고려해서 클래스 구조가 다음과 같이 설계되어 있다.

클래스 다이어그램(UML)
class BertModel(BertPreTrainedModel):
...
...
class LlamaPreTrainedModel(PreTrainedModel):
class LlamaForCausalLM(LlamaPreTrainedModel):
...
라이브러리 설치 방법
이 라이브러리 사용을 위해서는 NVIDIA GPU, CUDA, PyTorch, Tensorflow 사전 설치가 필요하다.
명령행 터미널을 실행하고, 가상환경에서 다음을 입력해, 라이브러리를 설치한다.
pip install transformers[torch] datasets evaluate
설치하면, 추론 inference 등에 사용할 수 있는 파이프라인 객체를 사용할 수 있다. 파이프라인은 대부분 학습된 모델의 복잡성을 간소화한 API를 제공한다. 인식, 마스킹 언어 모델링, 특징 추출이 가능하다. 다음 코드는 그 예이다.
import transformers, torch
from transformers import pipeline
print(transformers.__version__)
print(torch.cuda.is_available())
pipe = pipeline("text-classification", model="nlptown/bert-base-multilingual-uncased-sentiment", device=0)
msg = pipe("This restaurant is awesome")
print(msg)
다음과 같이 출력되면 성공한 것이다.
트러블슈팅
현재 시점에서 텐서플로우 GPU버전은 패키지 의존성 에러가 발생한다. 참고로, pipeline에서 model과 device=0를 명시하면, 파이토치 GPU 버전으로 실행된다.
방화벽으로 인해 오프라인 환경에서 실행해야 한다면 다음과 같이 설정 후 실행한다.
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
질의 응답 자료 학습
ChatGPT와 같이 질의 응답 자료를 학습 해본다. 학습된 모델은 허깅페이스의 허브에 저장해 놓고 재활용하기로 한다. 이를 위해, 다음과 같이 허깅페이스 토큰을 생성한다.

