이 글은 생성AI의 핵심인 딥러닝 모델 트랜스포머(Transformer) 구현 메커니즘을 코드 수준에서 이해하기 위해, 트랜스포머의 작동 과정을 상세히 설명합니다. 그리고, 트랜스포머를 실제로 동작하는 코드를 예시하고 실행해 봅니다.
이 과정을 통해, 텍스트 번역기 등 앞뒤 문맥 관계가 있는 딥러닝 모델을 직접 개발하거나, 이와 유사한 멀티모델 데이터 스트림을 다른 형식으로 변환(트랜스폼)시킬 수 있는 스테이블 디퓨전(Stable Diffusion)같은 생성AI 모델을 개발할 수 있습니다. 실제, 트랜스포머는 텍스트에서 비전, 음성, 비디오 데이터로 맵핑하는 주요 컴포넌트 중 하나로 사용된다.

트랜스포머 인코더-디코더 모델 적용된 생성 AI 멀티모달 Stable Diffusion 모델(Generative AI Models in Image Generation: Overview - Synthesis AI)
이 글에서 표시된 트랜스포머 내부 실행 소스 코드는 다음 링크에서 다운로드할 수 있다.
- Github - transformer (github.com)
딥러닝 및 컴퓨터 비전에 대한 개념은 다음 링크를 참고한다.
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발
- 딥러닝 기반 3차원 스캔 데이터, 포인트 클라우드 학습
- 생성(Generative) AI 오픈소스 딥러닝 모델 Stable Diffusion, ControlNet 개념 및 ComfyUI 사용법
- Computer_vision_deeplearning: computer vision based on deep learning lecture materials, github
이 글은 많은 레퍼런스들을 참고해, 가능한 트랜스포머 동작방식을 이해하기 쉽도록 정리한 것이다. 관련해 궁금하다면, 이 글 마지막에 있는 레퍼런스들을 살펴보길 바란다.
머리말
트랜스포머 동작 개념
트랜스포머는 구글 연구팀이 구글 번역기 성능 개선을 위해 개발한 딥러닝 기술로써 Attention Is All You Need 논문을 통해 널리 알려진 딥러닝 모델이다. 트랜스포머는 입력 데이터 토큰들과 출력 데이터 토큰들 간의 순서 관계를 통해, 서로의 유사성을 계산한다(예. 영어 문장 > 독일어 문장).
이는 각 소스 언어(영어), 목표 언어(독일어)를 구성하는 문장의 관계가 유사하도록 계산하는 가중치를 찾는 것이 문제가 된다. 즉, 아래 문장은 언어 유사도 차원 공간이 있다면, 그 공간에서 다른 문장들보다 가장 가까운 곳에 위치되어야 한다.
I like her.Ich mag sie.나는 그녀를 좋아한다.
이 문제를 풀기 위해서는 각 언어의 문장을 구성하는 단어 간의 관계(문법)을 계산해야 한다. 즉, 다음과 같은 문장은 문법 관점에서 유사도가 크다. 단어 간의 관계를 계산하면, 특정 단어의 다음 단어를 확률적으로 예측할 수 있다.
I like her.I like him.I like you.
트랜스포머 모델은 특정 토큰 다음에 어떤 토큰이 올 지에 확률적으로 초점을 맞추는 어텐션 개념을 수학적 모델로 제안하였다. 어텐션은 우리가 말을 하면서, 특정 정보에만 집중하는 것을 흉내낸다. 어텐션은 MLP를 유사도 개념으로 확장한 구조와 비슷하다. 즉,
소스 문장 > MLP(문장 토큰 패턴 학습) > 대상 문장
소스 문장 > 어텐션(문장 토큰 관계 패턴 학습) > 대상 문장
트랜스포머는 순서가 있는 데이터 토큰의 예측, 생성, 비교 과정을 수학적으로 일반화한 확률 통계 모델이므로, 데이터 종류에 구애받지 않는다. 이 특징을 활용해, 트랜스포머는 멀티모델 생성AI 기술로 사용될 수 있었다.
트랜스포머는 다음과 같은 기존 RNN(Recurrent Neural Network), LSTM(Long Short Term Memory)와 같은 Seq2Seq 모델들의 단점을 해결하고자 했다. Seq2Seq 모델의 구조는 일반적으로 다음과 같다.
- 인코더 인닉상태 가중치 초기화
- 모델에 매 시점마다 단어 토큰과 다음 토큰이 라벨링으로 입력 학습, 은닉 상태 갱신
- 앞의 학습 단계 계속 반복
- 최종 학습 시점의 인코더 은닉 상태인 문맥 벡터(Context vector)를 얻어, 디코더에 설정
- 디코더가 새로운 단어 토큰들을 입력받아, 문맥 벡터로 계산해, 출력을 생성함

Seq2Seq 모델은 태생적으로 다음과 같은 한계가 있다.
- 재귀적으로 학습하므로 계산 속도가 느리다. 각 시점 별로 계산된 은닉 상태를 메모리로 가지고 있어, 역전파 시 메모리를 읽어 Loss를 감소시키는 방향으로 가중치를 수정해야 한다. 입력된 데이터를 병렬로 학습할 수 없을까?
- 재귀적으로 학습하므로, 현재보다 먼 앞의 시점에서 학습된 가중치가 뒤에서 학습된 결과에 의해 희미해질 수 있다. 이런 이유로, 데이터 토큰의 전체 관계를 학습하기 어렵다. 학습 시 전체 데이터를 볼 수 없을까?
트랜스포머는 이 문제를 포지션 인코딩, 멀티헤드 어텐션으로 해결한다. 다음은 Google 연구팀이 펴낸 논문에 기술된 트랜스포머 개념도를 보여준다.

