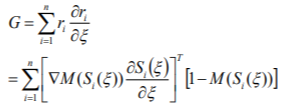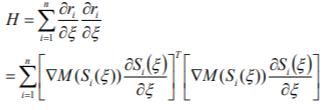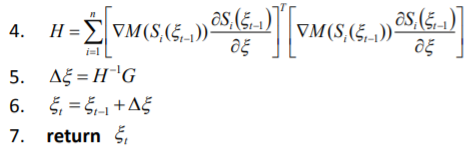이 글은 저렴한
RpLiDAR A1 과 엔비디아 젯슨 나노를 이용해 이동형 스캐너를 개발하는 방법을 간단히 정리한다. RpLiDAR는 저렴한 2D 스캐너로
인터넷 에서 99달러에 구매할 수 있다.
개발환경은 우분투 18.04와
ROS (
설치 )이다. 개발환경은 나노 개발자 설치 설명 사이트를 따라 다운로드하고 설치하면 된다(아래 링크 참고).
참고로, 라즈베리파이나 아두이노를 이용한 방법은 아래 링크를 참고바란다.
RpLiDAR based on RaspberryPi and arduino RpLiDAR 스캔 원리
이 장치는 레이저 송수신기가 내장되어 있고, 이를 회전해 거리를 측정한다.
좌표계는 왼쪽손 좌표 기준이다. 다음 그림과 같이 각도를 1도씩 회전하며 거리를 측정한다.
좀 더 상세한 설명은 다음 데이터 시트를 참고한다.
장치 연결
RpLiDAR를 엔비디아 나노의 USB포트와 연결한다.
그리고, 다음과 같이 연결된 라이다를 확인해 본다.
$ usb-devices
$ usb-devices | grep "CP2102"
다음과 같은 부분을 발견하면, 엔비디아 나노와 제대로 연결된 것이다.
Product=CP2102 USB to UART Bridge Controller
If#= 0 Alt= 0 #EPs= 2 Cls=ff(vend.) Sub=00 Prot=00 Driver=cp210x
RpLiDAR 설치
RpLiDAR SDK를 다음과 같이 다운로드하고 메이크한다.
$ git clone https://github.com/Slamtec/rplidar_sdk
$ cd rplidar_sdk/sdk
$ make
다음과 같이 ttyUSB 읽기 권한을 획득한다.
sudo chmod 666 /dev/ttyUSB0
혹은 다음과 같이 권한을 영구히 설정한다.
cd /etc/udev/rules.d/
sudo gedit 50-usb-serial.rules
KERNEL=="ttyUSB0", GROUP="ktw", MODE="0666"
다음 명령을 실행하면 권한 획득 된 것을 알 수 있다.
ls -l /dev | grep ttyUSB
이제 빌드된 rp_lidar/output/Linux/Release 폴더 밑의 RpLidar 예제를 다음과 같이 실행해 본다.
$ sudo ./ultra_simple
다음 화면은 실행된 스캔 데이터 결과이다.
ROS node 소스를 다음과 같이 다운로드하여 빌드한다(ROS 설치되어 있다고 가정함. ROS는 이전 블로그 참고요).
cd ~/catkin_ws/src
git clone https://github.com/Slamtec/rplidar_ros
cd ..
catkin_make
빌드가 정상적으로 진행되면, 터미널에서 roscore를 실행한 후, 다음과 같이 roslaunch를 실행한다.
$ roslaunch rplidar_ros view_rplidar.launch
그럼, 다음과 같이 시각화된 스캔 데이터를 확인할 수 있다.
VIDEO
실행화면
rviz를 별도로 실행하려면 다음과 같이 실행하면 된다.
roslaunch rplidar_ros rplidar.launch
RpLiDAR 소스 분석
ROS 패키지는 client, node 두개 파일이 포함되어 있다. rplidar.launch 는 이를 실행하기 위한 설정이다. 설정은 node 이름, serial port 이름, 데이터 전송 속도, 프레임 id 및 각도 보정 설정이 포함된다.
<launch>
node는 다음 순서로 실행된다.
1. scan, tcp ip, port, serial bps 등 설정 코드를 실행한다.
2. RPlidarDriver 를 생성한다.
3. 드라이버를 시리얼 포트와 연결한다.
4. 드라이버 정보를 얻는다.
5. stop_motor, start_motor 서비스를 등록한다.
