이 글은 파이썬 기반 PDF 보고서 파일을 생성하거나, 원하는 텍스트를 추출하여 데이터 마이닝하는 오픈소스 도구를 간략히 정리한다.
오피스에서 작업을 하다보면, PDF파일을 많이 다루게된다. 이 경우, 노가다가 필요한 수작업이 많은데, 파이썬 라이브러리를 사용하면, 이러한 오피스 작업을 자동화할 수 있다.
이 글은 fpdf, pyPDF2 라이브러리를 사용해, 보고서 형식을 PDF로 출력하거나, 반대로 PDF의 정보를 추출하는 방법을 구현해 본다.

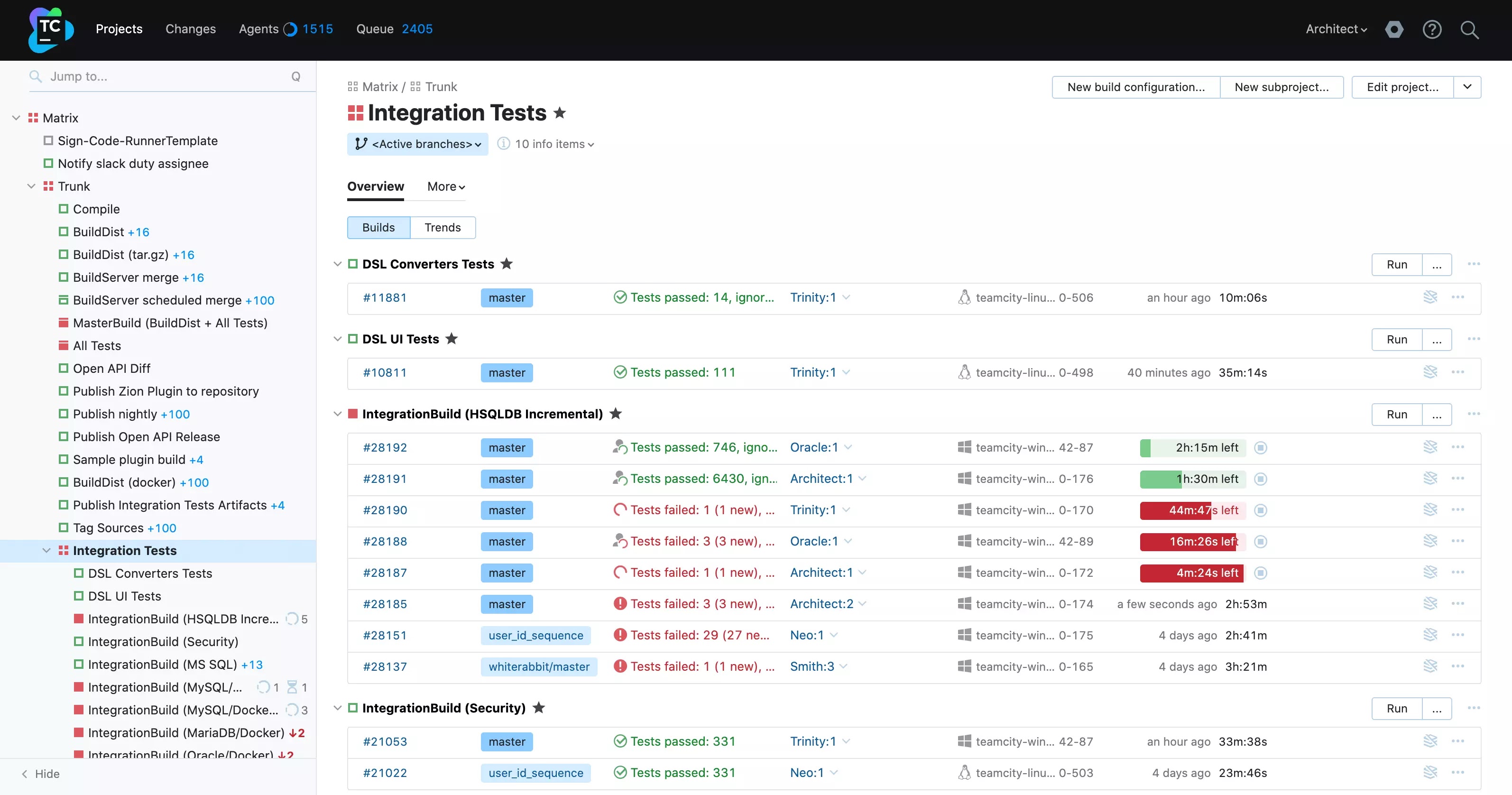
생성된 PDF 보고서 예시
라이브러리 소개
fpdf (github)는 PDF 문서를 생성하는 라이브러리로 최초 PHP로 개발되었다가 파이썬으로 포팅된 도구이다. 다음 기능을 지원한다.
- PDF 쓰기 지원
- PNT, GIF, JPG 지원
- html2pdf 템플릿 지원
PyPDF2는 PDF파일 병합, 절단, 변환 등을 지원한다. 주요 기능은 다음과 같다.
- PDF 데이터 처리
- PDF 암호화
- PDF 데이터 추출
라이브러리 설치
다음 명령을 터미널에 입력해 필요한 라이브러리를 설치한다.
pip install fpdf, pyPDF2, lorem, pandas, seaborn, re
사용방법
파이썬 파일을 하나 만든 후, 다음을 코딩해 넣는다.
from fpdf import FPDF
import lorem
import pandas as pd
# 표 출력을 위해, 데이터 프레임 생성
df = pd.DataFrame(
{'feature 1' : ['cat 1', 'cat 2', 'cat 3', 'cat 4'],
'feature 2' : [400, 300, 200, 100]
})
# 차트 그림 생성
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots(1,1, figsize = (6, 4))
sns.barplot(data = df, x = 'feature 1', y = 'feature 2')
plt.title("Chart")
plt.savefig('./example_chart.png',
transparent=False,
facecolor='white',
bbox_inches="tight")
# PDF 클래스 생성
ch = 8
class PDF(FPDF):
def __init__(self):
super().__init__()
def header(self):
self.set_font('Arial', '', 12)
self.cell(0, 8, 'Header', 0, 1, 'C')
def footer(self):
self.set_y(-15)
self.set_font('Arial', '', 12)
self.cell(0, 8, f'Page {self.page_no()}', 0, 0, 'C')
# 셀을 생성하고, 각 셀에 보고서 내용 설정
pdf = PDF()
pdf.add_page()
pdf.set_font('Arial', 'B', 24)
pdf.cell(w=0, h=20, txt="Title", ln=1)
pdf.set_font('Arial', '', 16)
pdf.cell(w=30, h=ch, txt="Date: ", ln=0)
pdf.cell(w=30, h=ch, txt="01/01/2022", ln=1)
pdf.cell(w=30, h=ch, txt="Author: ", ln=0)
pdf.cell(w=30, h=ch, txt="Max Mustermann", ln=1)
pdf.ln(ch)
pdf.multi_cell(w=0, h=5, txt=lorem.paragraph())
pdf.image('./example_chart.png', x = 10, y = None, w = 100, h = 0, type = 'PNG', link = '') # 차트 이미지 입력
pdf.ln(ch)
pdf.multi_cell(w=0, h=5, txt=lorem.paragraph())
pdf.ln(ch)
# 표 헤더 및 내용 설정
pdf.set_font('Arial', 'B', 16)
pdf.cell(w=40, h=ch, txt='Feature 1', border=1, ln=0, align='C')
pdf.cell(w=40, h=ch, txt='Feature 2', border=1, ln=1, align='C')
# Table contents
pdf.set_font('Arial', '', 16)
for i in range(len(df)):
pdf.cell(w=40, h=ch, txt=df['feature 1'].iloc[i], border=1, ln=0, align='C')
pdf.cell(w=40, h=ch, txt=df['feature 2'].iloc[i].astype(str), border=1, ln=1, align='C')
# PDF 저장
pdf.output("example.pdf")
그 결과는 다음과 같다.

