라마와 같은 파운데이션 모델의 학습 방식은 전문 유형에 따라 학습할 데이터를 수집하고, 이를 모델에 훈련시키는 방식이다. 이 방식은 일반적인 지식을 학습하기에는 좋으나 특정, 전문적인 질문 시 모호한 답을 생성할 수 있다. 이것은 너무 많은 것을 아는 범재가 전문성을 갖춘 오타쿠의 애니메이션 지식에 못미치는 것과 같은 이유. 이런 이유로 멀티 에이전트 LLM 아키텍처가 연구되었다.

LLM 에이전트 모델 구조
멀티 에이전트 필요성
우리가 다음가 같은 문제가 있다고 가정하자.
Q. apple remote 기술이 무엇인지 알려주고, 그 기술을 구현하는 예제 코드를 보여줘.
이 경우, 범용 LLM의 경우, 관련 데이터 학습이 안되어 있을 경우, 매우 일반적인 파이썬 코드를 제공할 것이다. 하지만, 이런 전문 분야 별 훈련된 LLM 모델 A, 혹은, API를 이용해 관련 정보를 검색해 얻는 코드를 훈련한 LLM 모델 B의 경우, 이 코드를 수행해 얻은 데이터를 텍스트로 요약해주는 LLM 모델 C과 협력해 적절한 해답을 생성할 수 있다. 이런 환경 변화에 따른 반응을 LLM으로 부터 끌어내는 방식을 ReAct라 한다. 다음 그림은 이를 보여준다.


메모리와 CoT
과거의 메모리(기억)도 시행착오하면서 얻은 지식을 발전시키는 데 도움이 된다. 이는 RAG와 유사한 방식으로 LLM에 전달된다.
메모리는 CoT(Chain of Thought) 형식으로 정의된다. 이는 질문-답변-질문-답변 형식으로 된 링크드 리스트 형식이므로, LLM이 잘못된 답을 사용자가 정정해 나가면서, 올바른 답변을 유도할 수 있게 한다. 이를 자기성찰이라 한다.



Langchain에서 대화 중 CoT는 RunnableWithMessageHistory를 사용해 보관할 수 있다. 다음은 CoT 구현을 보여준다.
def get_session_history(session_ids):if session_ids not in store:store[session_ids] = ChatMessageHistory()return store[session_ids]rag_with_history = RunnableWithMessageHistory(chain,get_session_history,input_messages_key="question",history_messages_key="chat_history")rag_with_history.invoke({"question": "What is ChatGPT?"},config={"configurable": {"session_id": "rag_llm"}},)
CoT의 일반적 실패 중 하나는 LLM이 산술 연산을 수행하지 못한다는 것이다.

수학 문제 예
PAL(Program-Aided Language Modeling) 및 PoT(Program-of-Thought) 프롬프트에서 수학 문제를 해결하는 프로그램으로 코드 언어 모델을 프롬프트한다. 표준 생각 연쇄 텍스트를 프로그램에 주석으로 삽입 할 수 있다.
그런 다음 Python 인터프리터를 실행하여 최종 답변을 생성한다. 이러한 방법의 이면에 있는 통찰력은 코드 인터프리터가 모든 종류의 계산을 위한 완벽한 도구를 제공하여 실패 사례를 잘못된 추론으로 줄인다는 것이다. 코드 스타일 프롬프트는 일반적으로 계획 작업에도 사용된다.

수학 문제 예시

설계된 대화 예시
멀티 에이전트 구조
다음 그림은 앞서 설명한 내용을 바탕으로 아키텍처를 설계한 것이다.

