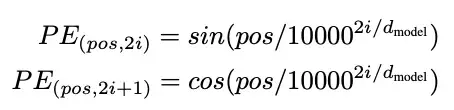가상환경(virtualenv)을 사용한다는 가정하에, 기존 가상환경은 삭제하고, 다음과 같이 의존성이 맞는 버전을 다시 설치한다. pip install tensorflow=2.4.0 pip install tensorflow-gpu=2.4.0 pip install keras==2.4.0 pip install jupyter
가상환경을 다음과 같이 활성화한다.
source <path>/activate
이제 쥬피터 노트북에서 실행하면 다음 같은 딥러닝 코드가 잘 실행되는 것을 확인할 수 있다.
# LSTM for international airline passengers problem with regression framing
이 글은 3차원 특수효과 영화 제작시 사용되는 Blender와 Fusion Studio 에 대한 간략한 소개이다. 영화나 영상 특수효과에서 기존에는 Adobe나 Autodesk 제품군을 많이 사용했었다. 하지만, 가성비 좋은 블랜더와 퓨전 스튜디오가 블록버스터 영화, 광고, 티비에 크게 사용이 되면서, 이 도구에 대한 관심이 높아졌다.
블랜더는 오픈소스 기반 3차원 모델링, 애니메이션 및 특수효과 처리 소프트웨어이며, 퓨전은 특수효과, 후처리, 렌더링 전용 소프트웨어이다.
이 도구들을 활용하면, 촬영한 영상에 블랜더에서 3D로 모델링된 UFO를 합성하고, 퓨전에서 섬광이나 화염과 같은 후처리 특수효과를 합성할 수 있다.
이 글은 어텐션(Attention) 기반 트랜스포머(Transformer) 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법을 소개을 공유한다. 트랜스포머는 BERT(Bidirectional Encoder Representations from Transformers), GPT-3 등의 기반이 되는 기술이다.
트랜스포머를 이용하면, 기존 RNN, LSTM, CNN, GCN가 지역적 특징을 바탕으로 데이터를 학습 및 예측하는 한계를 해결할 수 있다. 트랜스포머는 셀프 어텐션을 포함하여, 전체 데이터셋을 순서에 관계없이 학습 과정에 포함시켜, 가중치를 계산하므로, 좀 더 높은 정확도의 학습 모델을 개발할 수 있다.
트랜스포머 모델 개념
논문 'Attention Is All You Need'는 트랜스포머 개념과 시퀀스-투-시퀀스 아키텍처에 대해 설명한다. Sequence-to-Sequence(Seq2Seq)는 문장의 단어 시퀀스와 같은 주어진 시퀀스를 다른 시퀀스로 변환하는 신경망이다.
Seq2Seq 모델은 한 언어의 단어 시퀀스가 다른 언어의 다른 단어 시퀀스로 변환되는 번역에 특히 좋다. 이 유형의 모델에 널리 사용되는 LSTM(장단기 메모리)은 시퀀스에 의미를 부여할 수 있다. 예를 들어 문장은 단어의 순서가 문장을 이해하는 데 중요하기 때문에 순서에 따른 의미를 훈련시킬 수 있다.
LSTM 이상패턴 사용 예시
Seq2Seq 모델은 인코더와 디코더로 구성된다. 인코더는 입력 시퀀스를 가져와 더 높은 차원 공간(n차원 벡터)에 매핑한다. 출력 시퀀스는 다른 언어, 기호, 입력 사본 등일 수 있다.
'Attention Is All You Need'라는 논문은 Transformer라는 아키텍처를 소개한다. LSTM과 마찬가지로 Transformer는 두 부분(Encoder 및 Decoder)으로 한 시퀀스를 다른 시퀀스로 변환하는 아키텍처이지만, RNN(Recurrent Neural Networks) 없이 어텐션(Attention. 주의) 메커니즘만 있는 아키텍처로 성능을 개선할 수 있음을 증명했다. 어텐션은 앞에서 입력된 글이 그 다음의 단어를 결정할 때, 어떤 단어가 출력되어야 하는 지를 수학적으로 계산할 수 있다.
어텐션 매커니즘
트랜스포머 모델의 인코더는 왼쪽에 있고 디코더는 오른쪽에 있다. Encoder와 Decoder는 모두 여러 번 서로 겹쳐질 수 있는 모듈로 구성된다. 입력 데이터는 토큰(예. 자연어 텍스트)으로 분리된 후, 행렬 텐서 계산을 위해, 토큰을 숫자로 변환한 임베딩 텐서를 계산한다.
