
건설 객체 탐지 딥러닝 모델 결과
YOLO 개요
본 내용은 이미 다크넷 및 YOLO 개발 환경이 구축되었다고 가정하고 진행한다. YOLO 개발환경이 준비되지 않았다면 아래 링크를 참고한다.
- YOLO: Real-time object detection
- 딥러닝 기반 객체 탐색 기법 - YOLO 사용 방법
- YOLO 딥러닝 기반 도로 표지판 인식 방법
- YOLO v4 동작 방식 설명
YOLO 소개
YOLO 출력 구조 이해
YOLO의 예측 결과는 클래스 별로 예측된 경계박스(anchor box={cx, cy, width, height})이다. 이 경계박스를 다음 그림과 같이 클래스별로 입력된 학습데이터에 맞게 조정해 학습모델을 만든다.

그러므로, YOLO의 학습 모델은 train data={image, {anchor box, label}*} 가 입력되고, 출력으로 output={anchor box, objectness score, class scores}* 가 된다(*=multiple). 이는 이미지를 격자화해, 3개의 aspect ratio별 anchor box로 출력되는 데, 이 결과로 COCO데이터셋 80개 클래스 경우 각 격자(cell)마다 depth 방향으로 (4 + 1 + 80) * 3 = 255 개 depth가 쌓이게 된다.
경계박스 정의
이미지 별 격자 크기는 13x13, 26x26, 52x52인 3가지 종류로 나뉜다. 다음 그림은 이를 보여준다.

참고로, 기존 방법(SSD, R-CNN)은 정해진 ratio의 경계박스만 사용했다.
- YOLO v1: 98 boxes=7x7 cells. 2 boxes per cell. 448x448 pixels
- YOLO v2: 845 boxes=13x13 cells. 5 anchor boxes. 416x416 pixels
- YOLO v3: 10,647 boxes=((52x52) + (26x26) + (13x13)) x 3 (anchor box count). 416x416 pixels
모델 구조 재활용
앞서 설명한 부분을 제외한 나머지 부분은 기존에 개발된 CNN(Convolutional Neural Network), FCN(Fully Convolutional Network), ResNet 등을 재활용한다.
앞서 설명한 부분을 제외한 나머지 부분은 기존에 개발된 CNN(Convolutional Neural Network), FCN(Fully Convolutional Network), ResNet 등을 재활용한다.
일반적으로 활용되는 ResNet은 네트워크의 깊은 깊이로 인한 gradient vanishing/exploding 문제로 Degradation되는 현상을 피하기 위해, 개발된 것이다. 만약, 신경망 학습목적이 입력 x를 목적값 y로 맵핑하는 함수 H(x)를 탐색하는 것이라면, 학습방향은 H(x) − y를 최소화하는 것이다. ResNet에서는 관점을 바꿔 H(x) − x를 탐색하도록 수정한다. 입출력 잔차를 F(x) = H(x) − x로 정의를 하고 학습은 이 F(x)를 탐색한다. 이 F(x)가 잔차이므로, 이를 Residual learning, Residual mapping라 한다. 계산 상으로는 단순히 F(x) + x를 한 것으로 그 전 레이어 값을 더하고 relu연산 적용한 것 뿐인데 이런 문제를 개선해 높은 성능을 얻었다.


ResNet 핵심 구조(좌=기존. 우=ResNet)
Up-sampling은 저해상도에서 고해상도로 이미지 스케일 업할 때 사용된다. 이는 보간법과 유사한 방식으로, Transpose convolution, Deconvolution으로 불린다.
최종 YOLO 모델 구조
이런 입출력을 고려해 CNN 레이어를 개발하면, 다음과 같은 YOLO 딥러닝 모델이 된다.

