이 글은 데이터베이스 모델링에 많이 사용되는 ERD 모델링 도구 중 무료 소프트웨어 소개 링크를 소개한다.
ERD는 가끔 데이터베이스나 구조 모델링할 때, 엔티티간 관계를 설계하기 위해 사용한다. 최근에는 오픈소스 및 웹 기반 실행 도구도 많이 있어, 이를 이용하면, 무료로 ERD 디자인 할 수 있다.

ERD 디자인 예

ERD 모델링 도구 예
이 글은 데이터베이스 모델링에 많이 사용되는 ERD 모델링 도구 중 무료 소프트웨어 소개 링크를 소개한다.
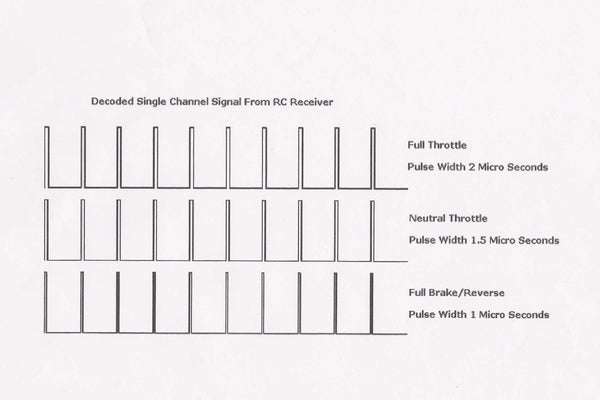
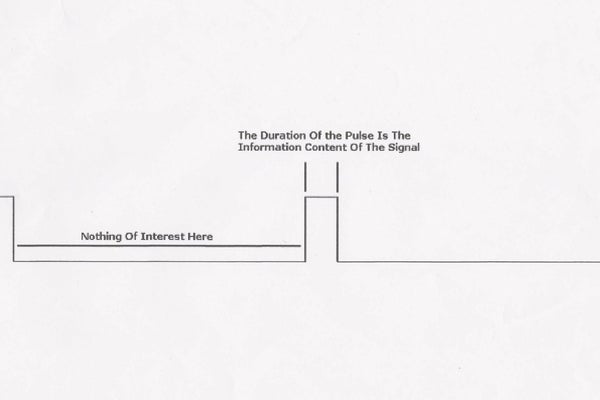
이 글은 아두이노 기반 FS-IA10B RF 수신기 채널 신호 PWM(Pulse Width Modulation) 출력 방법을 간단히 정리한 것이다.

수신기에서 들어오는 PWM신호를 오실로스코프로 확인하면 다음과 같다.
이 글은 LiPO 배터리 연결잭을 간단히 정리한 글이다.
배터리를 사용하다 충전을 할 때 매우 다양한 배터리 연결잭 종류로 인해 피곤한 경우가 종종 있다. 이 경우 연결잭 종류를 확인하고, 직접 납땜 제작해야 한다.




이 글은 엔비디아(nvidia jetson) 나노(nano) 이미지 백업 및 복구 방법을 간략히 설명한 것이다. 크게 2가지 방법이 있다. 하나는 Win32 Disk Imager, 다른 하나는 DD 명령을 사용하는 방법이다.
Win32 Disk Imager
다음 링크에서 프로그램 다운받아 설치한 후 실행한다.
실행 후 저장할 이미지 이름과 클론(복제)할 SD memory, USB memory를 USB 포트에 연결하고, Read 버튼을 클릭한다. 그럼 복제가 시작된다.
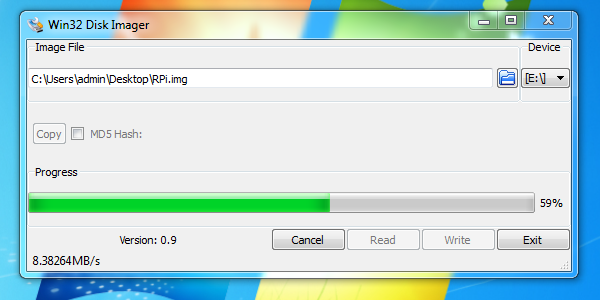
복구는 반대로 비어 있는 메모리를 USB 포트에 연결하고, Write 버튼을 클릭하면 된다.
DD명령
레퍼런스
이 글은 오픈소스 R 스튜디오를 사용해 데이터 신뢰도를 간단히 검증할 수 있는 방법인 크론바흐 알파(Cronbach Alpha) 계산 방법을 나눔한다. R은 통계 분석언어이다. RStudio는 무료이며 GUI방식으로 편리하게 R 언어를 사용할 수 있도록 한다.