이 그림을 보면, 트랜스포머 모델은 Seq2Seq와 유사하게, 인코딩과 디코딩 네트웍으로 나눠진다. 영어 > 프랑스어 다국어 번역의 경우, 트랜스포머의 인코더는 영어의 문맥을 학습하고, 디코더는 번역될 프랑스어 텍스트를 입력받아 인코더에서 학습된 문맥을 바탕으로 프랑스어를 생성하는 역할을 한다.
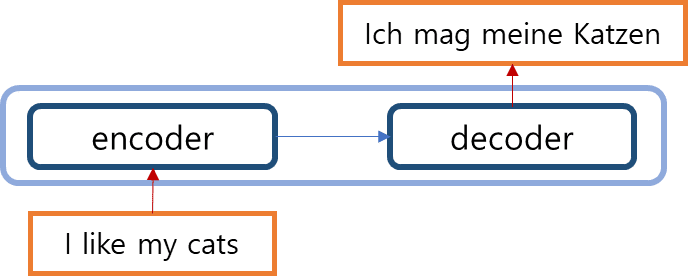
자연어 번역 시 인코딩 디코딩 과정 예시 (영어 > 독일어 번역)
즉, 핵심적인 질문은
다음과 같은 입력 스트링이 있을 때,
각 단어 간의 관계(문법)를 어떻게 계산하여,
문자열의 특정 위치에 특정 단어가 왔을 때,
그 다음에 올 단어를 예측하는 가
이다.
I like my cats.I like my dog.I am student.You are student.My cats are cute.My dog is big.
이 학습 데이터에서 입력 단어들의 순서는 예측 단어 간의 강한 관계성을 가져야 한다. 이를 어텐션이라 한다. 예를 들면,
I like > my(0.8), cats(0.5), dog(0.5), teacher(0.3)...
이렇게 어텐션 점수가 계산되어야, 그들의 관계(문법)을 학습하게 되는 것이다(예. 주어+동사+목적어 명사).
그렇다면, 모든 학습 데이터를 배치로 만들어, 배치 내 입력 텍스트 단어들 간의 유사도가 가까운 방향으로 학습시켜 나가면 될 것이다.
이를 위해, 단어는 유일한 토큰값으로 임베딩해야 한다.
토큰 간의 순서를 학습 시 고려해야, 토큰의 위치가 달라질 때 이를 고려해 다음 토큰이 계산될 수 있는 어텐션을 계산할 수 있을 것이다. 예를 들어,
I like my cats.My cats are cute.
에서, my cats은 그 위치에 따라 예측 토큰값이 달라져야 한다. 즉, My cats이 문자열 첫번째 부터 존재할 때는 그 다음 토큰은 'are'가 되어야 한다. 이 결과 토큰 위치에 따른 예측 토큰 간의 관계(문법)이 학습되도록 한다.
즉, (I like my cats. I like my dog.) 는 서로 간의 유사도 크게 어텐션되도록 학습되고, 앞의 문법과는 다르게 (My cats are cute. My dog is big.)는 유사한 관계를 가진 텍스트 안에서만 유사도가 높게 학습되도록, 입력되는 학습 데이터를 만들면 된다. 이것이 셀프 어텐션을 수학적으로 개발하게 된 이유가 된다.
모든 학습 텍스트의 토큰값과 위치에 대한 유사도가 가깝게 되도록 어텐션 점수를 계산하게 되므로, 결국, 텍스트의 문법(패턴)을 학습하게 되는 원리다.
이제, 토큰 간의 관계를 학습했으므로, 소스 언어(한글)를 목표 언어(영어)로 생성해야 한다. 이는 유사한 원리로, 목표 언어를 같은 입력 학습 텍스트에 대해 어텐션 값을 계산(KV)하고, 다만, 소스 언어의 학습 텍스트 토큰 별 어텐션 계산 값(Q)을 함께 고려해, 유사도 차이가 없는 방향으로 가중치를 조절해 나가면 된다.
목표 언어가 한글일 때 어텐션 계산된 값은 다음과 같아야 한다. 즉
나는 > 나의(0.7) > 고양이(0.6)를, 개(0.6)를 > 좋아한다.
이는 앞에서 계산된 셀프 어텐션값과 비교된다.
I like > my(0.8), cats(0.5), dog(0.5), teacher(0.3)...
소스 언어와 목표 언어의 각 텍스트를 구성하는 토큰들의 어텐션 점수는 특정 문법 관계에서는 유사하게 가까워야 맞을 것이다. 이렇게 셀프 어텐션 계산된 소스 언어와 목표 언어의 관계를 둘 다 고려해, 가중치를 조정하여 유사도를 높게(양쪽 텍스트간 거리를 가깝게) 학습하는 것을 크로스 어텐션이라 한다.
소스와 목표 텍스트 토큰 간 관계를 서로 유사하게 학습하도록 알고리즘을 설계한 것이 트랜스포머의 핵심 개념이다.
트랜스포머 단계별 알고리즘
인코딩의 각 단계를 간략히 확인해 보자.
- Input Embedding: 입력 데이터를 토큰으로 구분하고 임베딩한다. 이를 통해, 비정형적인 텍스트를 디지털 계산이 가능한 숫자로 표현된 고유한 임베딩 벡터값으로 표현한다. 임베딩 벡터는 임베딩 공간에 표현된다. 예를 들어, 입력 데이터 모양이 (배치크기, 문자열 길이)라면, (배치크기, 문자열 길이, 임베딩 차원)으로 확장된다. 이는 문자열 토큰 수 x 임베딩 차원수인 2차원텐서로 표현된다. 예. x.shape = (배치, 문자열길이, 임베딩차원) = (30, 200, 512)
- Positional Encoding: 변환된 임베딩 벡터는 앞뒤 순서가 포함되어 있지 않다. 하지만, 문장을 구성하는 단어는 순서가 있으며, 이 순서에 따라, 따라올 다음 단어가 결정된다. 그러므로, 단어의 순서를 표현하는 위치 벡터를 계산해, 임베딩 벡터에 더해준다.
- Multi-Head Attention: 앞에서 특정 단어 A가 존재할 때, 그 다음 특정 단어 B가 존재할 확률을 계산한다. 이 확률은 트랜스포머 모델이 A가 여러 단어 중 B를 선택(어텐션. Attention)하는 방법을 알려준다. 이를 위해, 앞에서 입력된 임베딩 벡터를 8개(구글 논문에서 사용한 숫자)의 Multi-Head 벡터로 나눈다. 이를 통해, 입력 학습 데이터의 여러 문자열을 고려한 유사도 확률 계산이 되도록 한다. 임베딩 벡터는 다시 Query, Key, Value (QKV)벡터로 복사해 분할된다. 여기서, Query는 주의를 기울이고 싶은 것(검색어. 디코더의 출력값), 검색 결과는 Value, Key는 Query와 함께 생성될 토큰의 확률을 계산할 때 제공되는 벡터값이다. Query와 Key는 Value값을 얻도록 벡터 간 유사도를 계산해야한다. Value 벡터는 입력 학습 시퀀스를 구성하는 토큰의 관점에서 유사도를 얻도록한다. V벡터를 통해, (토큰 종류 x 토큰 종류) 크기 만큼의 어텐션 행렬을 GPU메모리에서 계산할 필요가 없게 된다(일종의 트릭). QK계산은 코사인(cosine) 벡터 유사도 함수 계산으로 해결한다. 이는 어텐션 수식으로 표현되며, 이후에 자세히 설명할 것이다.
- Add & Normal: 신경망 역전파 시 그레디언트 감쇄 문제를 해결하기 위해, 잔차 연결과 정규화를 수행한다.
- Forward Feedback: 단순히 포워드 신경망을 연결해, 가중치를 계산한다.
- Add & Normal: 4번 단계와 동일하다.
- 최종 출력은 Key, Value로써 디코더의 Multi-Head Attention에 입력한다. Q는 디코더 결과값으로 입력된다.