멀티 에이전트 LLM 아키텍처
이를 OpenAI 라이브러리를 이용해 구현하면 다음과 같다.
import datetime
import re
from pydantic import BaseModel
from typing import List, Dict, Tuple
from llm_agents.llm import ChatLLM
from llm_agents.tools.base import ToolInterface
from llm_agents.tools.python_repl import PythonREPLTool
FINAL_ANSWER_TOKEN = "Final Answer:"
OBSERVATION_TOKEN = "Observation:"
THOUGHT_TOKEN = "Thought:"
PROMPT_TEMPLATE = """Today is {today} and you can use tools to get new information. Answer the question as best as you can using the following tools:
{tool_description}
Use the following format:
Question: the input question you must answer
Thought: comment on what you want to do next
Action: the action to take, exactly one element of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation repeats N times, use it until you are sure of the answer)
Thought: I now know the final answer
Final Answer: your final answer to the original input question
Begin!
Question: {question}
Thought: {previous_responses}
"""
class Agent(BaseModel):
llm: ChatLLM
tools: List[ToolInterface]
prompt_template: str = PROMPT_TEMPLATE
max_loops: int = 15
# The stop pattern is used, so the LLM does not hallucinate until the end
stop_pattern: List[str] = [f'\n{OBSERVATION_TOKEN}', f'\n\t{OBSERVATION_TOKEN}']
@property
def tool_description(self) -> str:
return "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
@property
def tool_names(self) -> str:
return ",".join([tool.name for tool in self.tools])
@property
def tool_by_names(self) -> Dict[str, ToolInterface]:
return {tool.name: tool for tool in self.tools}
def run(self, question: str):
previous_responses = []
num_loops = 0
prompt = self.prompt_template.format(
today = datetime.date.today(),
tool_description=self.tool_description,
tool_names=self.tool_names,
question=question,
previous_responses='{previous_responses}'
)
print(prompt.format(previous_responses=''))
while num_loops < self.max_loops:
num_loops += 1
curr_prompt = prompt.format(previous_responses='\n'.join(previous_responses))
generated, tool, tool_input = self.decide_next_action(curr_prompt)
if tool == 'Final Answer':
return tool_input
if tool not in self.tool_by_names:
raise ValueError(f"Unknown tool: {tool}")
tool_result = self.tool_by_names[tool].use(tool_input)
generated += f"\n{OBSERVATION_TOKEN} {tool_result}\n{THOUGHT_TOKEN}"
print(generated)
previous_responses.append(generated)
def decide_next_action(self, prompt: str) -> str:
generated = self.llm.generate(prompt, stop=self.stop_pattern)
tool, tool_input = self._parse(generated)
return generated, tool, tool_input
def _parse(self, generated: str) -> Tuple[str, str]:
if FINAL_ANSWER_TOKEN in generated:
return "Final Answer", generated.split(FINAL_ANSWER_TOKEN)[-1].strip()
regex = r"Action: [\[]?(.*?)[\]]?[\n]*Action Input:[\s]*(.*)"
match = re.search(regex, generated, re.DOTALL)
if not match:
raise ValueError(f"Output of LLM is not parsable for next tool use: `{generated}`")
tool = match.group(1).strip()
tool_input = match.group(2)
return tool, tool_input.strip(" ").strip('"')
if __name__ == '__main__':
agent = Agent(llm=ChatLLM(), tools=[PythonREPLTool()])
result = agent.run("What is 7 * 9 - 34 in Python?")
print(f"Final answer is {result}")
마무리
LLM 모델의 한계를 넘는 AGI를 개발하기 위한 노력의 일환으로 관련 기술이 개발되고 있다. 멀티 에이전트를 이용하면, 좀 더 전문적인 LLM 시스템을 구축할 수 있다. 다음은 특정 약물을 발견, 설계하도록 설계된 다중 에이전트 LLM 모델 구조이다.
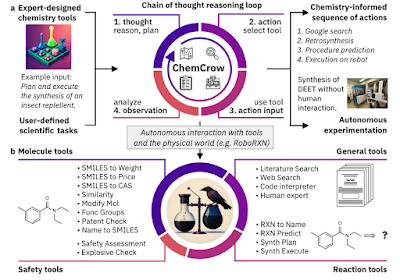
- LangChain & LangGraph: a framework for developing applications and agents powered by language models.
- AutoGPT: provides tools to build AI agents.
- Langroid: Simplifies building LLM applications with Multi-Agent Programming: agents as first-class citizens, collaborating on tasks via messages.
- AutoGen: a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks.
- OpenAgents: an open platform for using and hosting language agents in the wild.
- LlamaIndex: a framework for connecting custom data sources to large language models.
- GPT Engineer: automate code generation to complete development tasks.
- DemoGPT: autonomous AI agent to create interactive Streamlit apps.
- GPT Researcher: an autonomous agent designed for comprehensive online research on a variety of tasks.
- AgentVerse: designed to facilitate the deployment of multiple LLM-based agents in various applications.
- Agents: an open-source library/framework for building autonomous language agents. The library supports features including long-short term memory, tool usage, web navigation, multi-agent communication, and brand new features including human-agent interaction and symbolic control.
- BMTools: extends language models using tools and serves as a platform for the community to build and share tools.
- CrewAI: AI agent framework reimagined for engineers, offering powerful capabilities with simplicity to build agents and automations.
- Phidata: a toolkit for building AI Assistants using function calling.
부록: 코드 에이전트 레퍼런스
- Hands on LangGraph — Building a multi agent assistant | by Lucas Dahan | Medium
- Multi-AI Agent Code Review System, Generative AI | by Mehul Gupta | Data Science in your pocket | Medium
- Multi-Agent Conversation with AutoGen AI | by Tony Siciliani | Sep, 2024 | Medium
- Building a GenAI Career Assistant: A Multi-Agent Approach with LangGraph and Streamlit | by aman varyani | Medium
- Building AI Research Assistant: Multi-Agent RAG System Reading From Multiple Unstructured Sources | by Hanan Tabak | Medium
- Step by Step guide to develop AI Multi-Agent system using Microsoft Semantic Kernel and GPT-4o | by Akshay Kokane | Medium
- langgraph/docs/docs/tutorials/multi_agent/multi-agent-collaboration.ipynb at main · langchain-ai/langgraph
레퍼런스
- Reasoning with Large Language Models Instead of Asking Questions. How Agents will save the In-Context Prompting Problems. | LinkedIn
- Solving Reasoning Problems with LLMs in 2023 | by Zhaocheng Zhu | Towards Data Science
- LLM Powered Autonomous Agents | Lil'Log (lilianweng.github.io)
- LLM Agents: Introduction to Implementation (projectpro.io)
- AGI-Edgerunners/LLM-Agents-Papers: A repo lists papers related to LLM based agent (github.com)
- LangGraph (langchain.dev, korean, github)
- AI Agents in LangGraph - DeepLearning.AI
댓글 없음:
댓글 쓰기