딥러닝 모델들을 개발하다 보면, 수많은 종류의 데이터셋, 하이퍼모델 파라메터 튜닝 등으로 인해 관리해야 할 자료들이 매우 복잡해진다는 것을 알게 된다. Weights & Biases (W&B) 회사는 이름 그대로 완벽한 모델 학습을 위해 필요한 Weights & Biases를 모니터링, 관리할 수 있는 로그 도구이다. 즉, 딥러닝 모델 개발자를 위한 프로세스 로그 및 가시화 플랫폼을 제공한다.

W&B(AI Summer)
매우 직관적인 이름을 가진 이 스타트업은 Tensorboard와 유사하지만, 적은 코드로 모델 개발에 많은 통찰력을 준다. 이 W&B(WandB) 라이브러리를 사용하면, 딥러닝 모델 학습 시 지저분하게 붙어 나가는 로그 처리를 매우 간단한 함수 몇 개로 처리할 수 있다. 통합된 데시보드 형태로 다양한 모델 학습 품질 지표를 확인 및 비교할 수 있다. 이외, 학습 모델 하이퍼 파라메터 관리와 튜닝 및 비교 보고서 생성 기능을 제공한다. 로그는 숫자, 텍스트, 이미지 등 다양한 포맷을 지원한다.

W&B 딥러닝 모델 개발 프로세스 가시화 데쉬보드
이 글은 딥러닝 모델 학습 로그, 가시화만 집중해 살펴본다. 글 마무리에 W&B의 개발 배경도 간단히 알아본다.
사용법
다음 링크 방문해 회원 가입한다.
- wandb.ai website
회원 가입하고, 다음 그림과 같이 홈 메뉴에서 키 토큰 값을 얻어 복사한다. 이 키는 wandb API를 사용할 때 필요하다.


터미널에서 다음을 실행해 설치한다.
pip install wandb
예시 및 결과
다음과 같이 cosine 데이터를 학습하는 간단한 코드를 만들어 본다. W&B로 로그를 기록하도록 몇몇 함수를 호출할 것이다. 앞에서 얻은 키 토큰은 다음 코드에 해당 부분에 입력해 준다.
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torchviz import make_dot
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(1, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Generate cosine dataset
def generate_cosine_data(num_samples=100):
x = torch.linspace(-2 * torch.pi, 2 * torch.pi, num_samples).view(-1, 1)
y = torch.cos(x)
return x, y
# Instantiate the model, loss function, and optimizer
model = SimpleMLP()
model.to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
wandb.login(key='') # 여기에 키값 입력
api = wandb.Api()
wandb.init(project="train_cosin",
config={
"optimizer": "SGD",
"learning_rate": 0.01,
"architecture": "SimpleMLP",
"dataset": "cosine"
})
wandb.watch(model, criterion, log="all") # 모든 지표 기록
# 학습 데이터 생성
x, y = generate_cosine_data()
x, y = x.to(device), y.to(device)
# 학습
prediction = None
num_epochs = 10000
image_files = []
for epoch in tqdm(range(num_epochs)):
# Forward pass
outputs = model(x)
prediction = outputs
loss = criterion(outputs, y)
print(f"Epoch: {epoch}, Loss: {loss.item()}")
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Visualize the gradients of the first epoch using wandb
layer_name = ''
grad_cpu = data_cpu = None
for name, param in model.named_parameters():
if param.requires_grad and param.grad is not None:
layer_name = name
grad_cpu = param.grad.detach().cpu()
data_cpu = param.data.detach().cpu()
break
log_data = {"epoch": epoch, "loss": loss.item(), "outputs": outputs.detach().cpu().numpy(),
f'{layer_name}_gradients': wandb.Histogram(grad_cpu),
f'{layer_name}_weights': wandb.Histogram(data_cpu)}
wandb.log(log_data) # 에폭, 로스, 출력, 기울기, 가중치 로그 기록
학습된 결과는 다음과 같다. 잘 학습된 것을 알 수 있다.
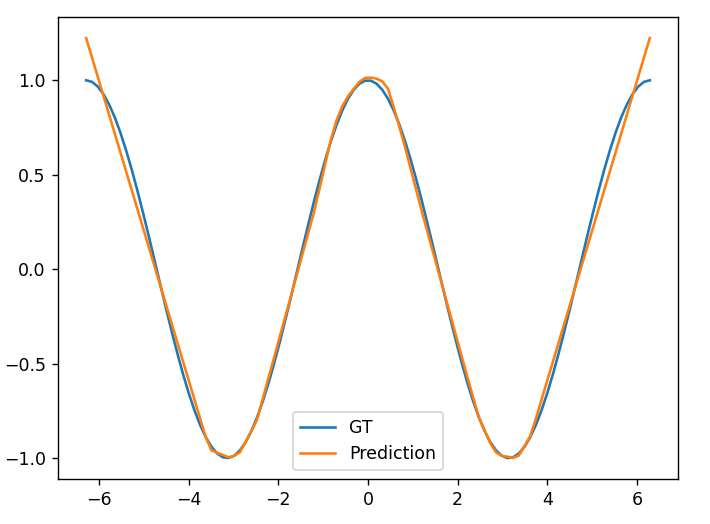

데쉬보드에서는 각 단계 별 기울기, 가중치, 로스 등이 어떻게 변화하는 지를 손쉽게 확인할 수 있다.
각 차트 데이터는 엑셀 등 포맷으로 저장 가능하다.
로짓 출력값을 확인해 보자. 초기 에폭에서는 학습되지 않은 임의 값을 출력하지만, 학습될 수록 y에 근사한 패턴으로 출력되는 것을 확인할 수 있다.