디코딩 처리 단계는 번역할 문장(예. 독일어)의 단어 토큰을 예측하도록 목표 텍스트를 오른쪽토큰으로 이동(shifted right)한 후, 임베딩과 유사하게 수행된다.
- Output Embedding: 입력 데이터를 토큰으로 구분하고 임베딩한다.
- Positional Encoding: 단어의 순서를 표현하는 위치를 인코딩해, 임베딩 벡터에 포함해준다.
- Masked Multi-Head Attention: 디코딩에서는 다음 단어가 예측되도록, 앞의 단어 임베딩 벡터에 해당하는 계산은 Mask 처리해야 한다. 입력된 인코딩 벡터를 8개의 Multi-Head 벡터로 나누고, 다시 Query, Key, Value 벡터로 나누어, 어텐션을 코사인 벡터 유사도 함수 계산으로 해결한다.
- Add & Normal: 잔차 연결과 정규화를 수행한다.
- Multi-Head Attention: 인코더 출력은 Key, Value 값으로 디코더 Multi-Head Attention에 입력한다. Q는 앞에서 출력을 입력한다.
- Add & Normal: 잔차 연결과 정규화를 수행한다.
- Forward Feedback: 포워드 신경망을 연결해, 가중치를 계산한다.
- Add & Normal: 6번 단계와 동일하다.
- Linear: 선형 레이어로 가중치를 계산한다.
- Softmax: 과거 토큰 A에 대한 미래 토큰 B의 확률을 얻기 위해, softmax를 적용한다. 예. out.shape = (배치, 문자열길이, 토큰 길이) = (30, 200, 125). 그러므로, loss는 labels (30, 200) - out가 된다.
- 단어 예측 결과를 출력한다.
다음은 이 과정을 좀 더 자세히 살펴보기 위해 코드 개발 수준에서 살펴본다.
데이터 인코더 처리 메커니즘
Input Embedding
트랜스포머는 주어진 데이터를 토큰으로 분할해, 다음 토큰이 출현하는 확률을 계산한다. 예를 들어, 'I like my cats'라는 문장이 있다면 다음과 같이 토큰으로 이를 분할한다.