YOLO 딥러닝 모델 레이어 구조(Xin Nie 외, 2019)

YOLO 관련 상세 내용은 아래를 참고한다.
- YOLO real-time object detection presentation
- Object Detection with R-CNN, SSD, and YOLO
- An Introduction to different Types of Convolutions in Deep Learning
YOLO 실행 환경 테스트
YOLO가 제대로 설치되었다면 제대로 실행되는 지 테스트해보기 우해 COCO 데이터를 다운로드 받는다.
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
cfg/coco.data 파일의 COCO 데이터를 수정한다. path-to-coco는 coco 데이터셋의 경로이다.
1 classes= 80
2 train = <path-to-coco>/trainvalno5k.txt
3 valid = <path-to-coco>/5k.txt
4 names = data/coco.names
5 backup = backup
다음과 같이 학습한다.
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
제대로 수행되면, 다음 단계에서 YOLO v3 기반 예측 모델을 개발해 보겠다.
딥러닝 기반 예측 모델 개발 순서YOLO가 제대로 설치되었다면 제대로 실행되는 지 테스트해보기 우해 COCO 데이터를 다운로드 받는다.
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
cfg/coco.data 파일의 COCO 데이터를 수정한다. path-to-coco는 coco 데이터셋의 경로이다.
1 classes= 80
2 train = <path-to-coco>/trainvalno5k.txt
3 valid = <path-to-coco>/5k.txt
4 names = data/coco.names
5 backup = backup
다음과 같이 학습한다.
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
이미지 데이터를 이용할 수도 있다.
wget https://pjreddie.com/media/files/yolov3-openimages.weights
./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
딥러닝 모델을 학습하고, 이를 통해 사용자 데이터에서 객체 예측 모델을 개발하는 순서는 다음과 같다.

이 글에서 딥러닝 모델 사용 목적은 건설 객체 중 건설장비와 작업자를 인식하는 것이다. 딥러닝 모델은 YOLO v3로 선정하였고, 전이학습을 사용한다. 이후 과정은 다음과 같다.
딥러닝의 가장 큰 장애물은 학습 데이터를 준비하는 것이다. 지금까지 딥러닝 연구자들의 많은 노력으로 수많은 딥러닝 모델이 이미 개발되어 있다. 잘 활용하면 되는 좋은 모델이 많다. 하지만, 각자 응용 영역에 적용할 수 있는 데이터는 매우 제한되어 있다.
딥러닝에서는 데이터가 소스코드나 마찬가지이므로, 학습용 데이터 확보가 매우 중요하다. 하지만, 학습 데이타를 만들기 위해서는 매우 노동집약적인 작업이 필요하다. 참고로, DQN(Deep Q-Networks)와 같은 강화학습(reinforcement learning)을 사용할 수도 있다. 하지만, 강화학습은 일정 규칙을 추출할 수 있어 바둑과 같이 학습 데이터 생성을 예상할 수 있는 문제에서 적용이 가능한 방법이다.
본 글에서는 학습 데이터를 건설 중장비 이미지를 준비해 본다. 그리고, CNN 기반 딥러닝 모델을 학습해 본다.
이미지 준비를 위해 구글에서 이미지를 다운로드하는 프로그램을 다음과 같이 설치하고, 실행한다. 이 작업을 위해서는 미리 아나콘다 개발 환경이 준비되어 있어야 한다(설치 방법 참고).
- chromedriver.chromium.org/downloads 에서 구글 크롬 드라이버를 다운로드 받는다. 압축을 풀어 chromedriver.exe 파일을 얻는다. 만약, 리눅스라면, 다음과 같이 크롬을 설치한 후 리눅스용 chromedriver를 다운로드 받아야 한다. $ wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
$ sudo dpkg -i google-chrome-stable_current_amd64.deb - pip install tqdm 명령으로 패키지를 설치한다.
- git clone github.com/ultralytics/google-images-download 으로 소스를 다운받는다. cd google-images-download 명령을 입력한다.
- python bing_scraper.py --search "heavy construction equipment" --limit 600 --download --chromedriver "chromedriver.exe" 명령을 입력한다. 600개 이미지를 다운로드할 것이다.