텍스트-임베딩 텐서 변환 예시(Word2Vec)
텍스트의 경우, 토큰은 각자 순서가 있으므로, 위치 정보를 학습에 포함하기 위해, 포지션 인코딩한 결과를 임베딩 텐서에 더한다. 이제, 그 결과를 Multi-Head Attention 및 Feed Forward를 수행해 어텐션을 계산하고, ResNet과 같이 신경망 앞 부분의 가중치가 소실되지 않도록 더해주고 정규화(Add & Norma)시킨다.
한편, 라벨링된 출력은 자연어에서 보았을 때는 텍스트가 한 토큰(단어)씩 우측 쉬프트된 것과 같다. 이를 함께 학습과정에서 고려해 주어야, 손실을 계산하고, 전체 신경망의 weight 행렬을 업데이트할 수 있다. 손실을 계산해 주는 부분은 Multi-Head Attention을 통해 계산하고, 그 결과 텐서를 linear한후 softmax로 처리해, 다음에 올 토큰의 확률을 얻는다.
트랜스포머 아키텍처
이런 이유로, 트랜스포머의 구성은 주로 Multi-Head Attention 및 Feed Forward 레이어로 되어 있다. 언급한 바와 같이, 문자열을 직접 사용할 수 없기 때문에 입력과 출력(목표 문장)은 먼저 임베딩 기법으로 수치화된 후 n차원 공간에 매핑된다.
이 결과, 모델의 전체 실행 순서 예는 다음과 같다.
전체 인코더 시퀀스(예. 프랑스어 문장)를 입력하고 디코더 입력으로, 첫 번째 위치에 문장 시작 토큰만 있는 빈 시퀀스를 사용한다.
해당 요소는 디코더 입력 시퀀스의 두 번째 위치에 채워지며, 문장 시작 토큰과 첫 번째 단어/문자가 들어 있다.
인코더 시퀀스와 새 디코더 시퀀스를 모두 모델에 입력한다. 출력의 두 번째 요소를 가져와 디코더 입력 시퀀스에 넣는다.
번역의 끝을 표시하는 문장 끝 토큰을 예측할 때까지 이 작업을 반복한다.
다음은 이 과정을 계산한다.
어텐션(주의 집중) 내부 메커니즘
트랜스포머에 사용된 Mult-Head Attention은 손실 함수에 영향을 주는 값을 계산하는 역할을 한다. 토큰을 인코더에 입력해서 계산된 특징벡터 텐서와 예측되어야 할 토큰의 특징벡터를 내적해 계산한다. 그 결과, 가중치가 고려된 텐서 행렬이 된다.
입력 토큰에 대한 어텐션 토큰 예시
이를 좀 더 자세히 살펴보면, 다중 헤더 어텐션은 학습되어야할 모델 텍스트 데이터의 어느 부분에 초점을 맞춰야 하는지를 학습한다. Mult-Head Attention은 앞서 차례대로 입력된 임베딩+포지션 벡터를 n차원 Query, n차원 Key, Value 벡터로 분리해, 학습을 시켜 어텐션 텐서 행렬을 구한다. 만약, 'the quick brown fox jumped' 문장이 있고, 이를 프랑스어 le renard brun rapide a sauté로 변환한다면, 키 행렬에서 개별 단어 토큰에 대한 가중치를 학습하고, 쿼리 행렬은 실제 입력 단어로 표현할 수 있다. 쿼리와 키 행렬의 내적을 구하면, 다음처럼 self-attention (자체 주의. 두 행렬의 유사도 값이 계산됨) 텐서를 얻을 수 있다.
셀프 어텐션의 계산 결과는 질의와 키 메트릭스 간 유사도 점수 매트릭스가 됨
이 텐서값은 차원수의 제곱근으로 나누어 정규화된다. 그 결과를 소프트맥스 함수에 입력해, 질의된 예측 토큰의 확률값을 얻을 수 있다. 그러므로, 어텐션 블럭의 함수식은 다음과 같이 표현할 수 있다.
여기서, n은 Q, K의 차원수, V텐서는 훈련된 매개변수(가중치)가 된다. 어텐션 전체 알고리즘은 다음과 같다.
Multi-head attention(2021, Hadamard Attentions: The Mighty Attentions Optimized)
여기에 사용된 dot product는 기하학적으로 그 값이 작을수록, 특징벡터가 유사도를 나타내는 similarity function로 동작하기 때문에(두 벡터의 각도 차이가 작을 수록, dot product 값이 작은 cosine 함수), 그 자체가 손실함수값에 영향을 준다.
