이 글은 생성AI 모델 학습과 같이 현재도 다양한 곳에서 필수적으로 사용되는 강화학습 딥러닝 기술의 기본 개념, 이론적 배경, 내부 작동 메커니즘을 확인한다. 그리고, 케라스 및 파이토치 기반 강화학습 라이브러리를 이용한 인공지능 게임 학습, 주식 자동 거래 개발 방법을 나눔한다.
참고로, 이글에서 실습한 내용은 다음 github에서 다운로드 가능하다.
머리말
강화학습은 바둑, 로봇 제어와 같은 제한된 환경에서 최대 효과를 얻는 응용에 주로 많이 사용된다. 강화학습 코딩 전에 사전에 강화학습 개념을 미리 이해하고 있어야 제대로 된 개발이 가능하다. 대부분 강화학습에 대해 설명한 인터넷글은 핵심 개념에 대해 다루기 보다는 실행 코드만 나열한 경우가 많아, 실행 메커니즘을 이해하기 어렵다. 메커니즘을 이해할 수 없으면, 응용 기술을 개발하기 어렵다. 그러므로, 이 글은 강화학습 메커니즘과 개념 발전의 역사를 먼저 살펴본다.
강화학습 개발 시 이 글은 OpenAI가 개발한 Gym을 사용해 기본적인 강화학습 실행 방법을 확인한다. 참고로, github 등에 공유된 강화학습 예시는 대부분 게임, 로보틱스 분야에 치중되어 있는 것을 확인할 수 있다. 여기서는 CartPole 예제로 기본적인 라이브러리 사용법을 확인하고, 게임 이외에 주식 트레이딩, 가상화폐, ESG 탄소 트레이딩, 에너지 활용 설비 운영과 같은 실용적인 문제를 풀기 위한 방법을 알아본다.

강화학습 개념(Google)
강화학습 동작 메커니즘
강화학습 개발 전에 동작 메커니즘을 간략히 정리하고 지나가자.
1. 강화학습 에이전트, 환경, 정책, 보상
강화학습의 목적은 주어진 환경(environment) 내에서 에이전트(agent)가 액션(action)을 취할 때, 보상 정책(policy)에 따라 관련된 변수 상태 s와 보상이 수정된다. 이를 반복하여, 총보상 r을 최대화하는 방식으로 모델을 학습한다. 정책은 보상 방식을 알고리즘화한 것이다. 다음 그림은 이를 보여준다. 이는 우리가 게임을 하며, 학습하는 것과 매우 유사한 방식이다.

강화학습 에이전트, 환경, 액션, 보상 개념(towardsdatascience)
강화학습 설계자는 처음부터 시간에 따른 보상 개념을 고려했다. 모든 시간 경과에 따른 보상치를 동시에 계산하는 것은 무리가 있으므로, 이를 해결하기 위해, DQN(Deep Q-Network)과 같은 알고리즘이 개발되었다.
모든 강화학습 라이브러리는 이런 개념을 일반화한 클래스, 함수를 제공한다. 다음은 강화학습 라이브러리를 사용한 일반적인 개발 코드 패턴을 보여준다.
train_data, test_data = load_dataset() # 학습, 테스트용 데이터셋 로딩
class custom_env(gym): # 환경 정책 클래스 정의
def __init__(self, data):
# 환경 변수 초기화
def reset():
# 학습 초기 상태로 리셋
def step(action):
# 학습에 필요한 관찰 데이터 변수 획득
# 액션을 취하면, 그때 관찰 데이터, 보상값을 리턴함
env = custom_env(train_data) # 학습환경 생성. 관찰 데이터에 따른 보상을 계산함
model = AgentModel(env) # 에이전트 학습 모델 정의. 보상을 극대화하도록 설계
model.learn() # 보상이 극대화되도록 학습
model.save('trained_model') # 학습된 파일 저장
# 학습된 강화학습 모델 기반 시뮬레이션 및 성능 비교
env = custom_env(test_data) # 테스트환경 생성
observed_state = env.reset()
while not done:
action = model.predict(observed_state) # 테스트 관찰 데이터에 따른 극대화된 보상 액션
observed_state, reward, done, info = env.step(action)
# al1_reward = env.step(al1_action) # 다른 알고리즘에 의한 액션 보상값과 성능비교
# human_reward = env.step(human_action) # 인간의 액션 보상값과 성능비교
이 코드에서 gym은 강화학습의 보상정책이 포함된 알고리즘을 캡슐화한 클래스이다. 많은 강화학습 라이브러리는 이런 환경을 다양하게 준비해 제공한다. 일반적으로 라이브러리에서 제공되는 강화학습 환경에는 게임, 로봇제어 등이며, 모두 규칙에 따른 보상을 계산하는 로직을 포함한다. 강화학습을 지원하는 유명 오픈소스 개발도구들은 다음과 같다.
- OpenAI Gym: 강화학습 기반 알고리즘, 게임, 로봇 시뮬레이션 예제 제공. (예. 트레이딩, CartPole)
- Stable Baselines3: 파이토치 기반 DQN, PPO, A2C, SAC 알고리즘 제공
- tf-agents: 텐서플로우 기반 강화학습 알고리즘 제공
- Keras-RL: 간단한 모듈식 API 제공 (예. 주식 거래)
- RLlib: 강화학습 알고리즘 및 분산 학습지원
- Dopamine: 구글에서 개발 제공. 다양한 알고리즘 유틸리티 구현
- Unity ML-Agents: 유니티 환경에서 RL 에이전트 학습 제공