6. 드라이버 스캔 시작 함수를 호출한다.
drv->startScan();
7. 스캔 데이터를 얻는다.
publish_scan(&scan_pub, angle_compensate_nodes, angle_compensate_nodes_count,
실제 퍼블리쉬되는 데이터는 rplidar_response_measurement_node_hq_t nodes[360*8] 에 담긴다. 구조체 의미는 다음과 같다.
typedef struct rplidar_response_measurement_node_hq_t {
센서에서 얻은 데이터는 ROS /LaserScan 메시지로 변환되어 토픽 메시지로 발행된다. 이 메시지 형식은 헤더, 최대/최소 각도, 각도 증가값, 스캔 시간 각격, 측정 값 최대/최소, 거리 값 데이터(ranges), 강도값으로 구성된다. 이 메시지는 ROS 표준 토픽이므로, RViz 등 ROS 패키지에서 호환되어 사용된다.
std_msgs/Header header
실제 각도에 대한 거리는 다음과 같이 계산할 수 있다.
count = scan_time / time_increment
for i in range(count):
angle = angle_min + angle_increment * i
distance = ranges[i]
client는 단순히 /scan 토픽을 구독하는 역할을 한다. 구독된 토픽 값은 다음과 같이 각도와 거리값으로 출력한다.
void scanCallback(const sensor_msgs::LaserScan::ConstPtr& scan)
이를 통해, 점군 생성 함수를 다음과 같이 정의할 수 있다.
void scanToPoint(float radian, float dist, float& x, float& y)
void scanCallback(const sensor_msgs::LaserScan::ConstPtr& scan)
...
float x, y;
다음과 같이 실행해 보면, 변환된 점 좌표가 출력된다.
rosrun rplidar_ros rplidarNodeClient
로그를 보면, 각 각도가 1도씩 증가되어 해당 거리가 표시되는 것을 알 수 있다. 그 뒤에 x, y값이 출력된다.
SLAM 처리
ROS SLAM 기본 패키지를 이용해 SLAM 처리를 한다. 다음과 같은 순서로
Hector SLAM 을 실행해 본다. 참고로 Hector의미는 Heterogeneous Cooperating Team Of Robots 약자이다. 이 팀은 TU Darmstadt 컴퓨터 사이언스 및 기계 공학 간 연구자 협업으로 만들어졌다(
참고 ).
cd ~/catkin_ws/src
git clone https://github.com/NickL77/RPLidar_Hector_SLAM
cd ..
catkin_make
아나콘다 설치 환경에서는 소스 빌드 시 몇몇 에러가 발생할 수 있는 데, 다음과 같이 처리한다.
sudo apt install qt4-default
sudo apt install ros-melodic-cv-bridge
sudo gedit /opt/ros/indigo/share/cv_bridge/cmake/cv_bridgeConfig.cmake
set(cv_bridge_FOUND_CATKIN_PROJECT TRUE)
이제 다음과 같이 실행해 본다.
sudo chmod 666 /dev/ttyUSB0
roslaunch rplidar_ros rplidar.launch
roslaunch hector_slam_launch tutorial.launch
실행은 다음과 같이 엔비디아 나노에 연결된 라이다를 이동하며 스캔해 보았다.
결과는 다음과 같다.
Hector SLAM은 스캔된 점군 자체로 실시간 정합을 수행하는 SLAM이므로, 동일한 특징점을 발견하기 어려운 조건(스캔된 점군의 급격한 회전 및 이동), 특징점의 변화가 없는 구역(일직선 통로 등)에서 오류가 발생한다. 이를 보완하는 SLAM기법은 여러가지가 있다. 예를 들어, gmapping 은 odometry(주행계) 센서 값을 이용해 이를 보정한다. odometry센서는 다양하나 IMU가 지원되는 센서이면 가능하다(예. MPU6050). SLAM 알고리즘 성능 비교는 다음 링크를 참고한다.
LIDAR에 대한 좀 더 상세한 내용은 다음 링크를 참고한다.
VIDEO
VIDEO
ROS Hector SLAM 분석
ROS에서 hector slam은 hector_mapping 노드에서 실행된다(
참고 ). 이 노드는 레이저 스캔 프레임의 2차원 위치를 추정한다. 각 프레임과 옵션은 올바르게 설정되어 있어야 한다.