인터넷 이미지 자동 다운로드 실행 과정

인터넷 이미지 자동 다운로드 결과
이제 중복, 불필한 데이터 등을 삭제하는 등 필터링하고, 별도 학습용 폴더에 저장한다. 참고로, 전체 588개가 다운로드되었고, 446개 필터링된 데이터를 확보하였다. 필터링 작업은 20분 소요되었다.
다음과 프로그램을 실행해 학습 데이터 파일명을 변경한다.
import os
def rename_multiple_files(path,obj):
i=0
for filename in os.listdir(path):
try:
f,extension = os.path.splitext(path+filename)
src=path+filename
dst=path+obj+str(i)+extension
os.rename(src,dst)
i+=1
print('Rename successful.')
except:
i+=1
path='G:\\05.Data\\InfraImage\\google-images-download\\images\\heavy_equipment_construction_field\\'
obj='con_eq_'
rename_multiple_files(path,obj)
다음과 프로그램을 실행해 데이터 크기를 조정한다
from PIL import Image
import os
def resize_multiple_images(src_path, dst_path):
# Here src_path is the location where images are saved.
for filename in os.listdir(src_path):
try:
img=Image.open(src_path+filename)
new_img = img.resize((500, 500))
if not os.path.exists(dst_path):
os.makedirs(dst_path)
new_img.save(dst_path+filename)
print('Resized and saved {} successfully.'.format(filename))
except:
continue
src_path = 'G:\\05.Data\\InfraImage\\google-images-download\\images\\heavy_equipment_construction_field\\'
dst_path = 'G:\\05.Data\\InfraImage\\google-images-download\\images\\heavy_equipment_construction_field_resize\\'
resize_multiple_images(src_path, dst_path)

학습 데이터 rename, resize 결과
참고로, 이미지 데이터가 부족하여 학습 정확도에 문제가 생긴다면, 다음 프로그램을 설치해 데이터 파일을 증폭시킨다. 참고로, imgaug는 bounding box(바운딩 박스)를 유지한 상태로 데이터 파일을 증폭시킬 수 있다.
- imgaug(image augmentation)
다음과 같이 imgaug를 설치한다.
conda config --add channels conda-forge
conda install imgaug
설치되지 않으면, 다음을 실행한다.
pip install imgaug
이미지 증폭 프로그램을 실행한다.

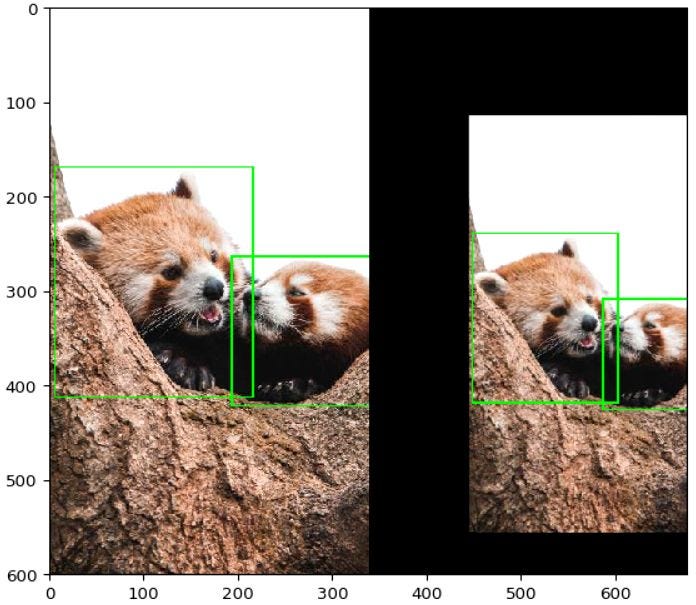
이미지 증폭 결과 예
이제, 데이터를 준비했으므로, 파일들은 다음과 같이 폴더로 분류해 놓는다. 전체 100이라면, train에 70%, test에 10%, val에 20%을 할당한다.
train
test
val
학습 데이터 라벨링
BBox Label Tool을 사용해 데이터 라벨링을 수행한다. BBox 도구가 마음에 들지 않는 다면 여기(라벨링 도구 소개) 다른 라벨링도구를 사용할 수도 있다.
참고로, 이 도구는 최신 파이썬에서는 호환성 에러가 발생한다. 이 경우 에러를 수정해 사용하거나, 여기에 이미 수정한 소스를 다운로드 받아 사용한다.

라벨링 도구 에러 수정
이 도구를 이용해 각 이미지 별 경계 박스 설정 시 시간은 평균 1~10초 정도 걸린다. 한 장당 평균 2~5개의 경계박스를 선택해야 한다. 실제, 미리 준비한 중장비 이미지 데이터는 446장이었고, 이 데이터는 라벨링에 약 50분 시간이 소요되었다. 이 경우, 라벨링 속도는 10장/분이고, 6초당 1장 라벨링 속도이다. 실제 50분 가까이 라벨링하면, 손과 눈에 급격한 피로도가 몰린다(법정교육 동영상 클릭 노가다하는 느낌 -.-). 그래서 대략 10분 정도를 쉬면서 라벨링하였다. 참고로, 이미지 별 클래스 개수와 라벨 난이도에 따라 이 시간은 크게 달라질 수 있다.




