이 내용은 시멘틱, 온톨로지, SPARQL, BIM(Building Information Modeling), 트리플(triple), 도커(docker) 등의 개념은 알고 있다는 가정하에 진행한다. 이와 관련된 사항은 아래 링크를 참고한다.
이 글에서는 온톨로지 모델로 트리플 구조를 사용한다. 트리플 설명, Turtle 파일 포맷, 예제는 다음 링크를 참고한다.
Jena Fuseki 서버 동작
이 글은 Jena Fuseki 서버를 사용한다. 이미 만들어진 도커 이미지를 이용해 서버를 구동시킨다. 도커 이미지는 stain/jena-fuseki 를 사용한다. Jena Fuseki 서버에 관한 상세 내용은 다음 링크를 참고하라.
이 글은 Jena Fuseki 서버를 사용한다. 이미 만들어진 도커 이미지를 이용해 서버를 구동시킨다. 도커 이미지는 stain/jena-fuseki 를 사용한다. Jena Fuseki 서버에 관한 상세 내용은 다음 링크를 참고하라.
도커 명령 인터페이스(DCI. Docker Command Interface)에서 stain/jena-fuseki 도커를 다운로드 받는다. 도커 이미지를 run하기 전에, 도커 내 Jena Fuseki 작업 데이터를 보관(persist) 및 저장(save)하려면 다음 같이 도커 volume를 먼저 만들어야 한다. 이 경우 사용하기 편리한 busybox를 사용한다. volume 이름은 fuseki-data 이다.
docker run --name fuseki-data -v /fuseki busybox
이제 다음과 같이 생성된 도커 volume fuseki-data가 지정된 Jena Fuseki 이미지를 실행한다.
docker run -d --name fuseki -p 3030:3030 -e ADMIN_PASSWORD=pw123 --volumes-from fuseki-data stain/jena-fuseki

도커 이미지를 구동한 후 localhost:3030을 접속하면 다음과 같은 Apache Jena Fuseki 서버 데쉬보드 화면을 볼 수 있다. 참고로 아이디아와 암호는 admin, pw123이다.

BIM 온토롤지 파일 업로드
docker run --name fuseki-data -v /fuseki busybox
이제 다음과 같이 생성된 도커 volume fuseki-data가 지정된 Jena Fuseki 이미지를 실행한다.
docker run -d --name fuseki -p 3030:3030 -e ADMIN_PASSWORD=pw123 --volumes-from fuseki-data stain/jena-fuseki

BIM 온토롤지 파일 업로드
Apache Jena Fuseki 메뉴를 이용해 Spider란 이름의 Dataset을 만들고, 다음과 같이 spider.ttl 파일을 저장 후 Jena 에 upload한다.
@base <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rel: <http://www.perceive.net/schemas/relationship/> .
<#green-goblin>
rel:enemyOf <#spiderman> ;
a foaf:Person ; # in the context of the Marvel universe
foaf:name "Green Goblin" .
<#spiderman>
rel:enemyOf <#green-goblin> ;
a foaf:Person ;
foaf:name "Spiderman", "Человек-паук"@ru .


@base <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rel: <http://www.perceive.net/schemas/relationship/> .
<#green-goblin>
rel:enemyOf <#spiderman> ;
a foaf:Person ; # in the context of the Marvel universe
foaf:name "Green Goblin" .
<#spiderman>
rel:enemyOf <#green-goblin> ;
a foaf:Person ;
foaf:name "Spiderman", "Человек-паук"@ru .