이외, 다음과 같이 강화학습을 이용한 예제들이 있다.
- 아마존 딥레이서(DeepRacer): 무인자율주행 시뮬레이션
- MuJoCo: 물리 시뮬레이션
- OpenAI Gym 주식 트레이딩 봇 gym-anytrading: 주식 거래 강화학습
- RL-GAN-Net: 누락된 점군을 이용한 형상 생성
- SUMO: 교통 시뮬레이션
- Hindsight Experience: 로봇 암 시뮬레이션

2. 딥러닝 기반 Q-Learning 알고리즘(DQN) 동작 방식
강화학습 시 기본이 되는 알고리즘은 딥러닝 기반 Q-Learning 알고리즘(DQN)이다. DQN은 Q-Learning을 비용 함수로 사용해 딥러닝 학습을 하는 방식이다. DQN은 2015년 DeepMind에서 개발되어, 알파고 등에 사용되었다.
Q-Learning은 Q-function의 개념을 기반으로 한다. 정책 π, Q(S, a)의 Q-function(state-action value function)은 먼저 행동 α를 취한 후, 정책 π를 따름으로서, 상태 s로 부터 얻는 보상의 할인된 합계를 계산한다. 최적의 Q-function Q*(s, a)은 관찰값 s로 부터 시작해, 행동α를 취하고, 이후 최적 보상을 받는 정책에 따름으로서 최대 이익을 얻는다. 이를 위해, 벨만 방정식(Bellman equation)을 사용한다.
Q*(s, a) = E[r + γ max α' Q*(s', a')]
이때,
s = state
a = action
r = 보상
Q = reward 함수
Q* = 최적 reward
γ = 현재 action을 취했을 때, 다음 보상의 할인율. 현재 보상 비율을 조정하는 역할
s' = 다음 상태
a' = 다음 액션
E = 기대되는 보상
Q-Learning의 기본 개념은 벨만 방정식(Bellman optimality)을 사용한다. Q-Learning은 벨만 방정식을 사용해 총보상값을 과거 보상값을 고려해, 재귀 반복 업데이트하며 최적해를 찾아간다(참고 - DQN 논문. Q-Learning 동작 메커니즘은 아래 3번 글을 참고). DQN 논문에서 실험한 결과, 이를 통해, 특정 상태에서 시작한 Qi는 최적 총보상인 Q*로 수렴한다는 것을 확인했다.
전체 Q-Learning 알고리즘은 다음과 같다.