중장비 라벨링 과정
건설 작업자의 경우, 450장 라벨링하는 데, 60분이 소모되었다. 이는 7.5장/분 속도로 라벨링한 것이다. 꽤 많은 수의 데이터임에도 불구하고, 다양한 각도와 거리에서 촬영한 이미지 데이터는 부족한 편이다.


작업자 라벨링 과정
객체 대상에 따라 라벨링 작업 특성이 다를 수 있다. 예를 들어, 사람은 장비보다 겹치는 경우가 많다. 중장비의 경우 객체 대상을 본체만으로 하는 지, 부착장비까지로 하는 지에 따라 선택 범위가 달라진다.
라벨링된 결과는 Labels 폴더에 각 파일명별로 다음과 같이 기록된다.

라벨 파일 폴더

라벨 파일 데이터 구조
라벨 데이터 형식 변환 및 학습 파라메터 설정
이제 라벨 데이터 파일들을 darknet 형식으로 변환해야 한다. 참고로, 딥러닝 모델 학습시 사용하는 포맷 세부 내용은 다음 링크를 참고한다.
변환 대상 데이터셋의 폴더 구조는 다음과 같다고가정한다. 이미 각 라벨 폴더 별로 라벨링 정보가 저장된어 있는 상태이다.
BBox
Labels
001
002
Images
001
002
이를 다크넷에서 학습 가능하도록 다음 구조로 변환해야 한다.
custom_data
cfg
images
labels
우선 다음과 같이 명령을 실행한다.
cp BBox/Images/001/*.jpg custom_data/images/
BBox 도구로 생성된 라벨 파일을 다크넷에 학습되도록 다음과 같이 간단한 파이썬 소스 코드를 개발한다.
# Program. convert_BBox_darknet # Programming by KTW
# email. laputa99999@gmail.com # Note. You are responsible for any problems caused by use this program.
import os import glob from os import listdir, getcwd from tokenize import tokenize, untokenize, NUMBER, STRING, NAME, OP # Modify the below parametercategoryCount = 2names = ['con_eq', 'worker'] width = 500height = 500 # Programroot = ''def createFolders(root): try: os.mkdir(root) os.mkdir(root + 'images') os.mkdir(root + 'labels') except: return return def saveNames(root, file): try: fileName = open(root + file, "w") for index in range(categoryCount): fileName.write(names[index] + '\n') except: return return def saveLabel(folder, filename, imageName, category, object, w, h, BBoxList): try: file = open(folder + filename, "w") for BBox in BBoxList: # type: object objWidth = float(BBox[2] - BBox[0]) / float(w) objHeight = float(BBox[3] - BBox[1]) / float(h) centerX = objWidth / 2 + float(BBox[0]) / float(w) centerY = objHeight / 2 + float(BBox[1]) / float(h) file.write(str(category) + ' ') file.write('{:.6f}'.format(centerX) + ' ') file.write('{:.6f}'.format(centerY) + ' ') file.write('{:.6f}'.format(objWidth) + ' ') file.write('{:.6f}'.format(objHeight) + '\n') except: return return def convertBBoxToDarknet(root, labelDir, category, w, h): labelList = glob.glob(os.path.join(labelDir, '*.*')) for filename in labelList: BBoxList = [] try: file = open(filename, "r") count = file.readline() count = count.rstrip('\n') num = int(count) for line in range(num): BBox = file.readline() BB = BBox.split() points = [] for pt in BB: points.append(int(pt)) BBoxList.append(points) except: continue object = names[category] name = os.path.basename(filename) name, extension = os.path.splitext(name) labelFile = name + '.txt' saveLabel(root + 'labels/', labelFile, name, category, object, w, h, BBoxList) return def saveTrainTestsets(root, train, test, ratio): try: fileTest = open(root + train, "w") fileTrain = open(root + test, "w") imageDir = os.path.join(root + 'images/') imageList = glob.glob(os.path.join(imageDir, '*.jpg')) labelDir = os.path.join(root + 'labels/') labelList = glob.glob(os.path.join(labelDir, '*.*')) no = 0 count = len(labelList) trainCount = int(float(count) * ratio) for file in imageList: name = os.path.basename(file) name, extension = os.path.splitext(name) labelFile = root + 'labels/' + name + '.txt' if os.path.isfile(labelFile) == False: continue if no < trainCount: fileTest.write(file + '\n') else: fileTrain.write(file + '\n') no = no + 1 except: return return def saveYOLOdatafile(root): try: file = open(root + 'detector.data', "w") file.write('classes=' + str(categoryCount) + '\n') file.write('train=custom_data/train.txt' + '\n') file.write('valid=custom_data/test.txt' + '\n') file.write('names=custom_data/custom.names' + '\n') file.write('backup=backup/' + '\n') except: return return wd = getcwd() root = wd + '/custom_data/'createFolders(root) saveNames(root, "custom.names") for index in range(categoryCount): labelDir = getcwd() + '/' labelDir = labelDir + os.path.join(r'BBox/Labels/', '%03d' % (index + 1)) convertBBoxToDarknet(root, labelDir, index, width, height) saveTrainTestsets(root, 'train.txt', 'test.txt', 0.8) saveYOLOdatafile(root)
이 파이썬 스크립트를 다음과 같이 실행한다.
python convert_BBox_darknet.py
다음과 같이 darknet 학습용 파일들이 생성된다.

