이 글은 트랜스포머(Transformer) 생성AI 모델로 다국어 번역기, 문장 분류, 이미지 설명 텍스트 생성 프로그램 개발 방법을 간략히 나눔한다. 쉽게 말해, 트랜스포머는 텍스트, 이미지 등 데이터를 숫자로 표현한 토큰으로 인코딩한 후, 목표 라벨 데이터 결과와 차이가 적은 방향으로 가중치인 어텐션(attension) 벡터를 갱신하여, 학습모델을 만드는 기술이다.
트랜스포머는 현재 문장 성격 및 특징 분류, 다국어 번역, 비전 이미지 설명 및 생성, 음성인식, Voice to Text, 음악작곡, 글 분류, 글 자동요약 등 다양한 영역에서 사용된다. 이 글은 관련 기능을 트랜스포머로 간단히 구현해 본다.


트랜스포머 개념 및 아키텍처
트랜스포머의 이론적 개념 등은 아래 링크를 참고한다.
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발 (daddynkidsmakers.blogspot.com)
- 어텐션 기반 트랜스포머 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법 소개 (daddynkidsmakers.blogspot.com)
- 간단한 트랜스포머 동작 원리와 Pytorch 기반 비전 트랜스포머 ViT 소개 (daddynkidsmakers.blogspot.com)
- 오디오, 영상, 텍스트, 센서, 3D깊이맵 멀티모달 딥러닝 모델 페이스북 imagebind 설치 및 사용기 (daddynkidsmakers.blogspot.com)
개발 준비
파이썬, CUDA 등이 설치되어 있다는 가정하에, 다음 명령어를 이용해, 관련 패키지를 설치한다.
pip install transfomers sentencepiece
간단한 텍스트 생성AI 개발
다음과 같이, 트랜스포머 모델에서 사전학습된 distilgpt2를 사용해, 간단한 텍스트 생성AI 코드를 개발해 본다.
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelWithLMHead.from_pretrained("distilgpt2")
input_ids = tokenizer.encode("I like gpt because it's", return_tensors='pt')
greedy_output = model.generate(input_ids, max_length=12)
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
실행, 결과 다음과 같이 I like gpt because it's 문장 이후를 자연스럽게 생성한다.
텍스트의 빈칸 단어 예측
다음은 MLM(Mask Language Model) 방식으로 학습된 모델을 이용해, [MASK] 토큰으로 정의된 단어를 문장 맥락을 고려해 예측하는 코드이다.
from transformers import pipeline
unmasker = pipeline('fill-mask', model='albert-base-v2')
unmasker("mlm and nsp is the [MASK] task of bert.")
결과는 다음과 같다. 빈칸 단어가 잘 예측된 것을 확인할 수 있다.

이미지 설명 텍스트 생성
이제 주어진 이미지를 설명하는 텍스트를 생성해 본다. 목표는 입력 이미지에 대해 두마리의 고양이가 누워있음을 표현하는 텍스트를 얻는 것이다.

앞의 방식대로, 사전 훈련된 모델을 이용한다. 다음을 코딩한다.
import torch
import matplotlib.pyplot as plt
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
candidates = ["three cats lying on the couch", "a photo of a cat", "a photo of a dog", "a lion", "two cats lying on the cushion"]
inputs = processor(text=candidates, images=image, return_tensors="pt", padding=True)
plt.imshow(inputs['pixel_values'][0][0]);
processor.tokenizer.decode(inputs['input_ids'][0])
model.eval() # eval mode
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
print(logits_per_image)
probs = logits_per_image.softmax(dim=1)
print(candidates[torch.argmax(probs).item()])
결과는 다음과 같이 이미지를 적절히 설명하고 있다.

