이 글은 생성AI 기반 텍스트 to 비디오 생성 도구인 ControlNet에 대해 정리한다.


소개
생성형 AI 기술은 텍스트, 이미지, 오디오 또는 비디오와 같은 새로운 콘텐츠를 생성할 수 있다. 이러한 AI 모델은 대규모 데이터 세트에서 훈련되며 복잡한 알고리즘을 사용하여 패턴을 학습하고 새로운 콘텐츠를 생성한다. 많은 관심을 끌고 있는 Text2Image 모델 중 하나는 Stable Diffusion이다
Stable Diffusion에는 많은 기능이 있지만 Stable Diffusion의 확장 기능인 Control-Net은 동일한 이미지의 여러 변형을 생성할 수 있다.
Stable Diffusion은 2022년에 출시된 딥러닝, 텍스트-이미지 AI/머신러닝 모델이다. 주로 텍스트 설명에 따라 상세한 이미지를 생성하는 데 사용되지만 인페인팅, 아웃페인팅, 텍스트 프롬프트에 따라 안내되는 이미지-이미지 번역 생성과 같은 다른 작업에도 적용할 수 있다. 스타트업 Stability AI가 여러 학술 연구원 및 비영리 단체와 협력하여 개발했다.
ControlNet
ControlNet은 신경망 구조, 아키텍처 또는 새로운 신경망 구조로, 추가 조건을 추가하여 확산 모델을 제어하는 데 도움이 된다. ControlNet은 기존 확산 모델을 가져와서 아키텍처를 변경하고 아래 그림과 같이 원하는 것을 추가할 수 있다.

Hugging Face 허브에는 이미 50개의 +public 및 open ControlNet 모델이 있으며, 기본 모델은 1200+개 좋아요를 받았다. ControlNet은 이미지에서 대상의 모양/형태를 식별하는 데 도움이 되는 여러 모델이 패키지로 제공된다.
깊이 맵(Depth Map)
Stable diffusion v2의 이미지 깊이와 마찬가지로 ControlNet은 입력 이미지에서 깊이 맵을 추론할 수 있다. ControlNet의 깊이 맵은 Stable Diffusion v2보다 해상도가 높다.

세그멘테이션 맵(Segmentation Map)
입력 영상에서 추출된 분할 맵을 기반으로 영상을 생성한다.

사람 자세 감지
Openpose는 손, 다리, 머리의 위치와 같은 사람의 포즈를 추출할 수 있는 빠른 키포인트 감지 모델이다.
OpenPose를 사용하는 ControlNet 워크플로를 지원한다. 키포인트는 OpenPose를 사용하여 입력 이미지에서 추출되어 키포인트의 위치를 포함하는 컨트롤 맵으로 저장된다. 그런 다음 텍스트 프롬프트와 함께 추가 컨디셔닝으로 Stable Diffusion에 공급 된다. 이미지는 이 두 가지 조건을 기반으로 생성된다.

이미지 재구성
Control-Net with Stable Diffusion을 사용하여 저해상도 또는 저하된 이미지에서 고해상도 이미지를 재구성할 수 있다. 이는 포렌식 또는 의료 영상과 같이 이미지에서 가능한 한 많은 세부 정보를 얻는 것이 중요한 분야에서 유용할 수 있다.

물체 감지 및 인식
Control-Net with Stable Diffusion은 까다로운 조명 또는 기상 조건에서도 이미지에서 물체를 감지하고 인식하는 데 사용할 수 있다. 이는 빠르고 정확한 물체 인식이 중요한 자율 주행 또는 보안과 같은 분야에서 유용할 수 있다.
이미지 복원: Control-Net with Stable Diffusion을 사용하여 오래되거나 손상된 이미지를 복원하여 원래 품질로 되돌릴 수 있다. 이것은 예술 복원이나 역사 보존과 같은 분야에서 유용할 수 있다.
데이터 증강
Control-Net with Stable Diffusion을 사용하여 머신 러닝 모델 훈련을 위한 새롭고 고유한 데이터를 생성할 수 있다. 이는 컴퓨터 비전이나 자연어 처리와 같은 분야에서 유용할 수 있으며, 다양하고 대표적인 데이터 세트를 보유하는 것이 모델 정확도에 중요한다.
3D 재구성: Control-Net with Stable Diffusion을 사용하여 2D 이미지 또는 비디오에서 3D 모델을 재구성할 수 있다. 이는 사실적이고 몰입감 있는 3D 환경을 만드는 것이 중요한 건축이나 가상 현실과 같은 분야에서 유용할 수 있다.