labels 폴더는 다음과 같이 images 폴더 파일에 대응되는 이미지 각각에 대한 라벨 정보가 다음과 같이 정의되어 있다.

0 0.658000 0.601000 0.520000 0.286000
0 0.279000 0.597000 0.234000 0.210000
0 0.167000 0.652000 0.166000 0.108000
0 0.279000 0.597000 0.234000 0.210000
0 0.167000 0.652000 0.166000 0.108000
각 라벨 파일 형식은 다음과 같다.
class_ID center_x center_y box_width box_height
class_ID = {0: con_eq, 1: worker}
center_x = box_center_x / image_width
center_y = box_center_y / image_height
box_width = width / image_width
box_height = height / image_height
image_width = image width (pixel unit)
image_height = image height (pixel unit)
width = boundary box width (pixel unit)
height = boundary box height (pixel unit)
custom_data 폴더 내 다른 파일들 역할은 다음과 같다.
custom.name = class names
detector.data = 훈련용 데이터 파일 설정 정보
test.txt = 테스트용 파일 리스트
train.txt = 훈련용 파일 리스트
학습 파라메터를 담고 있는 detector.data 파일 구조는 다음과 같다.
classes=2
train=custom_data/train.txt
valid=custom_data/test.txt
names=custom_data/custom.names
backup=backup/
이 라벨 데이터셋의 경우에는 클래스가 2개 밖에 없지만, 이를 추가하고 싶다면, 앞에서 설명한 부분을 수정해야 한다. 이는 스크립트에서 다음 부분을 수정하면 자동 생성 된다.
# Modify the below parametercategoryCount = 2names = ['con_eq', 'worker']
사용자 데이터셋 딥러닝 학습
이제 사용자가 만든 데이터셋으로 욜로를 학습해 보자. 이를 위해, 클래스와 관련된 부분의 욜로 학습 설정 파일을 수정해야한다.
다크넷의 cfg/yolov3.cfg 를 custom_data/cfg/yolov3-custom.cfg 으로 복사한다.
그리고, yolov3-custom.cfg에서 아래 부분을 수정, 저장한다. 아래 글에서 () 안은 주석이다.
- 작은 이미지 데이터셋 사용의 경우, batch = 64
- max_branches=4000
- steps=3200,3600 (max_branches * 0.8, max_branches * 0.9)
- classes=2 (at line number 610, 696, 783)
- filters=21 (at line number 603, 689, 776. filters=(classes + 5) * 3)
./darknet detector train [.data file location] [.cfg file location] [pretrain weight model file]
참고로 학습전에 사전 학습된 darknet53.conv.74 모델 파일을 사용하면 학습분포가 많아지고, 학습시간도 단축된다. 이런 방법을 전이학습기법이라 한다.