좌표계 프레임
다음 그림은 로봇이 거친 표면을 이동할 때, 로봇 플렛폼의 좌표계와 roll, pitch 모션 등을 보여준다. 좌표 프레임에 대한 상세 개념은 아래를 참고한다.
좌표 프레임은 odom을 사용하지 않는다면, 다음과 같이 설정된다.
<param name="pub_map_odom_transform" value="true"/>
<param name="map_frame" value="map" />
<param name="base_frame" value="base_frame" />
<param name="odom_frame" value="base_frame" />
이 경우, 퍼블리쉬 설정을 다음과 같이 처리한다.
<param name="pub_map_odom_transform" value="false"/>
노드는 다음과 같이 구성된다.
hector_mapping 노드는 LiDAR 기반 SLAM이며, odometry를 사용하지 않는다. ROS API는 옵션을 제공한다. 다음은 관련 토픽이다(
참고 ).
scan: 레이저 스캔 데이터 syscommand: 시스템 명령. 예를 들어, 'reset'이면, 로봇 초기 위치등이 리셋됨 map_metadata: 토픽으로 부터 맵 메타데이터 획득 map: 토픽으로 부터 맵 데이터 획득 slam_out_pose: 로봇 위치 추정 poseupdate: 가우시안 기반 로봇 위치 추정 파라메터는 다음과 같다.
base_frame: 로봇 기본 프레임. 레이저 스캔 데이터의 localization, transformation에 사용됨 map_frame: 맵 프레임 odom_frame: odom 프레임 map_resolution: map 해상도. 기본은 0.025(m). map_size: 맵 그리드 크기. 기본은 1024. map_update_distance_thresh: default 0.4. map_multi_res_levels: default 3 HECTOR SLAM 구조 역설계를 위해 github 해당 소스코드를 다운받아 분석해 본다.
roslaunch hector_slam_launch tutorial.launch 를 실행하면, launchh 에 있는 설정을 실행한다.
<launch>
<arg name="geotiff_map_file_path" default="$(find hector_geotiff)/maps"/>
<param name="/use_sim_time" value="true"/>
<node pkg="rviz" type="rviz" name="rviz"
args="-d $(find hector_slam_launch)/rviz_cfg/mapping_demo.rviz"/>
<include file="$(find hector_mapping)/launch/mapping_default.launch"/>
<include file="$(find hector_geotiff)/launch/geotiff_mapper.launch">
<arg name="trajectory_source_frame_name" value="scanmatcher_frame"/>
<arg name="map_file_path" value="$(arg geotiff_map_file_path)"/>
</include>
</launch>
여기서 hector_mapping 실제 동작은 해당 폴더의 launch에 있는 mapping_default.launch 를 통해 실행된다.
<launch>
<arg name="tf_map_scanmatch_transform_frame_name" default="scanmatcher_frame"/>
<arg name="base_frame" default="base_footprint"/>
<arg name="odom_frame" default="nav"/>
<arg name="pub_map_odom_transform" default="true"/>
<arg name="scan_subscriber_queue_size" default="5"/>
<arg name="scan_topic" default="scan"/>
<arg name="map_size" default="2048"/>
<node pkg="hector_mapping" type="hector_mapping" name="hector_mapping" output="screen">
<!-- Frame names -->
<param name="map_frame" value="map" />
<param name="base_frame" value="$(arg base_frame)" />
<param name="odom_frame" value="$(arg odom_frame)" />
<!-- Tf use -->
<param name="use_tf_scan_transformation" value="true"/>
<param name="use_tf_pose_start_estimate" value="false"/>
<param name="pub_map_odom_transform" value="$(arg pub_map_odom_transform)"/>
<!-- Map size / start point -->
<param name="map_resolution" value="0.050"/>
<param name="map_size" value="$(arg map_size)"/>
<param name="map_start_x" value="0.5"/>
<param name="map_start_y" value="0.5" />
<param name="map_multi_res_levels" value="2" />
<!-- Map update parameters -->
<param name="update_factor_free" value="0.4"/>
<param name="update_factor_occupied" value="0.9" />
<param name="map_update_distance_thresh" value="0.4"/>
<param name="map_update_angle_thresh" value="0.06" />
<param name="laser_z_min_value" value = "-1.0" />
<param name="laser_z_max_value" value = "1.0" />
<!-- Advertising config -->
<param name="advertise_map_service" value="true"/>
<param name="scan_subscriber_queue_size" value="$(arg scan_subscriber_queue_size)"/>
<param name="scan_topic" value="$(arg scan_topic)"/>
<param name="tf_map_scanmatch_transform_frame_name" value="$(arg tf_map_scanmatch_transform_frame_name)" />
</node>
</launch>
전체 패키지는 13개로 구성되어 있다. 여기서 핵심은 hector_mapping 모듈이며, hector_slam, hector_slam_launch는 launch 패키지이다. hector_imi 패키지는 IMU센서 데이터를 사용해 odometry 값을 보정한다.