이 글은 간단한 포트포워드로 외부 접속 가능한 공개 웹서버 인터넷 서비스 및 DNS 설정 방법을 정리한다.
본인이 개발한 프로그램을 인터넷으로 서비스하고 싶을 때가 있다. 이때, 인터넷 제공자로부터 비싼 고정IP를 설치하거나, 임시로 할당된 IP주소를 매번 입력하는 방식은 그리 편해 보이지 않는다. 이 경우, 집에 있는 공유기의 포트포워드(port forward) 를 이용해 공개 웹서버를 만들 수 있다.
공유기의 포트포워드 기능을 이용하면, 집에서도 서버를 쉽게 운영할 수 있다.
IP 정보 얻기
우선 아래 링크로 내 공개 IP를 얻는다.

그리고, 내부 네크워크 내 서버로 사용할 컴퓨터의 IP주소를 ifconfig 로 얻는다. 화면에서 inet 이 IP 주소이다.

공유기 포트 포워드 설정
이제 이 두개를 연결해줘서, 외부 공개 IP > 내부 IP 서버로 접속될 수 있게 포트 포워드를 설정한다. 이 과정은 공유기 종류별로 약간 다르나 메뉴는 거의 동일하다.
우선 아래와 같이 공유기 설정 주소를 입력하여, 로긴한 후, 포트 포워드 설정 메뉴를 선택한다.



접속하는 윈도우에서 방화벽 설정을 다음과 같이 진행한다.
제어판 > window 방화벽 > 고급설정 > 인바운드 규칙 클릭 > 새규칙 > 포트 클릭 > tcp, 특정 로컬 포트 예) 80, 5000 > 연결 허용 체크 > 도메인, 개인 공용 모두 체크 > 마침
우분투 서버에서는 다음과 같이 서버 포트를 허용해 준다.
sudo ufw allow 5000
서버 실행
다음과 같이 개발한 서버를 실행한다(웹서버 개발 방법 참고).

도메인 획득
이제 외부 공개 IP로 접속하면 서버가 외부에서도 연결될 것이다. 이제, 도메인을 설정해 특정 주소로 서버가 외부에 공개되도록 한다. 무료 DNS 서버를 이용해 이를 설정한다. 여기에서는 freenom을 이용한다. 이외에, 홈페이지 만들 때 Netlify, Streamlit share, Start Bootstrap 등도 유용하니 참고 바란다.
다음과 같이, 원하는 DNS 이름을 입력하고, 로그인 한 후, DNS를 구입하고, 해당 DNS에 앞의 서버 외부 공용 IP를 설정한다.

