3D 인식 모델은 많은 구조적 및 개념적 유사성을 공유하지만 기능 표현, 데이터 형식 및 목표에는 여전히 격차가 존재하여 통합되고 효율적인 3D 인식 프레임워크 설계에 어려움을 겪고 있다.
이 기술은 비전 중심 3D 인식의 두 가지 주요 작업인 점유 예측과 객체 감지를 통합하는 간단하고 효율적인 프레임워크인 UniVision을 제시한다. 구체적으로 우리는 보완적인 2D-3D 특징 변환을 위한 명시적-암시적 뷰 변환 모듈을 제안한다. 우리는 효율적이고 적응적인 복셀 및 BEV 특징 추출, 향상 및 상호 작용을 위한 로컬-글로벌 특징 추출 및 융합 모듈을 제안한다.
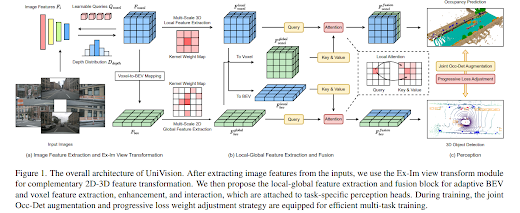
다중 작업 프레임워크 훈련의 효율성과 안정성을 가능하게 하는 공동 점유 감지 데이터 증대 전략과 점진적인 손실 가중치 조정 전략을 제안한다. nuScenes LiDAR 세분화, nuScenes 감지, OpenOccupancy 및 Occ3D를 포함한 4가지 공개 벤치마크에서 다양한 인식 작업에 대한 광범위한 실험을 수행한다. UniVision은 각 벤치마크에서 각각 1.5mIoU, 1.8NDS, 1.5mIoU, 1.8mIoU 이득으로 최첨단 결과를 달성했다.
댓글 없음:
댓글 쓰기