이제, 다음과 같이 하습 데이터셋 다운로드 코딩한다.
from huggingface_hub import notebook_login # 허깅페이스 모델 업로드 위한 임포트
notebook_login()
from datasets import load_dataset # squad 데이터셋 다운로드
squad = load_dataset("squad", split="train[:5000]")
squad = squad.train_test_split(test_size=0.2)
print(squad['train'][0])
다음과 같이 토크나이저에 훈련 텍스트 입력 처리를 위해, 최대 길이를 절단하는 등의 처리 함수를 코딩한다.
from transformers import AutoTokenizer # distilbert 토큰나이저 임포트
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
def preprocess_function(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=384,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
answer = answers[i]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label it (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
데이터셋을 앞의 정의된 함수로 전처리한다. 필요하지 않은 열은 제거한다.
tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
학습을 위해 배치를 만든다.
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator()
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
model = AutoModelForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased") # 사전 학습 모델을 파인튜닝한다
training_args = TrainingArguments(
output_dir="my_awesome_qa_model",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
) # 학습될 모델 및 파라메터 명시
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_squad["train"],
eval_dataset=tokenized_squad["test"],
tokenizer=tokenizer,
data_collator=data_collator,
) # 전이학습모델, 파라메터, 데이터셋, 토크나이져, 배치처리를 위한 데이터 컬렉터 설정
trainer.train() # 학습
trainer.push_to_hub() # 학습된 데이터를 허브에 업로드
그 결과 다음과 같이 파인 튜닝된 학습 모델이 허브에 업로드되었다.
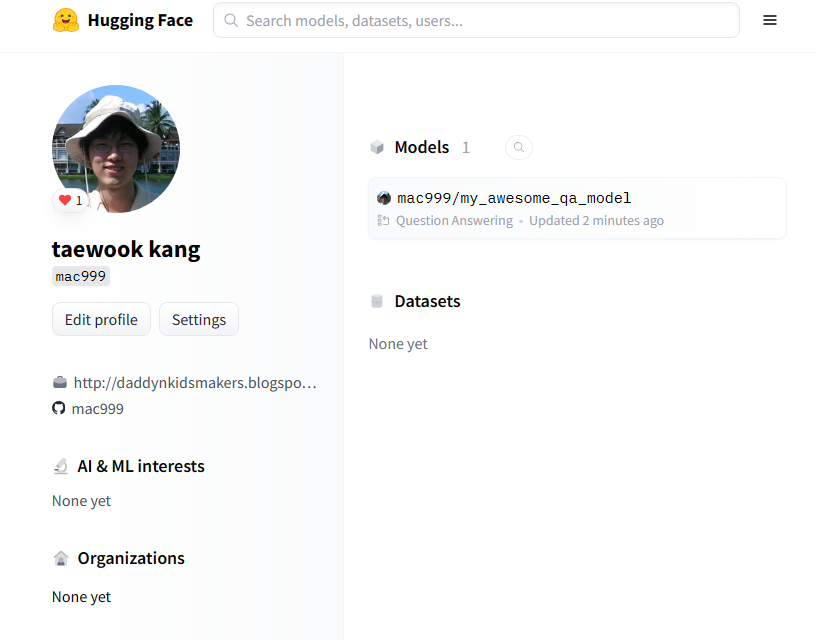
다음과 같이 실행한다.
from transformers import pipeline
question = "How many programming languages does BLOOM support?"
context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
question_answerer = pipeline("question-answering", model="my_awesome_qa_model")
question_answerer(question=question, context=context)
결과가 다음과 같다면 성공한 것이다.
NER(Named Entity Recognition) BERT 모델
각 문장의 토큰 엔티티 의미를 인식하는 모델을 NER이라 한다. 문장 토큰의 의미를 인식할 수 있다면, 문장에서 특정 토큰에 대한 의미를 알고, 해당 의미에 대한 에이전트를 자동 실행하는 등의 서비스를 쉽게 개발할 수 있다.
코드 개발 전에 다음을 설치한다.
pip install transformers[torch] datasets
이 예제는 NER 데이터셋을 다운로드하고, BERT-BASE-NER(참고) 사전학습모델을 이용해 파인튜닝할 수 있다. BERT-BASE-NER 모델 사용방법은 다음과 같다.
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
파인튜닝 데이터셋은 희귀한 토큰 의미를 정의한 데이터셋이다.

NER 의미는 다음과 같다.
Person
Location (including GPE, facility)
Corporation
Consumer good (tangible goods, or well-defined services)
Creative work (song, movie, book, and so on)
Group (subsuming music band, sports team, and non-corporate organisations)
이는 코드 상해 좀 더 상세화되어 표현되었다.
인덱스 | 태그 | 의미
0 | O | 엔터티 아님 (일반 단어)
1 | B-corporation | 기업 이름 시작
2 | I-corporation | 기업 이름 내부
3 | B-creative-work | 창작물(책, 영화, 노래 등) 시작
4 | I-creative-work | 창작물 내부
5 | B-group | 조직 또는 단체 시작
6 | I-group | 단체 내부
7 | B-location | 지명 시작
8 | I-location | 지명 내부
9 | B-person | 사람 이름 시작
10 | I-person | 사람 이름 내부
11 | B-product | 제품 이름 시작
12 | I-product | 제품 이름 내부
각 B, I, O는 Begin location, Inside location, Outside를 의미한다(NER 연구에 자주 나오는 용어). 참고로, New York City is a bustling metropolis의 NER 해석은 다음과 같다.
New: O (Outside of any named entity)
York: B-LOC (Beginning of a Location entity)
City: I-LOC (Inside of a Location entity)
is: O
a: O
bustling: O
metropolis: O
사용된 데이터셋은 다음과 같이 문장 토큰에 대한 NER이 정의되어 있다.