토큰화된 후 다차원 기하학적 공간에 각 토큰을 투영한다. 이를 임베딩(embedding)이라 한다. 임베딩은 텍스트를 숫자 벡터로 변환하는 방법이다.

임베딩은 주어진 문자열을 큰 벡터 크기로 표현하는 one-hot 인코딩 벡터 방식보다 작고 효율적인 벡터를 만드는 워드 임베딩(Word Embedding)을 사용한다. 이 임베딩 방식은 주어진 문장을 계산, 비교하기 편리하다(입력 데이터 특성에 따라 임베딩 방식은 달라질 수 있음). 워드 임베딩은 word2vec로 알려져 있다. 이는 문장을 구성하는 각 단어를 one-hot 인코딩 벡터로 입력하고, 출력을 각 단어의 위치로 라벨링한 간단한 신경망을 사용한다. 이 신경망의 결과값이 임베딩 벡터가 된다.

word2vec를 이용한 임베딩 벡터 계산 과정은 다음과 같다.

이를 통해, 각 토큰은 다차원 공간에서 고유의 위치를 갖게 되므로, 이 위치 특징을 사용해, 다른 토큰 간의 거리 등을 수학적으로 계산할 수 있게 된다. 참고로, 이런 이유로 멀티모달 데이터(텍스트, 이미지, 음성 등) 간 비교, 거리 계산, 생성 시 임베딩은 필수적으로 사용된다.

영어와 독일어 임베딩 벡터 차원 공간 표현(위치와 거리 비교 계산이 가능함에 주목. Jaron Collis, 2017)
이 글에서 임베딩 처리는 다음과 같이 파이토치에 내장된 Embedding 모듈을 사용한다.
self.embedding = nn.Embedding(self.vocab_size, d_model)
구글 논문에서 임베딩 벡터 크기는 텍스트에서 제일 큰 길이의 문장을 고려해 512로 설정되어 있다. 이는 하이퍼파라메터이다. 임베딩 벡터는 다음 그림과 같이, Self-Attention에 입력되어, Feed Forward 로 전달된다.

임베딩 벡터 입력 흐름
여기서 주목할 점은 각 단어 임베딩 벡터가 병렬로 처리될 수 있다는 점이다. 그럼, 각 단어 간 문맥 파악을 위한 위치 순서는 어떻게 입력해야 하는 지 문제가 발생한다. 이는 다음 설명될 Positional Encoding 에서 처리된다.
Positional Encoding
입력된 토큰에서 계산된 임베딩 벡터는 각 토큰의 전후 관계와 맥락을 학습할 수 없다. 그러므로, 다음 식과 같은 포지션 인코딩을 통해, 각 토큰의 위치를 앞뒤 관계의 특징을 추가하는 위치 벡터를 얻는다. 이 위치 벡터는 입력되는 토큰의 순서를 유일하게 보장할 수 있다.

여기서, i = 차원 인덱스
d_model = 임베딩 길이
pos = 시퀀스 내에서 단어의 위치
참고로, 트랜스포머 아키텍처는 기존 텍스트 번역에 사용되었던 RNN 재귀 학습 기법을 사용하지 않고, Positional Encoding와 다음에 설명할 Multi-Head attention을 사용해 병렬처리를 가능하게 함으로써 학습 시간을 크게 개선했다.
우선, 입력되는 데이터 스트림에 순서를 부여하기 위해서는 문장에서 해당 단어의 위치에 대한 정보를 각 단어에 추가해야 한다. 예를 들어, [0, 1] 범위 내에서 각 시간 순서에 맞게 숫자를 할당하는 것인데, 여기서 0은 첫 번째 단어를 의미하고 1은 마지막 시간 단계를 의미한다. 매우 긴 문장에서도 이 문제를 해결할 수 있도록, sin(), cos() 함수를 이용해 주파수 값을 각 입력 토큰의 고유 순서로 할당한다. 이에 대한 자세한 사항은 여기를 참고한다.
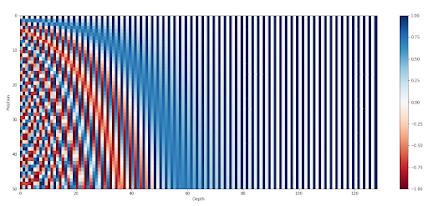
최대 길이 50인 문장에 대한 128차원 위치 인코딩 결과(각 행은 임베딩 벡터를 나타냄. Amirhossein Kazemnejad)
다음은 이를 구현한 것이다. 여기서, d_model은 임베딩 벡터 공간의 차원수로 논문에서는 512값란 사용하지만, 쉬운 이해를 위해 6을 입력하겠다. max_sequence_length는 문장 최대 시퀀스 크기이다.
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_sequence_length):
super().__init__()
self.max_sequence_length = max_sequence_length
self.d_model = d_model
def forward(self):
event_i = torch.arange(0, self.d_model, 2).float()
denominator = torch.pow(10000, event_i /self.d_model)
position = torch.arange(self.max_sequence_length).reshape(self.max_sequence_length, 1)
even_PE = torch.sin(position / denominator) # 사인함수로 위치 인코딩
odd_PE = torch.cos(position / denominator) # 코사인함수로 위치 인코딩
stacked = torch.stack([even_PE, odd_PE], dim=2)
PE = torch.flatten(stacked, start_dim=1, end_dim=2)
return PE
pe = PositionalEncoding(d_model=6, max_sequence_length=10)
PE = pe.forward()
print(PE)
Self-Attention & Multi-Head Attention
앞의 단어에 대한 다음 단어를 예측하도록, 셀프 어텐션(Self-Attention) 계산 모델을 구현해야 한다. 예를 들어, 입력된 데이터 토큰을 다음과 같이 변환하는 모델을 개발해야 한다고 하자.
Hello I love you > 안녕, 나는 너를 사랑해
이 경우, 이 변환모델은 Hello의 경우, '안녕', '나는', '너를', '사랑해' 토큰 중에 '안녕'에 초점을 맞춰, '안녕'이란 토큰을 리턴해야 한다. 그러므로, 어떤 토큰이 입력되면, 어떤 토큰값을 출력해야 하는 지를 정의해야 한다. 이를 행렬로 나타내면 다음과 같다.
Hello I love you