사전학습모델 파인튜닝하기
기존 학습모델을 이용해, 텍스트 등을 생성하였지만, 그 결과가 마음에 들지 않는 다면, 파인튜닝을 해서 그 결과를 개선할 수 있다.
다음은 튜닝하지 않았을 때 결과를 출력하는 코드이다.
# no tuning
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=3)
dic = {0:'positive', 1:'neutral', 2:'negative'}
eval_list = ["I like apple", "I like pear", "I go to school", "I dislike mosquito", "I felt very sad", "I feel so good"]
ans = torch.tensor([0, 0, 1, 2, 2, 0])
model.eval()
with torch.no_grad():
for article in eval_list:
inputs = tokenizer.encode(article, return_tensors="pt",padding=True, truncation=True)
outputs = model(inputs)
logits = outputs.logits
print(f"{dic[logits.argmax(-1).item()]}:{article}")
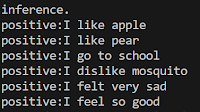
주어진 문장에 엉뚱한 답을 출력한다. 이는 원하는 결과가 아니다.
각 문장을 원하는 결과를 얻도록, 다음의 파인튜닝 코드를 실행해 학습한다.
# fine turning
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=1e-5)
model.train()
epochs = 50
losses = []
for epoch in range(epochs):
optimizer.zero_grad()
inputs = tokenizer.batch_encode_plus(eval_list, return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs, labels=ans)
logits = outputs.logits
loss = outputs.loss
loss.backward()
optimizer.step()
losses.append(loss)
print(f"epoch:{epoch+1}, loss:{loss}")
new_losses = [i.item() for i in losses]
결과를 다음과 같이 출력해 본다.
# plot results
import matplotlib.pyplot as plt
plt.plot(new_losses)
dic = {0:'positive', 1:'neutral', 2:'negative'}
eval_list = ["I like apple", "I like pear", "I go to school", "I dislike mosquito", "I felt very sad", "I feel so good"]
model.eval()
preds = []
with torch.no_grad():
for article in eval_list:
inputs = tokenizer.encode(article, return_tensors="pt",padding=True, truncation=True)
outputs = model(inputs)
logits = outputs.logits
pred = logits.argmax(-1).item()
preds.append(logits.argmax(-1).item())
print(f"{dic[pred]}:{article}")
각 문장이 어떤 느낌인지 원하는 결과로 예측한다.
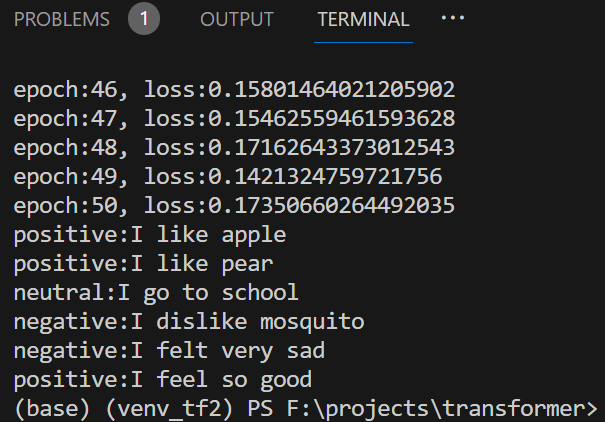
문장 요약하기
학습된 BERT 모델 중에 문장을 요약하는 기능을 하는 모델이 있다. 다음과 같이 코딩해 본다.
import re
from transformers import BartTokenizer, TFBartForConditionalGeneration
model = TFBartForConditionalGeneration.from_pretrained('facebook/bart-large')
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large')
article = """
A transformer is a deep learning architecture that relies on the parallel multi-head attention mechanism.[1] The modern transformer was proposed in the 2017 paper titled 'Attention Is All You Need' by Ashish Vaswani et al., Google Brain team. It is notable for requiring less training time than previous recurrent neural architectures, such as long short-term memory (LSTM),[2] and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl, by virtue of the parallelized processing of input sequence.[3] Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. Though the transformer paper was published in 2017, the softmax-based attention mechanism was proposed earlier in 2014 by Bahdanau, Cho, and Bengio for machine translation,[4][5] and the Fast Weight Controller, similar to a transformer, was proposed in 1992 by Schmidhuber.[6][7][8]
This architecture is now used not only in natural language processing and computer vision,[9] but also in audio[10] and multi-modal processing. It has also led to the development of pre-trained systems, such as generative pre-trained transformers (GPTs)[11] and BERT[12] (Bidirectional Encoder Representations from Transformers).
"""
print(article)
article = re.sub(r"[:.]\[[0-9]+\](.*?)\([0-9]+\)|.?[([][0-9]+[])]|\n|\r", r"", article)
print(article)
inputs = tokenizer([article], max_length=1024, return_tensors='tf', truncation=True)
summary_ids = model.generate(inputs['input_ids'], num_beams=5, max_length=25)
print(''.join([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids]))
결과는 다음과 같다.