동작 과정 설명
포지션 인코딩 동작 방식
포지션 인코딩은 입력 데이터의 순서를 기억할 수 있는 순환 네트워크가 없기 때문에, 시퀀스의 모든 단어/부분에 상대적인 위치를 계산하는 방식이다. 이러한 위치는 각 단어의 포함된 표현(n차원 벡터)에 추가된다. 보통, 이 방식은 다음의 sin, cos함수를 통해 토큰이 텍스트에서 사용된 i번째 위치 벡터를 계산한다.
포지션 인코딩 함수
사용 예시
사용 예시를 간단히 확인해 본다. 이를 위해 아래 링크를 참고하도록 한다.
Text Transformer: BERT, GPT-3같은 문서 종류 분류, 번역, 작문, 챗봇, 주가예측, 작사 등
이 예제의 목표는 다음과 같은 입력에 대한 출력을 예측하는 것이다. 참고로, 데이터의 종류는 텍스트이지만, 수치화할 수 있다면, 이미지, 소리 등 종류에 구애받지 않는다.
이 예제는 학습 데이터를 Wikitext-2(https://github.com/pytorch/data)를 사용한다. 미리 다운로드 받아 둔다. 어휘의 토큰은 센서로 수치화되어 학습될 것이다. 이 텍스트 시퀀스는 batchify()란 함수에 의해, batch_size 수의 컬럼으로 변환된다. 예를 들어, 26개 알파벳 시퀀스를 batch_size=4로 정의할 때 다음과 같은 6개의 4개의 시퀀스로 변환된다.
파이토치 구현 코드는 다음과 같다.
import math
from typing import Tuple
import torch
from torch import nn, Tensor
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer # 트랜스포머 모듈
사용은 매우 쉬운 편인데, 기존 텐서플로우 딥러닝 모델을 작업한 후, 라이트버전으로 변환하면 된다. 변환함수를 당연히 제공하고, 변환시 모델의 실수 데이터 형식은 정수로 자동 변환된다. 참고로, 정수는 실수보다 크기가 4배 적고, 처리 속도는 훨씬 빠르다. 이런 이유로, GPU가 없는 컴퓨터에서도 딥러닝 모델을 빠르게 실행시킬 수 있다. 물론, 이 변환 후에는 실수형 연산 함수는 사용할 수 없다(API 호환성). 몇몇 플랫폼은 연산가속칩이 있다. 라이트는 이 기능을 이용할 수 있다.
변환된 모델은 FlatBuffers형식인 .tflite 확장자인 파일로 저장된다. 이 파일은 메타데이터를 포함할 수 있고, 이 경우, 텐서플로우 라이트 API를 사용하지 않고, 파일 로딩 후 바로 실행할 수 있다.
이제, 각 실행환경에서 사용방법을 확인해 본다.
CoLab기반 딥러닝 모델 생성 및 최적화
CoLab은 구글에서 지원하는 머신러닝 협업 및 연구용 플랫폼으로 대부분 기능이 무료이다.
이 글은 CNN(Convolution Neural Network) 딥러닝 파라메터에 따른 예측 정확도 변화 확인 결과를 간략히 정리한다. 딥러닝 모델은 파라메터가 어떻게 되느냐에 따라 정확도가 달라진다. 얼마나 차이가 나는지를 확인해 보기 위해, CNN 모델을 정의하고, 파라메터를 조정해 본다.
기본 모델 정의
기본 모델은 다음과 같다. 이 모델은 주어진 이미지를 2개의 클래스로 구분한다.
# Our input feature map is 150x150x3: 150x150 for the image pixels, and 3 for
# the three color channels: R, G, and B
img_input = layers.Input(shape=(150, 150, 3))
x = layers.Conv2D(16, 3, activation='relu')(img_input)
CNN 커널 크기와 계층수를 변화시켜보도록 한다. 모델 파라메터를 조정한 결과는 다음과 같다.
커널 3계층 표준
커널 크기 증가1
커널 크기 증가2
커널 2계층
커널 4계층
결론
결과는 CNN 필터를 배수로 증가시켜가면서 모델을 추가했을 때 정확도가 높았다. 또한, 커널 계층을 삭제하거나 증가할때 정확도나 손실은 좋아지지 않았다. 이런 파라메터는 입력 데이터 특성 등에 따라 조정해 나가야 한다. 참고로, 이런 노가다는 AutoML같은 최적 모델 선택 도구를 통해 줄일 수 있다.