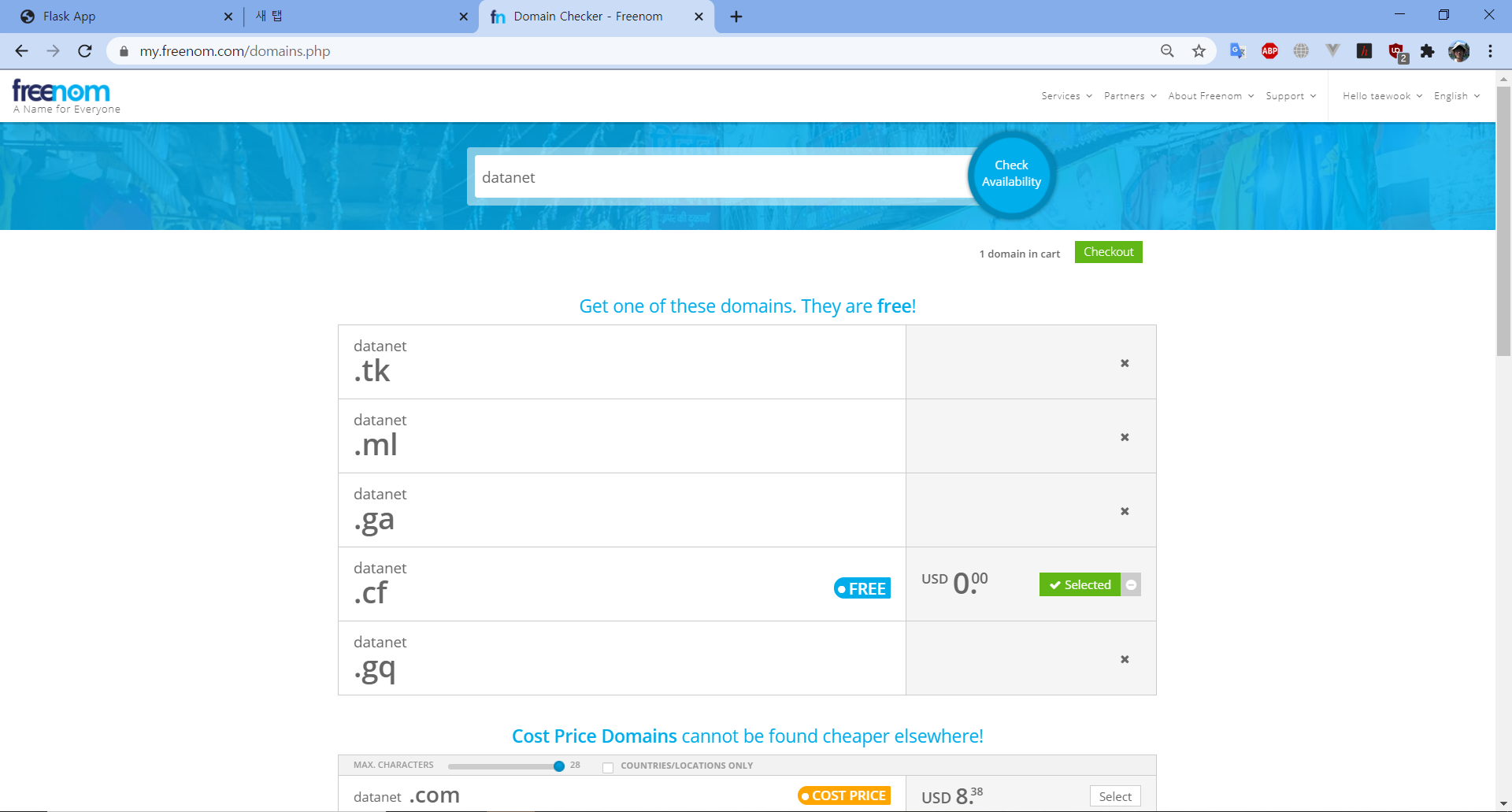




이제 DNS와 설정한 서버 공개 외부 IP가 네트워크를 통해 반영될 수 있도록 5~10분 정도 기다린다.
외부 DNS IP로 서버 접속
외부 DNS IP로 서버 접속해 본다. 결과는 다음과 같다. 테스트를 위해, 집 밖에서 노트북, 스마트폰을 이용해 촬영한 이미지를 개발한 웹서버로 업로드해 보았다.


외부에서 업로드한 이미지는 다음과 같이 서버에 잘 저장된다.

마무리
공유기의 포트포워드 기능을 이용하면, 집에서도 서버를 쉽게 운영할 수 있다.
부록: 웹 서비스 배포 및 무료 호스팅
레퍼런스
이 글은 LIO SAM 기반 SLAM 기술 소개 및 활용에 대해 간략히 설명한다.