Stable Diffusion을 사용한 ControlNet 실행하기
실행 방법은 다음과 같다.
- 컴퓨터에서 Automatic1111의 스테이블 디퓨전 설치(Mikubill/sd-webui-controlnet: WebUI extension for ControlNet) 및 실행(webui-user.bat 실행)
- 서버가 실행되면, URL http://127.0.0.1:7860에 접속함
- Extensions 탭으로 이동하여 Available 하위 탭을 클릭
- 로드 버튼을 클릭
- controlnet을 입력. sd-webui-controlnet이라는 확장 프로그램이 표시되면 맨 오른쪽의 작업 열에서 설치를 클릭. WebUI는 필요한 파일을 다운로드하고 Stable Diffusion의 로컬 인스턴스에 ControNet을 설치할 것임.
- 설치된 탭으로 이동해 적용버튼 클릭 후, UI를 다시 재시작함
- Huggingface 링크에 있는 모든 모델 다운로드 후, 아래 models 폴더에 파일들 복사해 넣음

실행하면, Stable Diffusion GUI에는 다양한 옵션과 설정이 제공된다. 첫 번째 창에는 이미지 페이지에 대한 텍스트가 표시된다. 프롬프트를 제공하고 생성 버튼을 클릭하고 완료될 때까지 기다린다. 아래 이미지에서 볼 수 있듯이 이미지를 생성하는 데 몇 분 정도 걸린다.
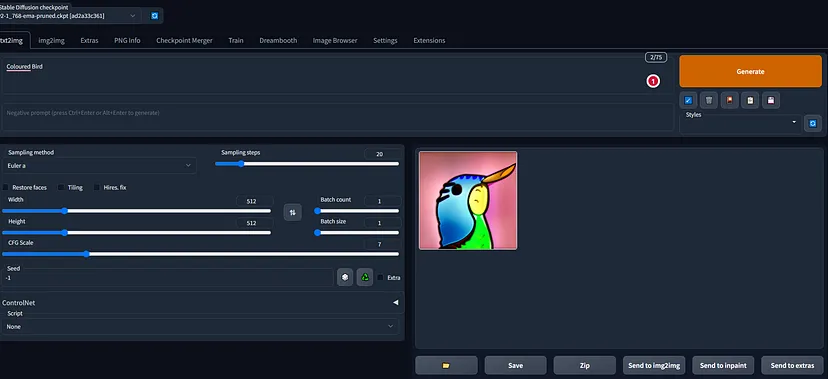
첨부된 스크린샷에서 볼 수 있듯이 생성된 이미지를 저장하고, zip 파일을 만들고, img2img로 보내고, inpaint로 보내는 등의 작업에 사용할 수 있는 다양한 옵션이 있다.
이미지 저장 버튼을 클릭한 후 이미지 다운로드 옵션을 볼 수 있다. 생성된 이미지에서 Inpaint를 수행할 수 있다. 필요에 따라 Annotator 해상도, Canny 낮은 임계값, Canny 높은 임계값, 무게 등과 같은 모든 것을 선택할 수 있다.

결론
이 글은 ControlNet 기능에 대해 설명하였다. 이를 이용해 간단한 이미지나 텍스트만으로도 다양한 이미지와 영상을 생성할 수 있다.
레퍼런스
- Stable Diffusion and Control-Net -A Beginners Guide | Medium
- Installing ControlNet in Automatic1111 | Weird Wonderful AI Art
- ControlNet v1.1: A complete guide - Stable Diffusion Art (stable-diffusion-art.com)
- Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models (controlavideo.github.io)
- Vchitect/LaVie: LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models (github.com)
- LaVie - a Hugging Face Space by Vchitect
- Vchitect/SEINE: SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction (github.com)
- Vchitect/SEINE: SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction (github.com)
- RoomGPT
- Create | Kaedim
- 건축가가 꼭 알아야 할 최신 AI 활용법
댓글 없음:
댓글 쓰기