hector_mapping 모듈이 SLAM알고리즘을 구현하고 있다. 모듈 구조가 복잡하므로, UML 클래스 다이어그램으로 분석해 본다.
hector_mapping의 핵심 모듈은 HectorMappingRos이다. 이 모듈 코드 실행 순서는 다음과 같다.
slamProcessor = new hectorslam::HectorSlamProcessor(static_cast<float>(p_map_resolution_), p_map_size_, p_map_size_, Eigen::Vector2f(p_map_start_x_, p_map_start_y_), p_map_multi_res_levels_, hectorDrawings, debugInfoProvider);
slamProcessor->setUpdateFactorFree(p_update_factor_free_);
slamProcessor->setUpdateFactorOccupied(p_update_factor_occupied_);
slamProcessor->setMapUpdateMinDistDiff(p_map_update_distance_threshold_);
slamProcessor->setMapUpdateMinAngleDiff(p_map_update_angle_threshold_);
for (int i = 0; i < mapLevels; ++i)
{
mapPubContainer.push_back(MapPublisherContainer());
slamProcessor->addMapMutex(i, new HectorMapMutex());
...
}
scanSubscriber_ = node_.subscribe(p_scan_topic_, p_scan_subscriber_queue_size_, &HectorMappingRos::scanCallback, this);
sysMsgSubscriber_ = node_.subscribe(p_sys_msg_topic_, 2, &HectorMappingRos::sysMsgCallback, this);
poseUpdatePublisher_ = node_.advertise<geometry_msgs::PoseWithCovarianceStamped>(p_pose_update_topic_, 1, false);
posePublisher_ = node_.advertise<geometry_msgs::PoseStamped>("slam_out_pose", 1, false);
scan_point_cloud_publisher_ = node_.advertise<sensor_msgs::PointCloud>("slam_cloud",1,false);
}
void HectorMappingRos::scanCallback(const sensor_msgs::LaserScan& scan)
{
if (!p_use_tf_scan_transformation_) // TF 사용시
{
if (rosLaserScanToDataContainer(scan, laserScanContainer,slamProcessor->getScaleToMap())) // 점군 변환 후
{
slamProcessor->update(laserScanContainer,slamProcessor->getLastScanMatchPose()); // SLAM 처리
}
}
else // TF 사용 안하면
{
projector_.projectLaser(scan, laser_point_cloud_,30.0);
Eigen::Vector3f startEstimate(Eigen::Vector3f::Zero());
if(rosPointCloudToDataContainer(laser_point_cloud_, laserTransform, laserScanContainer, slamProcessor->getScaleToMap())) // 점군 변환 후
{
stamped_pose.getBasis().getEulerYPR(yaw, pitch, roll); // 스탬프 위치에서 YPR 획득
startEstimate = Eigen::Vector3f(stamped_pose.getOrigin().getX(),stamped_pose.getOrigin().getY(), yaw);
slamProcessor->update(laserScanContainer, startEstimate, true); // SLAM 처리
}
poseUpdatePublisher_.publish(poseInfoContainer_.getPoseWithCovarianceStamped());
posePublisher_.publish(poseInfoContainer_.getPoseStamped());
}
if(p_pub_odometry_)
{
tmp.header = poseInfoContainer_.getPoseWithCovarianceStamped().header;
tmp.child_frame_id = p_base_frame_;
odometryPublisher_.publish(tmp);
}
if (p_pub_map_odom_transform_)
{
tf::StampedTransform odom_to_base;
tf_.waitForTransform(p_odom_frame_, p_base_frame_, scan.header.stamp, ros::Duration(0.5));
tf_.lookupTransform(p_odom_frame_, p_base_frame_, scan.header.stamp, odom_to_base);
}
if (p_pub_map_scanmatch_transform_){
tfB_->sendTransform( tf::StampedTransform(poseInfoContainer_.getTfTransform(), scan.header.stamp, p_map_frame_, p_tf_map_scanmatch_transform_frame_name_));
}
}