PDF에서 텍스트 추출
다음 파이썬 코드를 입력한다.
import re, PyPDF2
def extract_abstract(pdf_fname = 'sample.pdf'): # sample.pdf 파일을 준비한다. 이 경우는 논문의 ABSTRACT 부분을 추출하는 것으로 코딩되었다.
pdf_file = open(pdf_fname, 'rb')
pdf_reader = PyPDF2.PdfReader(pdf_file)
first_page = pdf_reader.pages[0]
text = first_page.extract_text()
abstract_start = text.find('Abstract') # abstract keyword 검색
if abstract_start == -1:
abstract_start = text.find('ABSTRACT')
abstract = ''
if abstract_start == -1:
return abstract
abstract_start += len('Abstract')
introduction_start = text.find('Introduction') # introduction keyword 검색
if introduction_start == -1:
introduction_start = text.find('Background')
if introduction_start == -1:
return abstract
introduction_start -= 4
abstract_end = introduction_start if introduction_start != -1 else len(text)
abstract = text[abstract_start:abstract_end]
# remove new line characters
abstract = abstract.replace('\n', ' ')
# remove digits and special characters
# abstract = re.sub(r'[^a-zA-Z0-9().,% ]', '', abstract)
print(abstract)
extract_abstract()
실행하면 다음과 같이 PDF로부터 추출된 ABSTRACT 텍스트 결과를 확인할 수 있다.

레퍼런스
- FPDF installation and tutorial
- Workplace automation
- How to Create a PDF Report for Your Data Analysis in Python
- 5 Python open-source tools to extract text and tabular data from PDF Files