개요
LIO SAM은 LOAM개발자가 기존 방법을 개선해 개발한 슬램 기술이다.
LIO-SAM은 라이더 관성 주행 거리 측정법을 개발해, 루프 폐쇄를 포함한 다양한 상대 및 절대 포인트 측정을 여러 소스에서 통합한다. 관성 측정 장치 (IMU) 통합에서 추정된 모션은 포인트 클라우드의 왜곡을 제거하고 라이더 주행 거리 측정 최적화를 위한 초기 추측 데이터를 생성한다. 라이더 주행 거리 측정 솔루션은 IMU의 편향을 추정하는 데 사용된다. 이 결과로 다음과 같이 기존 LOAM보다 좋은 결과를 얻을 수 있다.

시스템 아키텍처는 다음과 같다.

이 기술은 다음과 같이 IMU, LiDAR가 미리 준비되어 있어야 한다.
소스 빌드 및 실행
다음과 같이 실행해 소스코드를 빌드한다.
실행은 다음과 같다.
roslaunch lio_sam run.launch
미리 준비된 데이터로 스캔 데이터를 시뮬레이션할 수 있다.

마무리
LIO SAM은 LOAM과 유사한 방식(참고)으로 개발되었다. 특징점을 계산하기 위해, GSTAM 패키지를 사용한다. 성능에 대한 설명은 여기를 참고한다.
레퍼런스
이 글은 ROS 좌표 프레임 개념 및 사용 방법에 대해 간략히 정리한다.
머리말
로봇 시스템은 다양한 로컬 좌표계 프레임으로 구성된다. 다음 그림과 같이 로봇의 각 파트가 움직일 때 하위 부분은 같이 움직어야 한다. 이들의 위치나 방향을 각각 계산하면 매우 복잡할 것이다. 그러므로, 상위 파트가 움직이면, 해당되는 좌표 그래프부터 부속된 하위 노드까지 좌표변환행렬을 계산 및 전파한다. 이를 scene graph라 한다.

씬 그래프는 컴퓨터 그래픽에서 고전적인 솔류션이다.
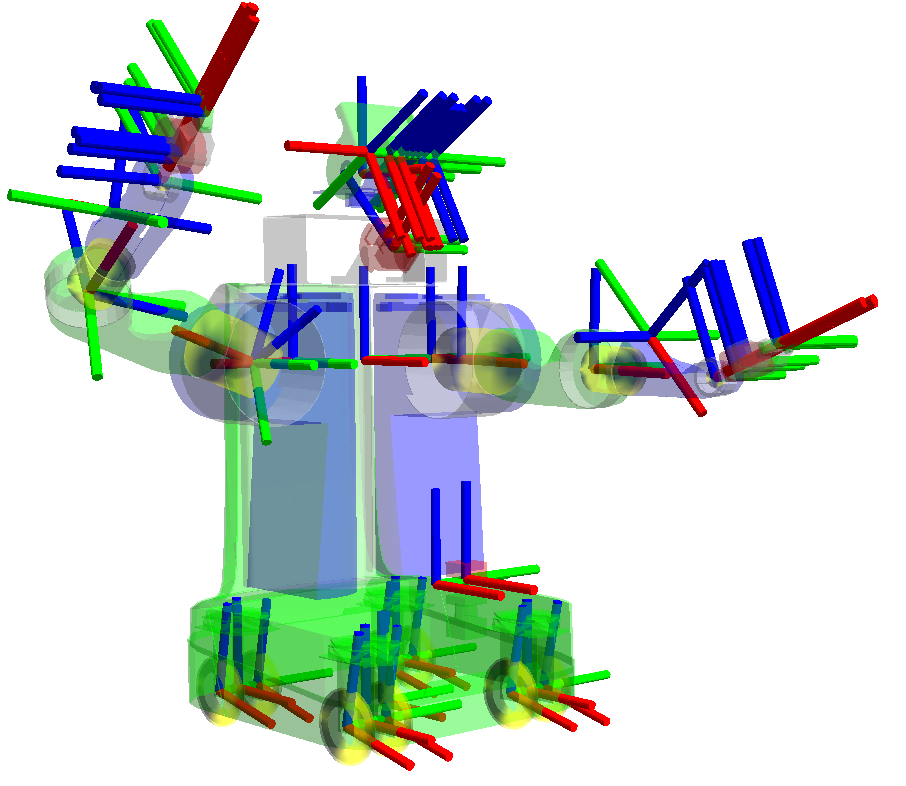



각 프레임요소는 다음과 같은 연결관계를 가진다. 참고로, 드론과 같은 로봇은 pressure_altitude 를 추가해 고도 좌표 프레임을 삽입할 수 있다.
다음 프레임 그래프는 earth에 기반한 다중 로봇의 좌표계 그래프를 보여준다.