참고로, 다음은 기본 BERT 모델보다 큰 문장을 처리하는 BigBERT 모델인 PEGASUS(Gap Sentence Generation)를 이용한 요약 문장 생성 코드이다. 이 모델은 앞서 MLM 문제 학습 모델과는 다르게, 문장 전체를 MASK해 다음 문장을 예측하도록 학습되었다.
from transformers import PegasusForConditionalGeneration, PegasusTokenizer
import torch
model_name = 'google/pegasus-xsum'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = PegasusTokenizer.from_pretrained(model_name)
model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
inputs = [
"""
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. Recent work shows that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models.
"""
]
batch = tokenizer(inputs, truncation=True, padding='longest', return_tensors="pt").to(device)
translated = model.generate(**batch)
generated_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
print(generated_text[0])
다국어 번역하기(중국-영어-한글)
다음은 다국어 번역 학습 모델을 이용해, 글을 번역하는 코드이다.
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
chinese_text = "我愛你. 你也愛我嗎"
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
tokenizer.src_lang = "ko"
korean_text = "딥러닝 모델을 이용해, 사람들은 업무 생산성을 높이고 있지만, 어떤 사람들은 일자리에 큰 위협을 느끼고 있다."
encoded_ko = tokenizer(korean_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_ko, forced_bos_token_id=tokenizer.get_lang_id("en"))
print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
english_text = "I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin, but by the content of their character."
tokenizer.src_lang = "en"
encoded_en = tokenizer(english_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.get_lang_id("ko"))
print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
결과는 다음과 같다.

대화형 챗봇처럼 문장 생성하기
다음은 마이크로소프트에서 학습한 대규모 대화 텍스트 모델이다. 이를 이용해, 챗봇과 같은 자연스러운 문장을 생성할 수 있다.
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-small")
model = AutoModelWithLMHead.from_pretrained("microsoft/DialoGPT-small")
input_ids = tokenizer.encode("I like gpt because it's", return_tensors='pt')
greedy_output = model.generate(input_ids, max_length=30)
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
마무리
트랜스포머를 이용하면, GPT와 같은 생성AI를 개발할 수 있다. 앞서 코드를 보면 알겠지만, 트랜스포머 사용 절차는 대부분 다음과 같다.
1. 원하는 기능의 사전학습모델 다운로드2. 해당 토크나이저 다운로드3. 입력 데이터 토큰화4. 모델에 토큰화된 데이터 입력해 출력 데이터 생성5. 출력 데이터를 디코딩해 원하는 생성 데이터 획득
트랜스포머는 현재 문장 성격 및 특징 분류, 다국어 번역, 비전 이미지 설명 및 생성, 음성인식, Voice to Text, 음악작곡, 글 분류, 글 자동요약 등 다양한 영역에서 사용된다.
레퍼런스
- Huggingface, transformers · PyPI
- Fuyu-8B: A Multimodal Architecture for AI Agents (adept.ai)
- jina-ai/jina: ☁️ Build multimodal AI applications with cloud-native stack (github.com)
- yccyenchicheng/SDFusion (github.com)
- threedle/text2mesh: 3D mesh stylization driven by a text input in PyTorch (github.com)
- timzhang642/3D-Machine-Learning: A resource repository for 3D machine learning (github.com)
- Language Modeling with nn.Transformer and torchtext — PyTorch Tutorials 2.1.1+cu121 documentation
- nn.Transformer 와 torchtext로 시퀀스-투-시퀀스(Sequence-to-Sequence) 모델링하기
- Build your own Transformer from scratch using Pytorch | by Arjun Sarkar | Towards Data Science
- A complete Hugging Face tutorial: how to build and train a vision transformer | AI Summer