이 행렬의 가로와 세로는 토큰을 의미한다. 각 토큰이 다른 어떤 토큰에 초점을 맞추는 지가 확률로 정의된다. 이 예에서, 첫 행의 경우, 토큰 'I'에 초점을 맞추는 것을 확인할 수 있다. 이 어텐션 개념은 RNN, LSTM 문제점을 개선하려는 의도에서 개발되었다.

주어진 문장에서 어텐션 예시(적색 표시는 현재 단어 토큰, 청색은 주의 집중되어 활성화되는 토큰을 표현. Long Short-Term Memory-Networks for Machine Reading, 2016)
특정 토큰이 초점을 맞추는 확률을 계산을 위해, Google 트랜스포머 논문에서는 이 어텐션 개념을 사용한다.

여기서, Q = Query (what I'm looking for). 질의어. 디코더의 출력값
K = Key (what I can offer). 토큰 간 관계 유사도 계산을 위해 Query와 비교할 때 사용됨
V = Value (what I actually offer). Query, Key에 대한 최종 출력으로 관계성 계산에 사용. 이를 통해, 어텐션 계산 행렬 크기가 입력 시퀀스 구성하는 토큰 갯수만 GPU메모리를 사용하게 되어, 최적화되는 효과를 얻음
dk = k 벡터의 차원
M = Mask (미래 데이터 토큰만 학습데이터로 고려함)
Query는 디코더에서 포지션 인코딩한 벡터값이 입력된다. 이 값은 트랜스포머의 Self-attention 처리를 위해 Key, Value는 인코더의 포지션 인코딩한 벡터를 이용한다. 이때, 다음의 어텐션 계산에 따른 유사도가 가까워지도록 학습되도록, Q, K, V는 신경망 레이어로 정의한다.
결국 이 어텐션 함수는 손실함수와 유사한 역할을 하나, 입력 데이터 토큰들 간의 유사도를 통한 관계성 계산에 집중한다. 어텐션 함수는 앞서 임베딩 토큰들이 입력되는 Q, K, V 레이어 가중치를 조정하게 되는 기준치(유사도)를 제시하는 역할을 한다.
입력된 쿼리 Q에 대한 다른 토큰들과 유사도(초점을 맞춰야할 토큰)을 계산하기 위해, 다음 그림과 같이 입력되는 모든 토큰에 대해 하나의 키, 값 벡터를 가지게 된다.

Q, K, V 벡터의 어텐션 계산 개념
이 어텐션 수식에 의해, 학습과정을 반복하면, 생성될 토큰을 가리키는 어텐션 스코어(attention score)가 계산되도록 해야 한다. 참고로, 어텐션 스코어는 다음 그림과 같이, 특정 토큰 뒤에 생성될 토큰을 가리키는 확률 행렬로 구성되며, 앞의 어텐션 수식을 모두 계산한 후 얻을 수 있다.

어텐션 확률 스코어 매트릭스 예
어텐션 수식에서 어텐션 스코어는 유사도에 따라 계산되어야 한다. 이는 수식에서 QK^T 이 담당한다. Q, K, V의 학습 가중치를 계산하기 위해, Value가 주어진다. QK 벡터 간 곱은 cosine 함수를 사용한다. cosine 함수의 출력 θ는 두 입력 벡터가 주어졌을 때, 서로 가까울수록 1.0에 가까워지고, 멀수록 -1.0에 가까워진다.

임베딩 벡터 차원에서 각 토큰과 cosine 유사도 거리 예
어텐션 스코어를 계산한 후, 가중치 계산 시 특정 입력 신호의 그레디언트 소멸 문제를 개선하기 위해 SQRT(d_k) 값으로 정규화처리한다.
문장 번역은 과거의 데이터를 입력받아, 미래의 문장을 생성해야 하므로, 과거에 대한 가중치는 마스크 처리해야 한다. 아울러, 텐서 행렬 계산을 위해, 동일한 형태로 문장을 임베딩 벡터로 변환해 계산하므로, 학습하지 않아야 할 공백 문자열 부분은 Padding 마스크로 처리해야 한다.