dataset 생성 후 파일 업로드
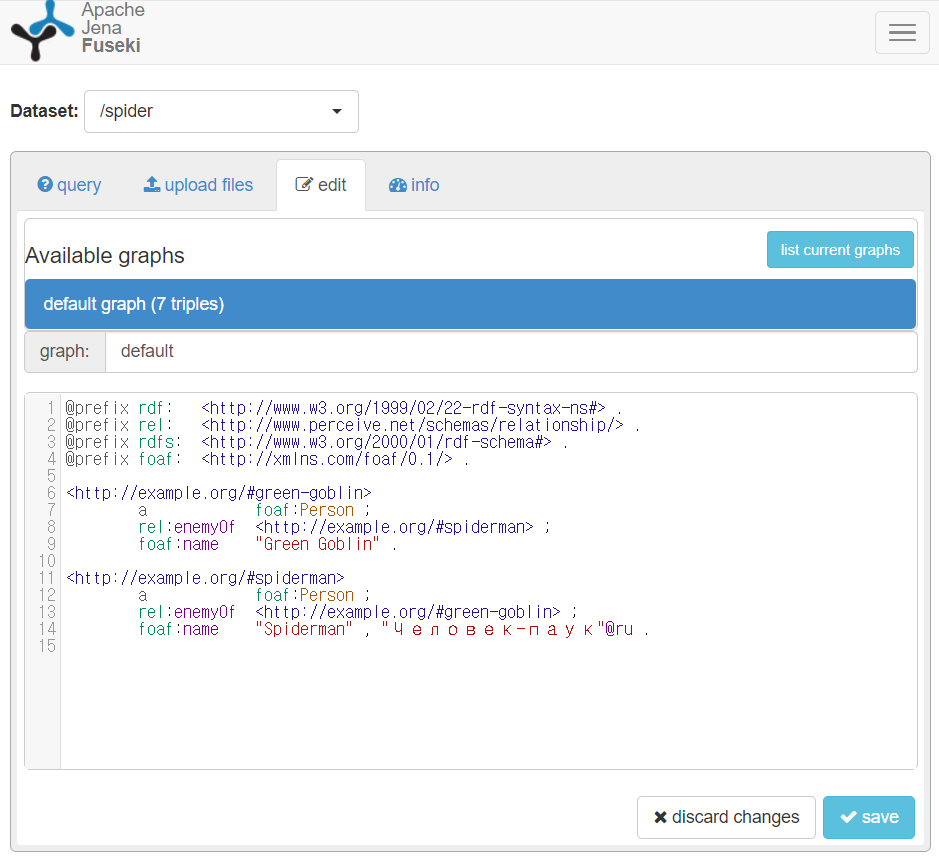
등록된 그래프 데이터 리스트 결과
질의를 다음과 같이 해보자.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rel: <http://www.perceive.net/schemas/relationship/>
SELECT ?subject
WHERE
{ ?subject foaf:name 'Green Goblin' }
그럼 다음과 같이 이름이 Green Goblin 인 subject가 검색된다 .


PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rel: <http://www.perceive.net/schemas/relationship/>
SELECT ?subject
WHERE
{ ?subject foaf:name 'Green Goblin' }
그럼 다음과 같이 이름이 Green Goblin 인 subject가 검색된다 .


그래프 데이터 모델 검색 결과
SPARQL 질의
Dataset을 만들고, ifc2x3 ttl 파일을 다운로드하여 다음과 같이 Jena 에 upload한다.