YOLO에서 전이학습에 사용된 Darknet53(Joseph Redmon 외, 2018)
전이학습은 새로운 모델로 학습할 때보다 이미지 분포가 더 크기 때문에 효율적 학습이 가능하다. 전이학습은 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델이다. 일반적으로, 큰 데이터셋으로 모델을 학습하는 것은 오랜 계산 시간과 연산량이 필요하므로, 보통 VGG, Inception, MobileNet 등 이미 잘 학습되어 있는 모델들을 가져와 사용한다(참고로, VGG, Inception같은 ConvNets 학습은 보통 다중 GPU 하에서도 2~3주 걸린다).
여기서 사용하는 darknet53.conv.74 은 이미지넷 데이터셋을 darknet으로 학습한 모델이다. 이 데이터셋은 본 건설 객체와 일부 유사한 객체들이 학습되어 있다. 다만, 본 데이터셋과 fitting되어야 제대로 학습할 수 있다. 전이학습에서는 이 모델을 backbone으로 사용한다(참고 - 차이점).
학습을 위해 다음과 같이 실행한다. 만약, 사전학습 모델을 사용하지 않는다면, 해당 파일명은 입력하지 않는다.
./darknet detector train custom_data/detector.data custom_data/cfg/yolov3-custom.cfg darknet53.conv.74
실행 결과, 다음과 같이 학습이 진행될 것이다. 이 로그는 각 이미지의 학습 상황을 알려준다. Region 82, 94, 106 은 학습 마스크 크기를 말한다. 마스크 크기가 클수록 작은 객체를 예측 가능하다. IOU 는 서브디비전에서 실제와 예측된 경계박스의 교차율을 뜻하며, 1에 가까울수록 좋다. 클래스 값은 1에 가까울 수록 학습이 잘되고 있다는 의미이다. No Obj 는 작은 값일 수록 좋다.


count=positive classes 를 의미한다. .5R, .75R는 recall/count를 의미한다. Recall, IoU, Precision의미는 다음 그림을 참고하라.


이 사례에서는 학습 시간이 대략 12시간 30분 걸렸다(i7. GTX 1070 8G. 16G). 생성된 학습 모델 크기는 346.3MB이다(Model Download).
객체 예측모델 학습결과 객체탐지 정확도 테스트
학습이 끝났으면, 테스트를 해 보자.
우선 비교를 위해, 기존 yolov3.weight 모델로 예측해 본다. 다음 그림과 같이 아무것도 인식되지 않는다.
./darknet detect cfg/yolov3.cfg yolov3.weights custom_data/images/con_eq_65.jpg

다음과 같이 학습된 모델 파일을 이용해 이미지를 예측해 보자. 결과와 같이 잘 예측된다. 커스텀된 학습 모델이 훨씬 높은 인식률을 보이고 있는 것을 알 수 있다.
./darknet detector test custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights ./custom_data/images/con_eq_65.jpg


다른 이미지도 인식해 본자. 기존 yolov3.weight 모델로 인식한 결과는 다음과 같다. 객체 4개만 인식되고 1개는 오탐되었다.
./darknet detect cfg/yolov3.cfg yolov3.weights custom_data/images/con_worker_392.jpg


다음과 같이, 새로 학습한 모델로 테스트해본다. 모두 제대로 인식된다. 기존보다는 직접 학습한 custom weight 모델 결과가 더 나은 것을 확인할 수 있다.
./darknet detector test custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights ./custom_data/images/con_worker_392.jpg