참고로, 로봇이 원거리 이동하는 경우, map 을 전환해야 할 수도 있다.
이 글은 Flask, mysql, 파이썬 기반 Open API 웹서버 개발 방법을 간략히 정리한다. 이 방법은 Open API를 쉽게 만드는 기술 중 하나로, 파이썬 기반 오픈 API 개발 시 가장 많이 사용되는 구조이다.
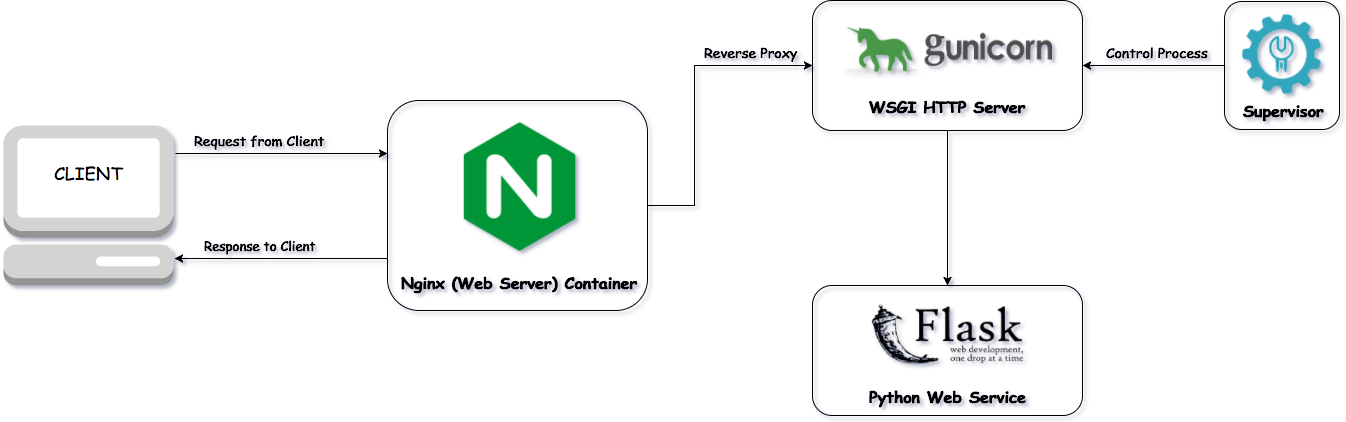

환경 준비
다음과 같이 관련 환경을 설정한다.
sudo apt-get install mysql-server
sudo ufw allow mysql
sudo systemctl start mysql
sudo systemctl enable mysql
이제 마이SQL을 실행한다.
sudo /usr/bin/mysql -u root -p



암호정책은 약하게 우선 설정한다. 그리고 계정을 만든다.
select plugin_name, plugin_status from information_schema.plugins where plugin_name like 'validate%';
install plugin validate_password soname 'validate_password.so';
select plugin_name, plugin_status from information_schema.plugins where plugin_name like 'validate%';
SET GLOBAL validate_password_policy=LOW;

create table study(no int, subject varchar(100), memo varchar(50), writedate date, count int, primary key(no));
MySQL workbench 실행 시 접근 권한 에러날 경우 Software center에서 Permissions을 다음과 같이 변경해 주어야 한다.