타겟 마스크(target mask)

이를 구현하면 다음과 같다.
import numpy as np
import math
L, d_k, d_v = 4, 8, 8 # my name is tom
q = np.random.randn(L, d_k) # what I am looking for
k = np.random.randn(L, d_k) # what I can offer
v = np.random.randn(L, d_v) # what I actually offer
def softmax(x):
return (np.exp(x).T / np.sum(np.exp(x), axis=-1)).T
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.shape[-1]
scaled = np.matmul(q, k.T) / math.sqrt(d_k) # QK^T / sqrt(d_k)
if mask is not None:
scaled = scaled + mask # considering future predition token
attention = softmax(scaled)
# softmax(QK^T / sqrt(d_k) + M)V
out = np.matmul(attention, v) # QK^T
return out, attention
# masking. to ensure words can only attend to previous words. dont't look at future words
mask = np.tril(np.ones([L, L])) # lower triangular matrix
print(mask)
values, attention = scaled_dot_product_attention(q, k, v, mask=None)
print('Q\n', q)
print('K\n', k)
print('V\n', v)
print('New V\n', values)
print('Attention\n', attention)
앞의 Self-Attention 모델을 이용해 주어진 입력에 대한 출력을 생성한다면, softmax 함수를 이용할 것이다. 하지만, 이 경우, 단일 Self-Attention 네트워크로 인한 다양한 문맥에 따른 출력을 생성하지 못하는 문제가 있다.
이 문제를 해결하기 위해, 트랜스포머 모델은 QKV 텐서를 몇개로 복사해 각각 별도로 학습 계산한다. 이를 멀티헤드 어텐션이라 한다. 이를 통해, 각 입력 토큰은 앞서 입력된 토큰들의 다양한 관계 조합에 따른 출력 토큰이 생성될 수 있도록 한다.
예를 들어, 'Hello I love you'를 그대로 변환해 '안녕 나는 사랑해 너를'로 생성하지 않고, '나는 너를 사랑해'라고 출력해야 한다. 또한, 'Hi, I love game like Matrix' 로 입력하면, '나는 매트릭스같은 영화를 좋아해'를 생성해야 한다. 즉, love와 같은 단어 토큰의 의미는 문맥에 따라 달라져야 한다.
또한, 'which do you like dog or cat' 에서 어텐션하는 단어도 다양할 수 있다. which가 dog나 cat에 집중할 수도 있고, you가 like에 집중될 수도 있다. 이는 주어지는 문장들에 따라 달라질 수 있어야 한다. 이렇게 유사하지만, 문맥 관계에 따라 가변적인 의미를 어텐션할 수 있도록, 어텐션 레이어 한 개 만 사용하지 않고, 여러 개로 분할해 가중치를 학습한다. 그 결과 벡터는 concatenate 함수를 이용해 단순 결합한다. 논문에는 다음과 같이 수식으로 표시되어 있다.

멀티헤드 어텐션 수식(Google)
이 과정을 모두 거치고 나면, 인코더에 입력되는 텍스트 토큰들의 상호 관계를 유사도 기반으로 계산된 어텐션 스코어를 출력하는 가중치 모델을 얻게 된다. 이 가중치 데이터셋은 Query로 값을 검색하는 데 사용되는 일종의 데이터베이스 역할을 한다.

이제, 입력 임베딩 벡터를 멀티헤드로 나누어, QKV 텐서를 계산한다. 참고로, 논문에서 멀티헤더 수는 8로 고정되어 있다.
import io, math, numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
def scaled_dot_product(q, k, v, mask=None):
d_k = q.shape[-1]
scaled = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k) # QK^T / sqrt(d_k)
if mask is not None:
scaled += mask # considering future predition token
attention = F.softmax(scaled, dim=-1)
values = torch.matmul(attention, v) # QK^T
return values, attention
class multihead_attention(nn.Module):
def __init__(self, input_dim, d_model, num_heads):
super().__init__()
self.input_dim = input_dim
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads # 멀티헤드 수 만큼 나눔
self.qkv_layer = nn.Linear(input_dim, 3 * d_model) # QKV 벡터 가중치 계산 레이어
self.linear_layer = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, sequence_length, input_dim = x.size()
print(f'x.size(): {x.size()}')
qkv = self.qkv_layer(x) # QKV 레이어 가중치는 아래 QKV 유사도에 따라 학습됨
qkv = qkv.reshape(batch_size, sequence_length, self.num_heads, 3 * self.head_dim)
qkv = qkv.permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=-1)
values, attention = scaled_dot_product(q, k, v, mask) # QKV 유사도 계산
values = values.reshape(batch_size, sequence_length, self.num_heads * self.head_dim)
out = self.linear_layer(values)
return out
input_dim = 1024
d_model = 512
num_heads = 8
batch_size = 30
sequence_length = 5
x = torch.randn((batch_size, sequence_length, input_dim))
model = multihead_attention(input_dim, d_model, num_heads)
out = model.forward(x)
print(out)
실행 결과는 다음과 같다.


멀티헤드 어텐션 계산 결과 일부
Add & Normal
딥러닝 신경망은 학습을 계속할 수록 가중치를 조정하는 기울기값이 감쇄하는 현상이 있다. 이를 방지하기 위해, 잔차연결(Residual Connection)으로 이전 레이어의 출력값과 멀티헤드 계산된 결과의 출력값을 더한다. 이는 기존에 사용된 ResNet 개념을 재활용한 것이다.