다음 경우는 모델의 바이어스 히스토그램 차트 데이터를 보여준다.

엑셀로 다운로드하면, 모델 학습 데이터의 특정 범위에 속한 값의 누적 데이터를 쉽게 확인할 수 있다.

다음과 같이 리포트 기능을 사용해, 모델 학습 품질을 검토할 수 있다.

마무리
W&B는 루카스 비왈드(Lukas Biewald)가 2017년 설립한 딥러닝 모델 학습 서비스를 제공하는 스타트업이다. 이 회사는 딥러닝 개발자에 필요한 실무적인 도구를 개발한다. 그는 딥러닝 연구 초창기부터 머신러닝 연구자 및 개발자로 있으면서, 실무자의 어려움을 알고 있었다.

Lukas Biewald (2018)
OpenAI는 W&B의 첫번째 고객이다. 이 도구는 머신러닝 개발자의 많은 수작업 프로세스를 자동화하여, 모델 학습 과정을 모니터링, 추적하고, 직관적인 학습 모델 디버깅, 검사 및 설명이 가능하도록 하여, 체계적으로 이 과정을 관리한다. 이 회사는 현재 700,000명 이상의 유료 사용자를 보유하고 있으며, 대부분, OpenAI와 같이 빅테크 기업들 개발자이 사용자이다.

W&B 창업자 루카드 비왈드 및 핵심 파트너(San Francisco responsible AI startup Weights & Biases raises $50M - San Francisco Business Times. Weights & Biases raises $5M to build development tools for machine learning)
이 회사는 현재까지 $250M 펀딩 투자받았다. 이 금액은 원화로 3,500억(환율 1400원 기준)에 해당한다. 현재 W&B는 핵심기술을 개발하며, 기업공개를 준비하고 있다.

부록: 딥러닝 모델의 해 탐색 과정 탐색 과정 가시화 원리
여기서 딥러닝 모델의 해 탐색 과정을 가시화하는 원리를 간략히 살펴보자. 딥러닝 모델은 빅 데이터를 통계적 학습하여, y에 가장 가까운 ŷ = w·x + b 를 탐색하는 과정이다. 그러므로, 가장 loss = y - ŷ가 작은 weight w, bais b를 찾는 것이 목적이다. 그러므로, 제대로 해를 탐색하는 지 확인하려면, epoch당 loss와 w:b 차트를 확인하는 것이 중요하다.
모델을 구성하는 레이어 유닛이 여러개라면, w:b도 여기에 비례해 많으므로, 원리만 살펴보기 위해, 매우 간단한 ŷ = w·x + b 수식을 학습하는 단순한 딥러닝 모델을 학습한다고 가정한다.
# 데이터 생성
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(20240215)
n = 50
x = np.array(np.random.randn(n), dtype=np.float32)
y = np.array(
0.75 * x**2 + 1.0 * x + 2.0 + 0.3 * np.random.randn(n),
dtype=np.float32) # 데이터 임의로 생성할 수식
plt.scatter(x, y, facecolors='none', edgecolors='b')
plt.scatter(x, y, c='r')
plt.show()
# 데이터 학습 모델 준비
import torch
model = torch.nn.Linear(1, 1)
model.weight.data.fill_(6.0)
model.bias.data.fill_(-3.0)
# 손실 함수 준비
loss_fn = torch.nn.MSELoss()
learning_rate = 0.1
epochs = 100
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 학습
models = [[model.weight.item(), model.bias.item()]]
for epoch in range(epochs):
inputs = torch.from_numpy(x).requires_grad_().reshape(-1, 1)
labels = torch.from_numpy(y).reshape(-1, 1)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
models.append([model.weight.item(), model.bias.item()])
# 모델 예측 값 비교 출력
weight = model.weight.item()
bias = model.bias.item()
plt.scatter(x, y, facecolors='none', edgecolors='b')
plt.plot(
[x.min(), x.max()],
[weight * x.min() + bias, weight * x.max() + bias],
c='r')
plt.show()
# loss map 작성
def get_loss_map(loss_fn, x, y):
"""Maps the loss function on a 100-by-100 grid between (-5, -5) and (8, 8)."""
losses = [[0.0] * 101 for _ in range(101)]
x = torch.from_numpy(x)
y = torch.from_numpy(y)
for wi in range(101):
for wb in range(101):
w = -5.0 + 13.0 * wi / 100.0
b = -5.0 + 13.0 * wb / 100.0
ywb = x * w + b
losses[wi][wb] = loss_fn(ywb, y).item()
return list(reversed(losses)) # Because y will be reversed.
# w:b 2차원 loss map 상 해 탐색 path 가시화
import pylab
loss_fn = torch.nn.MSELoss()
losses = get_loss_map(loss_fn, x, y)
cm = pylab.get_cmap('terrain')
fig, ax = plt.subplots()
plt.xlabel('Bias')
plt.ylabel('Weight')
i = ax.imshow(losses, cmap=cm, interpolation='nearest', extent=[-5, 8, -5, 8])
model_weights, model_biases = zip(*models)
ax.scatter(model_biases, model_weights, c='r', marker='+')
ax.plot(model_biases, model_weights, c='r')
fig.colorbar(i)
plt.show()
결과는 다음과 같다.

loss함수를 바꿔가며, 해가 어떻게 탐색되는 지 확인해 보면, 다음과 같다. 데이터 특성에 따라 적절한 전략을 써야 한다는 것을 알 수 있다.

레퍼런스
댓글 없음:
댓글 쓰기