다음은 웹캠으로 학습된 중장비, 작업자를 인식해본 결과이다. 해상도가 그리 좋지 못함에도 잘 인식된다. 다만, YOLO v2 보다 속도가 느리다(v3가 체감상 2배 이상이 느리나, 정확도는 더 높다).
./darknet detector demo custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights참고로, 미리 준비된 동영상으로 테스트하고 싶다면, 다음처럼 명령을 입력해 보자.
./darknet detector demo custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights test7.MOV
다음은 건설 현장 영상을 학습된 모델에 입력해 객체를 인식한 결과이다. 학습 데이터에 전혀 없는 Top view 등은 인식이 잘 되지 않지만, 비슷한 각도의 이미지들은 잘 인식되는 것을 알 수 있다.
이제 잘 인식되지 않는 부분을 확인하였으니, 이를 보완해 모델을 개선해 본다. 다음은 개선된 모델을 이용해 객체를 인식한 결과이다. 훈련한 건설 장비 객체 탐색이 잘 되는 것을 알 수 있다.
마무리
지금까지 사용자가 학습 데이터를 준비하고 학습 시켜야 할 때 욜로에서 어떻게 작업하는 지 전체적인 프로세스를 나눔해 보았다. 기존 욜로의 학습 모델로는 건설과 같이 특정한 분야에 대한 객체 인식은 제대로 되지 않는다. 이 경우, 별도 학습 데이터를 준비해 딥러닝 훈련 시켜야 한다. 학습 데이터가 부족한 경우, 정확도가 높아지지 않는다. 이 사례에서는 학습 데이터가 많은 편은 아니다. 다만, 객체 인식에 큰 문제가 없는 수준으로 학습 데이터를 구축하고 훈련을 진행해서, 큰 문제 없이 테스트에서 건설 객체들이 학습되는 것을 확인할 수 있었다. 학습 데이터가 많아지고, 클래스 수가 높아질수록 데이터 준비 및 학습에 많은 노력과 시간이 들어간다.
당연한 말이지만, 이렇게 학습된 커스텀 모델은 해당 분야 데이터에서만 유효하다. 이를 고려해, 딥러닝에 필요한 데이터셋, 학습모델 등을 활용해야 한다.
레퍼런스
이 글은 다음 링크를 참고하였다.
- YOLO v4 — Superior, Faster & More Accurate Object Detection
- YOLO darknet github
- Keras FCN
- DeepLab for Video
- YOLO v3 github
- Custom object training and detection with YOLOv3 (#2)
- How to train YOLO model
- Transfer learning from pre-trained models
- How to implement a YOLO v3 object detector
- Object Detection with Darknet (#2, #3, #4, #5)
- YOLO v2, YOLO9000
- YOLO Darknet v2
- OpenPose (#2)
- Google Images Download and Docs (Error solution)
- Prepare your own data set for image classification in Machine learning Python
- How to prepare Imagenet dataset for Image Classification
- Google Cloud, 학습 데이터 준비
- imgaug with bounding box
- Learn to Augment Images and Multiple Bounding Boxes for Deep Learning in 4 Steps
- CNN architecture - VGG, ResNet
- Xin NieMeifang YangWen LiuWen Liu, 2019, Deep Neural Network-Based Robust Ship Detection Under Different Weather Conditions, IEEE
- Joseph Redmon, Ali Farhadi, 2018, YOLOv3: An Incremental Improvement
- Train, Test, Validation dataset
well explained article keep up the good work also check mine article on serial.print make cool projects on arduino.
답글삭제thanks^^
삭제안녕하세요! 데이터를 어떻게 전처리하는지 라벨링하는지 그리고 학습하는 과정 테스트 과정까지 상세히 남겨주셔서 정말 도움이 되었습니다 감사합니다!
답글삭제한가지 질문 드리고싶은 부분이있는데,
입력값이 416 * 416 * 3 으로 알고있는데 그러면 이미지를 416으로 리사이이즈 해야하는 것인가요?
그리고 13, 26, 52 스케일로 결과가 나오게 되는데 라벨도 그러한 이미지 스케일로 주어아야하는지 궁금합니다.
답변주시면 정말 감사하겠습니다!
YOLO 할때는 이미지 리사이즈에 대해 신경쓰진 않았던것 같습니다(오래전 일이라 정확한 기억은 아닙니다).
삭제안녕하세요!
답글삭제너무 정리를 잘 해놓으셔서 글 너무 재밌게 읽었습니당
혹시 YOLACT OUTPUT을 이미지로 저장하는거 말고도 다른 방법도 써보셨나요ㅠㅠ? txt라던가 csv라던가ㅠㅠ.. 마스크영역이나 클래스같은 내용들 ㅠㅠ....
아무리 찾아도 자료가 없어서 혹시나 하고 여쭤봅니당..ㅎㅎㅎ
보통, 실행할 때 출력부분이 있고, 이 출력을 파싱해 사용하거나, 직접 코드를 수정해, csv를 저장하도록 해야 합니다.
삭제