void HectorMappingRos::publishMap(MapPublisherContainer& mapPublisher, const hectorslam::GridMap& gridMap, ros::Time timestamp, MapLockerInterface* mapMutex) // 맵 퍼블리쉬
{
mapPublisher.mapPublisher_.publish(map_.map);
}
bool HectorMappingRos::rosLaserScanToDataContainer(const sensor_msgs::LaserScan& scan, hectorslam::DataContainer& dataContainer, float scaleToMap) // 스캔 데이터를 점군으로 변환
{
for (size_t i = 0; i < size; ++i)
{
float dist = scan.ranges[i];
if ( (dist > scan.range_min) && (dist < maxRangeForContainer))
{
dist *= scaleToMap;
dataContainer.add(Eigen::Vector2f(cos(angle) * dist, sin(angle) * dist)); // x, y 점 좌표 변환
}
angle += scan.angle_increment;
}
}
HectorMappingRos은 HectorSlamProcessor의 update()를 호출한다. 이 모듈 코드 실행 순서는 다음과 같다.
class HectorSlamProcessor
{
void update(const DataContainer& dataContainer, const Eigen::Vector3f& poseHintWorld, bool map_without_matching = false)
{
Eigen::Vector3f newPoseEstimateWorld; // 위치 추정 벡터
if (!map_without_matching) // 매칭 없으면
{
newPoseEstimateWorld = (mapRep->matchData(poseHintWorld, dataContainer, lastScanMatchCov)); // 매칭 처리
}else{
newPoseEstimateWorld = poseHintWorld;
}
lastScanMatchPose = newPoseEstimateWorld;
if(util::poseDifferenceLargerThan(newPoseEstimateWorld, lastMapUpdatePose, paramMinDistanceDiffForMapUpdate, paramMinAngleDiffForMapUpdate) || map_without_matching)
{
mapRep->updateByScan(dataContainer, newPoseEstimateWorld); // 맵 데이터 업데이트
mapRep->onMapUpdated();
lastMapUpdatePose = newPoseEstimateWorld;
}
}
}
HectorSlamProcessor에서 호출된 matchData에서 점군을 매칭할 공분산을 리턴한다. 공분산은 해세 H 행렬이다.
{
Eigen::Vector3f matchData(const Eigen::Vector3f& beginEstimateWorld, ConcreteOccGridMapUtil& gridMapUtil, const DataContainer& dataContainer, Eigen::Matrix3f& covMatrix, int maxIterations)
{
if (dataContainer.getSize() != 0) {
Eigen::Vector3f beginEstimateMap(gridMapUtil.getMapCoordsPose(beginEstimateWorld));
Eigen::Vector3f estimate(beginEstimateMap);
estimateTransformationLogLh(estimate, gridMapUtil, dataContainer); // 점군에서 위치 추정
int numIter = maxIterations;
for (int i = 0; i < numIter; ++i) {
estimateTransformationLogLh(estimate, gridMapUtil, dataContainer);
}
estimate[2] = util::normalize_angle(estimate[2]);
covMatrix = Eigen::Matrix3f::Zero();
covMatrix = H;
return gridMapUtil.getWorldCoordsPose(estimate);
}
return beginEstimateWorld;
}
bool estimateTransformationLogLh(Eigen::Vector3f& estimate, ConcreteOccGridMapUtil& gridMapUtil, const DataContainer& dataPoints)
{
gridMapUtil.getCompleteHessianDerivs(estimate, dataPoints, H, dTr); // 점군에서 위치 추정
if ((H(0, 0) != 0.0f) && (H(1, 1) != 0.0f)) {
Eigen::Vector3f searchDir (H.inverse() * dTr);
if (searchDir[2] > 0.2f) {
searchDir[2] = 0.2f;
std::cout << "SearchDir angle change too large\n";
} else if (searchDir[2] < -0.2f) {
searchDir[2] = -0.2f;
std::cout << "SearchDir angle change too large\n";
}
updateEstimatedPose(estimate, searchDir);
return true;
}
return false;
}
}
헤세 행렬은 getCompleteHessianDerivs 에서 계산된다.