ResNet 네트워크(wikipedia)
아울러, 레이어의 특정 유닛에 편중된 학습이 되지 않도록, 레이어의 가중치 평균이 0이 되도록 가중치 정규화를 수행한다.
다음은 이를 구현한 것이다.
import torch
from torch import nn
class LayerNormalization():
def __init__(self, parameters_shape, eps=1e-5):
self.parameters_shape = parameters_shape
self.eps = eps
self.gamma = nn.Parameter(torch.ones(parameters_shape))
self.beta = nn.Parameter(torch.zeros(parameters_shape))
def forward(self, inputs):
dims = [-(i + 1) for i in range(len(self.parameters_shape))]
mean = inputs.mean(dim=dims, keepdim=True)
print(f'Mean size: {mean.size()}, Mean: {mean}')
var = ((inputs - mean) ** 2).mean(dim=dims, keepdim=True)
std = (var + self.eps).sqrt()
print(f'std size: {std.size()}, std: {std}')
y = (inputs - mean) / std
print(f'y size: {y.size()}, y: {y}')
out = self.gamma * y + self.beta
print(f'out size: {out.size()}, out: {out}')
return out
batch_size = 3
sentense_length = 5
embedding_dim = 8
inputs = torch.randn(sentense_length, batch_size, embedding_dim)
print(f'inputs size: {inputs.size()}, inputs: {inputs}')
layer_norm = LayerNormalization(parameters_shape=(embedding_dim,))
out = layer_norm.forward(inputs)
print(f'out size: {out.size()}, out: {out}')
Encoder 전체 구현
다음 그림은 이 전체 계산 과정을 간략히 보여준다.

트랜스포머 인코더 계산 과정
다음 코드는 인코더를 구현한 것이다.
import torch
import math
from torch import nn
import torch.nn.functional as F
def scaled_dot_product(q, k, v, mask=None):
d_k = q.size()[-1]
scaled = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k)
print(f"scaled.size() : {scaled.size()}")
if mask is not None:
print(f"ADDING MASK of shape {mask.size()}")
# Broadcasting add. So just the last N dimensions need to match
scaled += mask
attention = F.softmax(scaled, dim=-1)
values = torch.matmul(attention, v)
return values, attention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.qkv_layer = nn.Linear(d_model , 3 * d_model)
self.linear_layer = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, max_sequence_length, d_model = x.size()
print(f"x.size(): {x.size()}")
qkv = self.qkv_layer(x)
print(f"qkv.size(): {qkv.size()}")
qkv = qkv.reshape(batch_size, max_sequence_length, self.num_heads, 3 * self.head_dim)
print(f"qkv.size(): {qkv.size()}")
qkv = qkv.permute(0, 2, 1, 3)
print(f"qkv.size(): {qkv.size()}")
q, k, v = qkv.chunk(3, dim=-1)
print(f"q size: {q.size()}, k size: {k.size()}, v size: {v.size()}, ")
values, attention = scaled_dot_product(q, k, v, mask)
print(f"values.size(): {values.size()}, attention.size:{ attention.size()} ")
values = values.reshape(batch_size, max_sequence_length, self.num_heads * self.head_dim)
print(f"values.size(): {values.size()}")
out = self.linear_layer(values)
print(f"out.size(): {out.size()}")
return out
class LayerNormalization(nn.Module):
def __init__(self, parameters_shape, eps=1e-5):
super().__init__()
self.parameters_shape=parameters_shape
self.eps=eps
self.gamma = nn.Parameter(torch.ones(parameters_shape))
self.beta = nn.Parameter(torch.zeros(parameters_shape))
def forward(self, inputs):
dims = [-(i + 1) for i in range(len(self.parameters_shape))]
mean = inputs.mean(dim=dims, keepdim=True)
print(f"Mean ({mean.size()})")
var = ((inputs - mean) ** 2).mean(dim=dims, keepdim=True)
std = (var + self.eps).sqrt()
print(f"Standard Deviation ({std.size()})")
y = (inputs - mean) / std
print(f"y: {y.size()}")
out = self.gamma * y + self.beta
print(f"self.gamma: {self.gamma.size()}, self.beta: {self.beta.size()}")
print(f"out: {out.size()}")
return out
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
print(f"x after first linear layer: {x.size()}")
x = self.relu(x)
print(f"x after activation: {x.size()}")
x = self.dropout(x)
print(f"x after dropout: {x.size()}")
x = self.linear2(x)
print(f"x after 2nd linear layer: {x.size()}")
return x
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, num_heads, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
self.norm1 = LayerNormalization(parameters_shape=[d_model])
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNormalization(parameters_shape=[d_model])
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x):
residual_x = x # 잔차 연결을 위한 텐서 값 보관
print("ATTENTION 1")
x = self.attention(x, mask=None) # 멀티헤드 어텐션 계산
print("DROPOUT 1")
x = self.dropout1(x) # 드롭아웃
print("ADD AND LAYER NORMALIZATION 1")
x = self.norm1(x + residual_x) # 잔차 연결 및 레이어 가중치 정규화
residual_x = x
print("ATTENTION 2")
x = self.ffn(x)
print("DROPOUT 2")
x = self.dropout2(x)
print("ADD AND LAYER NORMALIZATION 2")
x = self.norm2(x + residual_x)
return x
class Encoder(nn.Module):
def __init__(self, d_model, ffn_hidden, num_heads, drop_prob, num_layers):
super().__init__()
self.layers = nn.Sequential(*[EncoderLayer(d_model, ffn_hidden, num_heads, drop_prob) for _ in range(num_layers)])
def forward(self, x):
x = self.layers(x)
return x
d_model = 512
num_heads = 8
drop_prob = 0.1
batch_size = 30
max_sequence_length = 200
ffn_hidden = 2048
num_layers = 5
encoder = Encoder(d_model, ffn_hidden, num_heads, drop_prob, num_layers)
x = torch.randn((batch_size, max_sequence_length, d_model))
out = encoder(x)
print(out)
트랜스포머 인코더 실행 결과는 다음과 같다.