간단한 MySQL 기반 Open API 서버 개발
다음과 같이 실행해 플라스크와 MySQL 테이블을 바로 API로 만드는 flask-mysql을 설치한다.
다음과 같이 my_app.py 파일을 코딩한다.
from flask import Flask, jsonify
from flaskext.mysql import MySQL
app = Flask(__name__)
mysql = MySQL()
# MySQL configurations
app.config['MYSQL_DATABASE_USER'] = 'my_user'
app.config['MYSQL_DATABASE_PASSWORD'] = 'my_password'
app.config['MYSQL_DATABASE_DB'] = 'my_database'
app.config['MYSQL_DATABASE_HOST'] = 'localhost'
mysql.init_app(app)
@app.route('/')
def get():
cur = mysql.connect().cursor()
cur.execute('''select * from study.score''')
r = [dict((cur.description[i][0], value)
for i, value in enumerate(row)) for row in cur.fetchall()]
return jsonify({'myCollection' : r})
if __name__ == '__main__':
app.run()
다음과 같이 실행한다.
pip install cryptography
python my_app.py
그리고, http://127.0.0.1:5000 링크를 브라우저로 열어 본다.


간단한 Open API 서버 개발



이미지 업로드 서버 개발
같은 방식으로 이미지 업로드 서버를 개발해 본다. image.py 코딩한다.
다음은 이미지 업로드 서버 실행 결과이다.



다중 이미지 업로드 서버 개발
이제 여러 장의 이미지들을 업로드하고 보는 서버를 개발해 보자. 다음 multi_images.py를 코딩한다(참고. Dustin D'Avignon 관련 글)
templates 폴더 아래에 index.html파일을 코딩한다. dropzone 객체를 이용해, 드래그&드롭 이미지 업로드 컴포넌트를 만들고 있다.
<!DOCTYPE html>
<html>
<head>
<title>Flask App</title>
{{ dropzone.load() }}
{{ dropzone.style('border: 2px dashed #0087F7; margin: 10%; min-height: 400px;') }}
</head>
<body>
<h1>Hello from Flask!</h1>
{{ dropzone.create(action_view='index') }}
</body>
</html>
그리고, results.html파일을 코딩한다. 세션의 file_url을 src로 하여, 이미지를 렌더링하게 되어있다.
<h1>Hello Results Page!</h1>
<a href="{{ url_for('index') }}">Back</a><p>
<ul>
{% for file_url in file_urls %}
<li><img style="height: 150px" src="{{ file_url }}"></li>
{% endfor %}
</ul>
서버를 실행한 결과는 다음과 같다.




잘 실행된다. 만약, 외부로 웹서버를 공개하고 싶다면, 다음 링크를 참고한다.
마무리
플라스크를 이용해 데이터 업로드, 프로그램 실행, 데이터 저장 및 API를 통한 데이터 획득 서버 개발 방법을 간단히 알아보았다. 앞의 예제를 따라하면 프론트, 미들, 엔드를 포함한 웹서버가 이렇게 쉽게 개발된다는 것에 깊은 인상을 느끼게 된다. 플라스크는 이런 전 과정을 매우 간단한 간단한 포트포워드로 외부 접속 가능한 공개 웹서버 인터넷 서비스 및 DNS 설정 방법문법과 기능으로 해결해 준다. 다양한 애드인을 이용해 이미지 등 다양한 파일을 처리할 수 있다. 구글에서도 Open API 서버로 플라스크를 이용할 만큼 성능과 안정성이 좋다.
플라스크 개발에 공헌한 개발자는 오스트리아 오픈소스 프로그래머인 아민 로너커이다. 그는 1989년 생으로 소프트웨어 개발이란 유명한 블로그를 운영하고 있다. 2005년 우분투 그룹에서 오픈소스 개발자로 경력을 시작하였고, WSGI 에 관심을 가졌다. 그는 2004년 부터 one-file microframework을 주장하였고, 플라스크 개발을 시작했다.

플라스크에 대한 상세 문서는 여기(한글 문서)를 참고하길 바란다.
참고: 가상환경 설정
플라스크 개발 시 다음과 같이 가상환경을 설정하는 것이 좋다.
python3 -m venv env
source env/bin/activate
pip install -e .
참고: [Errno 98] Address already in use
레퍼런스



 https://daddynkidsmakers.blogspot.com/2020/09/dns.html
https://daddynkidsmakers.blogspot.com/2020/09/dns.html{kind=link}