{
void getCompleteHessianDerivs(const Eigen::Vector3f& pose, const DataContainer& dataPoints, Eigen::Matrix3f& H, Eigen::Vector3f& dTr) // 헤세
Hessian 행렬을 계산
{
int size = dataPoints.getSize();
Eigen::Affine2f transform(getTransformForState(pose));
float sinRot = sin(pose[2]);
float cosRot = cos(pose[2]);
H = Eigen::Matrix3f::Zero();
dTr = Eigen::Vector3f::Zero();
for (int i = 0; i < size; ++i) {
const Eigen::Vector2f& currPoint (dataPoints.getVecEntry(i));
Eigen::Vector3f transformedPointData(interpMapValueWithDerivatives(transform * currPoint));
float funVal = 1.0f - transformedPointData[0];
dTr[0] += transformedPointData[1] * funVal;
dTr[1] += transformedPointData[2] * funVal;
float rotDeriv = ((-sinRot * currPoint.x() - cosRot * currPoint.y()) * transformedPointData[1] + (cosRot * currPoint.x() - sinRot * currPoint.y()) * transformedPointData[2]); // 회전 편차
dTr[2] += rotDeriv * funVal;
H(0, 0) += util::sqr(transformedPointData[1]); // H 행렬
H(1, 1) += util::sqr(transformedPointData[2]);
H(2, 2) += util::sqr(rotDeriv);
H(0, 1) += transformedPointData[1] * transformedPointData[2];
H(0, 2) += transformedPointData[1] * rotDeriv;
H(1, 2) += transformedPointData[2] * rotDeriv;
}
H(1, 0) = H(0, 1);
H(2, 0) = H(0, 2);
H(2, 1) = H(1, 2);
}
}
앞서 hector slam 코드를 보면, 헤세 행렬 H을 구해 스캔 점군에 필요한 데이터를 얻는 것을 알 수 있다(
참고 논문 ). 헤세 행렬을 구하기 위해서는 편미분 함수를 정의해야 한다. SLAM에서 지도 상에 주어진 점을 Pm이라 하면, 점유값 함수 M(Pm)을 정의하여 다음 수식을 세울 수 있다.
이중 선형 방법을 사용해 점유값을 근사화하면, P00, P10, P01, P11을 사용한 선형 보간은 다음과 같이 나타낼 수 있다.
그러므로, M 편미분 함수는 다음과 같이 근사화된다.
스캔 매칭은 문제는 지금까지 얻은 지도와 스캔된 점들 간 정렬을 위한 최적화 계산이 된다. 가우스-뉴턴 수치해석을 통해, 스캔 포인트 간에 정렬을 수행한다. 시작 추정 위치 ξ = (𝑝𝑥, 𝑝𝑦, 𝜓) T에서 스캔 매칭 목적은 M 함수를 최소화하는 것이된다.
여기서, 𝑆𝑖 (𝜉) 은 로봇 프레임에 수신된 스캔 데이터를 월드 좌표계로 변환하는 함수이다.
가우스 뉴턴 알고리즘은 비선형 최소 제곱 문제를 해결할 때 사용되고, 목표함수 𝑟𝑖는 다음과 같이 정의된다.
재귀 알고리즘으로 표현하면 다음과 같다.
로봇 위치의 움직임 Δ𝜉 이 매우 작다고 가정할 때, 가우스 뉴턴 알고리즘의 기울기 벡터 G는 다음과 같다.
이제, 2차 편미분을 무시하여, H 행렬을 정의한다.
𝑆𝑖(𝜉) 미분은 다음 행렬로 표시할 수 있다.
이제 최소값을 위한 Δ𝜉 를 계산한다.
헤토르 슬램의 비선형 근사 알고리즘을 정리하면 다음과 같다. 다만, 긴 복도 환경에서는 문제가 있다.
결국, 앞서 코드와 매치해 각 알고리즘 단계는 다음과 같이 수행되는 것을 알수 있다.