다음은 파인 튜닝 코드를 보여준다. 주어진 입력단어를 토큰으로 분리한 후, wnut 데이터셋으로 앞의 NER 구분이 가능하도록 모델을 튜닝한다. 시간이 있다면, 시도해 본다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
def tokenize_and_align_tags(records):
# 입력 단어를 토큰으로 분리함. 예를 들어, ChatGPT경우, ['Chat', '##G', '##PT']로 분해
tokenized_results = tokenizer(records["tokens"], truncation=True, is_split_into_words=True)
input_tags_list = []
for i, given_tags in enumerate(records["ner_tags"]):
word_ids = tokenized_results.word_ids(batch_index=i)
previous_word_id = None
input_tags = []
for wid in word_ids:
if wid is None:
input_tags.append(-100)
elif wid != previous_word_id:
input_tags.append(given_tags[wid])
else:
input_tags.append(-100)
previous_word_id = wid
input_tags_list.append(input_tags)
tokenized_results["labels"] = input_tags_list
return tokenized_results
from datasets import load_dataset
wnut = load_dataset('wnut_17')
tokenized_wnut = wnut.map(tokenize_and_align_tags, batched=True)
tag_names = wnut["test"].features[f"ner_tags"].feature.names
id2label = dict(enumerate(tag_names))
label2id = dict(zip(id2label.values(), id2label.keys()))
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
"dslim/bert-base-NER", num_labels=len(id2label), id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
)
from transformers import Trainer, TrainingArguments, DataCollatorForTokenClassification
training_args = TrainingArguments(
output_dir="my_finetuned_wnut_model",
)
# 하이퍼파라메터 튜닝용
training_args = TrainingArguments(
output_dir="my_finetuned_wnut_model_1012",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_wnut["train"],
eval_dataset=tokenized_wnut["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
from transformers import pipeline
model = AutoModelForTokenClassification.from_pretrained("my_finetuned_wnut_model/checkpoint-1000")
tokenizer = AutoTokenizer.from_pretrained("my_finetuned_wnut_model/checkpoint-1000")
classifier = pipeline("ner", model=model, tokenizer=tokenizer)
out = classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
print(out)
import evaluate
seqeval = evaluate.load("seqeval")
results = trainer.evaluate()
print(results)
trainer.push_to_hub()
참고로, 이 코드를 실행하면 결과는 다음과 같다.

다음과 같이 문장 각 토큰의 의미(예. 사람, 위치 등)를 높은 정확도로 제공해 준다.

마무리
이 글은 허깅페이스 트랜스포머를 이용해 다양한 사전학습 모델을 이용해 여러가지 서비스 개발 방법을 살펴보았다. 자체 데이터로 학습하거나, 데이터 학습을 좀 더 많이 할 수록 결과가 더 정확하고, 전문적이며, 풍부해 질 것이다.
레퍼런스
- Question answering (huggingface.co)
- Agents & Tools (huggingface.co)
- Fine-tune a pretrained model (huggingface.co)
- Fine-Tuning BERT using Hugging Face Transformers (learnopencv.com)
- How to Fine-Tune BERT for NER Using HuggingFace (freecodecamp.org)
- Fine-Tuning the Pre-Trained bert-base-NER in Hugging Face for Named Entity Recognition (NER) | by Yuan An, PhD | Medium
- medium/src/working_huggingface/Working_with_HuggingFace_ch2_Preparing_Dataset_for_Fine_Tuning_NER_Model.ipynb at main · anyuanay/medium (github.com)
- pankajmathur/orca_mini_v2_7b · Hugging Face
- RunPod GPU Cloud
참고: OCR 인식 및 정보 추출
이미지나 문서와 같이 비정형 데이터에서 OCR을 지원하는 유용한 라이브러리는 다음과 같다.
- tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)
- PaddlePaddle/PaddleOCR: Turn any PDF or image document into structured data for your AI. A powerful, lightweight OCR toolkit that bridges the gap between images/PDFs and LLMs. Supports 100+ languages.

참고: 그래프, 그래픽, 기하학 데이터셋



CADTransformer (CADTransformer_Panoptic_Symbol_Spotting_Transformer_for_CAD_Drawings)

Shape Transformer Architecture (Robust 3D Reconstruction from Three Orthographic Views with Learnt Shape Programs)

댓글 없음:
댓글 쓰기