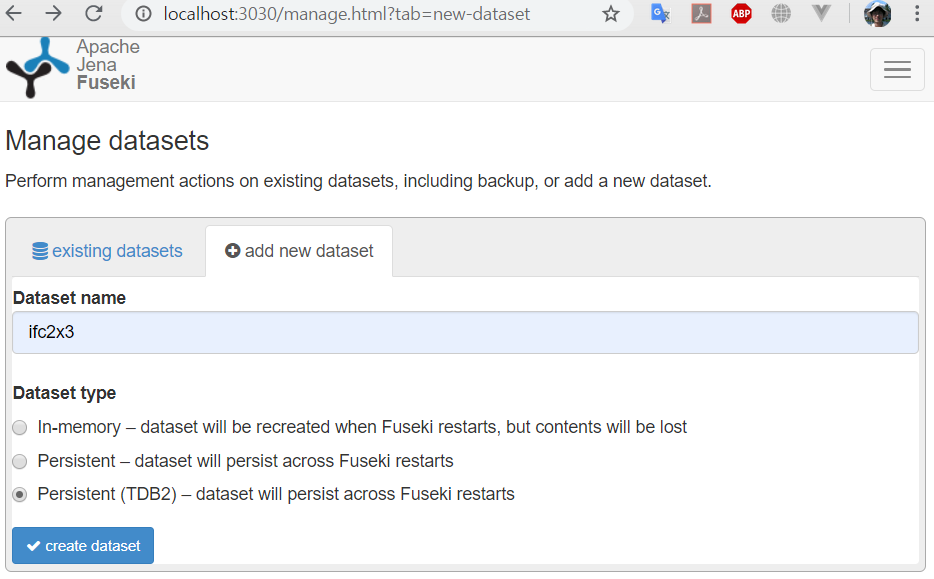
dataset 생성

ttl upload files

업로드된 ifc2x3 ttl 일부 내용
query를 다음과 같이 실행한다. 질의 방법은 PREFIX로 용어를 정의한 네임 스페이스를 설정한 후, SPARQL 구문으로 IfcBuildingElement의 하위 클래스를 질의한다.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dce: <http://purl.org/dc/elements/1.1/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX vann: <http://purl.org/vocab/vann/>
PREFIX list: <https://w3id.org/list#>
PREFIX expr: <https://w3id.org/express#>
PREFIX ifc: <http://ifcowl.openbimstandards.org/IFC2X3_Final#>
PREFIX cc: <http://creativecommons.org/ns#>
SELECT ?subject
WHERE
{ ?subject rdfs:subClassOf ifc:IfcBuildingElement }
결과는 다음과 같다.

질의 모습

질의 결과
fuseki 도커 서버의 로그를 확인하려면 다음 명령을 입력한다.

서버 종료를 위해 다음과 같이 도커 stop명령을 입력한다.
docker stop fuseki
도커 fuseki 서버를 재시작하려면 다음 명령을 입력한다. 참고로 fuseki 서버 run 시 옵션이 저장되므로, 모두 입력할 필요는 없다.
docker restart fuseki
다음처럼, 앞서 생성한 dataset 등이 모두 잘 보관되어 실행되는 것을 확인할 수 있다.
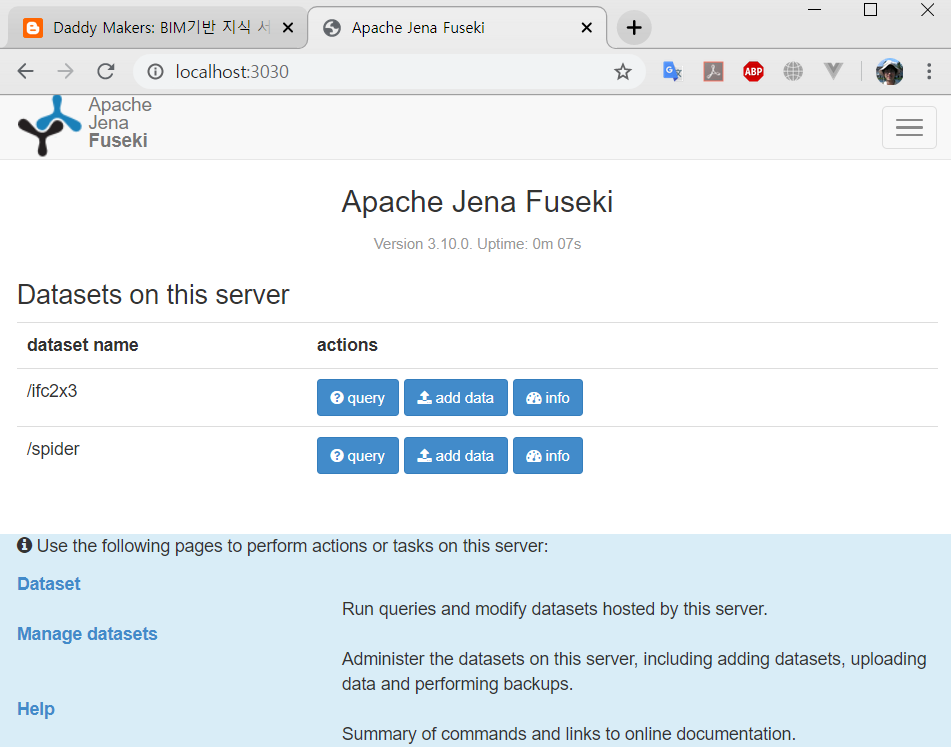

데이터 복원된 도커 Jena Fuseki 서버 실행 모습
마무리
SPARQL을 이용하면 좀 더 복잡하고, 추론적인 질의가 가능하다. 이를 이용해 BIM기반의 다양한 지식 서비스를 좀 더 손쉽게 구현할 수 있다. 다만, BIM과 연계된 지식 서비스 구축을 위해서는 대상 소스의 데이터를 <주어-술어-목적어> 트리플 형식으로 구조화해 데이터베이스를 구축해야 한다. 만약, 텍스트 파일에서 트리플 데이터를 생성하기 위해서는 텍스트 마이닝 기법을 사용해야 한다. 이와 관련된 상세 내용은 레퍼런스를 참고하길 바란다.
레퍼런스
댓글 없음:
댓글 쓰기