1. 헥터 스캔 매칭 함수(이전 점군, 현재 점군x, 현재 점군y, 점유 함수M)
void getCompleteHessianDerivs(const Eigen::Vector3f& pose, const DataContainer& dataPoints, Eigen::Matrix3f& H, Eigen::Vector3f& dTr)
2. 수신 데이터를 월드 좌표계로 계산
Eigen::Vector3f transformedPointData(interpMapValueWithDerivatives(transform * currPoint));
3. 최적해를 구하기 위한 구배함수 G 계산
float funVal = 1.0f - transformedPointData[0];
dTr[0] += transformedPointData[1] * funVal;
dTr[1] += transformedPointData[2] * funVal;
float rotDeriv = ((-sinRot * currPoint.x() - cosRot * currPoint.y()) * transformedPointData[1] + (cosRot * currPoint.x() - sinRot * currPoint.y()) * transformedPointData[2]);
dTr[2] += rotDeriv * funVal;
4. H 행렬 계산
H(0, 0) += util::sqr(transformedPointData[1]);
H(1, 1) += util::sqr(transformedPointData[2]);
H(2, 2) += util::sqr(rotDeriv);
H(0, 1) += transformedPointData[1] * transformedPointData[2];
H(0, 2) += transformedPointData[1] * rotDeriv;
H(1, 2) += transformedPointData[2] * rotDeriv;
}
5. 에러 편차 계산
Eigen::Vector3f searchDir (H.inverse() * dTr);
6. 편차 갱신
7. 편차 리턴
참고로, 헤세 행렬은 편미분 함수로 f(x1, x2, x3, ..., xn) 에 대한 행렬을 구한것이다.
H는 이차미분함수(second derivative)이므로 대칭행렬이 된다. 그러므로, 고유벡터로 분해 가능하다. H는 함수 곡률을 나타내므로, 특징점(critical point) 종류를 판별하는데 사용할 수 있다. 어떤 함수의 일차 미분이 0이 되는 점은 함수의 극점이 된다. 어떤 함수의 특징점에서 계산한 Hessian 행렬의 모든 고유값이 음수이면 극대, 음 및 양의 고유값을 가지면 말안장 모양의 변곡점(saddle point)을 의미한다.
헤세 함수는 이미지 처리시 I(x, y)에서 픽셀 밝기에 대한 함수로 긴 모양의 패턴(모세혈관 등)을 검출하는 데 사용되기도 한다. 이 함수는 이미지 매칭에 사용되는 SURF알고리즘에도 사용된다.
스캔 테스트
작업된 2차원 라이다로 다음과 같이 간단히 패키징한 후, 영상과 같이 테스트해보았다.
VIDEO
VIDEO
스캔 거리는 약 5미터로 확인되었으며, 유리 같은 반사재질에는 데이터를 획득할 수 없었다. 스캔 거리가 멀수록 오차나 노이즈가 조금씩 심해진다. 당연하지만, 센서 수평을 유지하지 않으면 제대로 된 평면 포인트 클라우드를 얻을 수 없다. 가능한 가벼운 장비를 활용하였음에도 들고 다니기에는 손목이 아팠다.
부록: IMU 처리
나노에 IMU 센서를 연결하기 위해
MPU-925 0를 사용한다.
다음과 같이 결선한다.
IMU GPIO
VIN 1
GND 6
SCL 28
SDA 27
다음과 같이 관련 프로그램 패키지를 설치한다.
sudo apt-get install libi2c-dev i2c-tools
sudo usermod -a -G i2c $USER
git clone https://github.com/jetsonhacks/RTIMULib
다음과 같이 주소를 확인한다.
sudo i2cdetect -y -r 1
다음과 같이 빌드한다.
cd RPTIMULib/Linux
mkdir build
cd build
cmake ..
make
다음과 같이 빌드된 데모를 실행해 본다. 자동으로 IMU를 선택하면, 해당 센서가 인식될 것이다.
..RTIMULib/Linux/build/RTIMULibDemo$ ./RTIMULibDemo
VIDEO
부록: OLED LCD SSD1306 설치
SSD1306 OLED LCD를 나노에 설치해 본다. 아래 패키지 및 소스를 다운로드, 설치 한다.
sudo apt-get install libjpeg-dev zlib1g-dev
cd Adafruit_Python_SSD1306
sudo python setup.py install
LCD를 준비하고, GPIO와 연결한다.
LCD GPIO
VIN 5V
GND GND
SCL 5
SDA 3
I2C 주소를 확인한다.
sudo i2cdetect -y -r 1
여기서 다운로드한 파이썬 프로그램을 실행해 본다. 다음과 같이 출력되면 성공한 것이다.
레퍼런스