트랜스포머 인코더 실행 결과 일부
트랜스포머 GPU 메모리 사용량
트랜스포머는 기존 딥러닝 방식보다 많은 GPU 메모리를 사용한다. 필요 메모리량은 다음과 같다.
L = 12 # 블록 수
N = 12 # 헤드 수
E = 768 # 임베딩 차원
B = 8 # 배치 크기
T = 1024 # 시퀀스 길이
TOKS = 50257 # 단어사전 내 토큰 수
param_bytes = 4 # float32 uses 4 bytes
bytes_to_gigs = 1000000000 # 1 billion bytes in a gigabyte
model_params = (TOKS*E)+ L*( 4*E**2 + 2*E*4*E + 4*E)
act_params = B*T*(2*TOKS+L*(14*E + N*T ))
backprop_model_params = 3*model_params
backprop_act_params = act_params
total_params = model_params+act_params+backprop_model_params+backprop_act_params=4*model_params+2*act_params
gigabytes_used = total_params*param_bytes/bytes_to_gigs
print(gigabyes_used)
허깅페이스 GPT2 모델의 경우, 27.5Gb정도가 학습에 필요한 GPU 메모리량이다.
결론
딥러닝 모델 트랜스포머 핵심 코드 개발하는 과정을 살펴봄으로써, 트랜스포머의 기본 동작 메커니즘을 확인해 보았다.
트랜스포머는 입력 데이터 토큰들과 출력 데이터 토큰들 간의 순서쌍을 통해, 유사성을 계산한다. 특정 토큰 다음에 어떤 토큰이 생성될 지를 확률적으로 계산하는 어텐션 개념을 사용한다. 멀티헤드 어텐션을 통해 다양한 문맥을 고려한 문장 예측이 가능하다.
트랜스포머는 순서가 있는 데이터 토큰의 예측, 생성, 비교 과정을 수학적으로 일반화한 확률 통계 모델이므로, 사실상, 데이터 종류에 구애받지 않는다. 그러므로, 멀티모델 생성AI의 핵심 기술로 사용될 수 있다.
다음 시간에는 트랜스포머의 디코더 코드 분석을 통해, 디코딩 동작 부분을 확인해 보도록 한다.
레퍼런스
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발
- 딥러닝 기반 3차원 스캔 데이터, 포인트 클라우드 학습
- Attention in transformers, step-by-step | DL6
- 생성(Generative) AI 오픈소스 딥러닝 모델 Stable Diffusion, ControlNet 개념 및 ComfyUI 사용법
- Computer_vision_deeplearning: computer vision based on deep learning lecture materials, Github
- Attention Is All You Need, Google
- Transformers and Multi-Head Attention — UvA DL Notebooks v1.2 documentation (uvadlc-notebooks.readthedocs.io)
- Self Attention in Transformer Neural Networks
- Building a ML Transformer in a Spreadsheet - DEV Community
- Transformers from Scratch (e2eml.school)
- How Transformers work in deep learning and NLP: an intuitive introduction | AI Summer (theaisummer.com)
- Building a ML Transformer in a Spreadsheet
- ML Transformer in a Spreadsheet Template - Google Sheets
- ML Transformer in a Spreadsheet - Google Sheets
- Attention is All you need (참고1, 참고2)
- Stanford CS25: V2 I Introduction to Transformers
- Appendix to Building a ML Transformer in a Spreadsheet
- Transformer machine learning language model for auto-alignment of long-term and short-term plans in construction - ScienceDirect
- Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy
- Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog (#1)
- Glossary of Deep Learning: Word Embedding | by Jaron Collis | Deeper Learning | Medium
- Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick (mccormickml.com)
- Generative AI Models in Image Generation: Overview - Synthesis AI
- Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
- Attention? Attention! | Lil'Log (lilianweng.github.io)
- Long Short-Term Memory-Networks for Machine Reading, 2016
- Illustrated: Self-Attention. A step-by-step guide to self-attention… | by Raimi Karim | Towards Data Science
- RNN From Scratch | Building RNN Model In Python (analyticsvidhya.com)
- Recurrent Neural Networks From Scratch | by Maciej Balawejder | Nerd For Tech | Medium
- Building A Recurrent Neural Network From Scratch In Python | by Youssef Hosni | Towards AI
- Transformer Memory Requirements – Trenton Bricken – Interested in Machine Learning, Neuroscience, and Original Glazed Krispy Kreme Doughnuts.
댓글 없음:
댓글 쓰기