DQN 알고리즘(DeepMind, 2015)
대부분의 문제에서 Q-function을 s, a 각 조합의 표로 나타내는 것은 비현실적이다. 대신, 매개변수를 가진 신경망같은 함수 근사기를 사용해, 훈련할 수 있다면, 효과적으로 이 문제를 풀 수 있다. 즉, Q(s, a; θ) ≈ Q*(s, a) 가 가능하다. 각 보상 학습 단계에서 다음 수식의 손실을 최소화하도록 설계한다.
Loss함수 = Li(θi) = E * s, a, r, s' ~ ρ(.) [(yi - Q(s, a; θi))²]
이때,
yi = r + γ max α' Q(s', a'; θi-1)]
여기서, ρ는 사전 수집된 s, a, r, s'에 대한 분포를 나타낸다. 이전 학습인 θi-1의 Q변수값들은 다음 학습을 위해 고정되어 업데이트되지 않는다. 그러므로, 이 값들은 메모리에 보관(스냅샷)해 두어야 한다. 이 스냅샷 사본을 대상 네트워크라 한다.
이렇게 Loss 함수를 설계하면, loss 가 이전 보상과 차이가 적은 쪽으로 수렴하도록 동작된다. 결국 보상 정책 a = max α Q(s, a, θ)에 대해 계산하게 된다. 그리고, 이때, 지역해에 빠지지 않도록 랜덤 액션 선택 확률값 ϵ를 도입해, 1 - ϵ 인 greedy action과 ϵ 확률로 행동을 선택하도록 ϵ-greedy 정책(알고리즘)을 적용한다.
DQN 비용함수의 수식 표현은 다음과 같다.
Deep Q Network cost function
DQN에서 전체 보상값을 계산하지 않고, 일부 스냅샷만으로 최적해를 구하기 위해서는, 확률적 경사하강법을 사용한다.
DQN을 통해 아타리(Atari) 게임을 강화학습으로 구현한 사례에서, 신경망 학습 가중치를 안정적으로 업데이트하기 위해, 경험 재현(Experience Replay) 기법이 적용되었다. 이는 각 학습 타임 단계(step)에서 재현 버퍼 메모리에 앞서 언급한 스냅샷 데이터를 추가한다. 이 버퍼는 원형 Queue 자료 구조를 가진다. 학습 시 배치 입력 데이터는 이 재현 버퍼에서 랜덤 샘플링된 데이터를 사용한다(미니 배치 학습 기법). 이를 통해, 안정적인 학습을 유도한다.
TF-Agents와 같은 라이브러리는 이와 같은 딥러닝 강화학습에 필요한 함수와 객체를 제공한다.
3. Q-Learning의 배경 개념인 마르코프 체인, 벨만 방정식 개발 역사
Q-Learning은 마르코프 체인(Markov chain, 1906년) 개념에서 발전된 것이다. 수학자 안드레이 마르코프는 현재 상태로만 미래를 예측하는 과정을 연쇄적으로 연결함으로써 최적해를 구할 수 있도록 마르코프 연쇄 기법을 개발했다. 그는 강화학습에서 환경과 정책이라 불리는 시스템, 상태에 따른 확률적 전환(transition) 개념(강화학습에서 확률적으로 보상이 높은 액션을 선택하는 행위로 사용됨)을 관련 논문에서 제안하였다. 마르코프 체인은 상태 변화의 단계가 이산적으로 계산될 수 있도록 하였고, 그 단계는 시간, 물리적 거리 등 측정가능한 것이 될 수 있도록 수식으로 일반화하였다.

처음 딥러닝을 사용하지 않았던 강화학습 기술은 에이전트가 최대 보상을 받는 방법은 이전 상태와 행동을 취한 현재상태의 보상만 관련된다고 가정하였다. 이를 통해, 게임의 전체 상태를 알지 않아도 된다고 가정한다. 그렇지 않으면, 무한대의 상태를 한정된 컴퓨터 메모리에서 계산할 수 있는 방법이 없다.
그러므로, 이런 가정에 잘 부합하는 것이 마르코프 체인이다. 마르코프 체인은 선택의 직전 상태와 이로 인한 결과만 고려한다(과거 데이터는 손실된다). 이를 이용해서, 다음 그림과 같은 문제를 해결할 수 있다.

다만, 좀 더 먼 과거와 많은 상태들을 고려해야 하는 문제는 탐색할 해와 계산량이 무한히 증가하는 차원의 저주가 발생한다. 이를 해결하기 위해, 리처드 벨만이 개발한 벨만(Bellman) 방정식이 사용되었다. 이 방정식은 재귀적 특성을 가지고 있어, 과거 경험을 누적하도록 정의되어 있다. 벨만 방정식 개발 목적이 동적 프로그래밍 문제 해결(예. 물류 최적 이동)에 필요한 최적해 탐색까지 이동시간, 비용 최소화를 고려해 설계되었으므로, 벨만 방정식은 누적 보상이 제일 큰 상태를 선택할 수 있다.



이 벨만 방정식을 이용한 강화학습 방법이 Q-Learning이다.
Q-Learning 강화학습 알고리즘은 상태, 액션의 집합으로 Q-Table을 메모리에 생성한다. 탐색해 공간에서 에이전트 시작과 목표를 알고 있다면, 보상값을 계산하는 Q(s, a)함수를 정의할 수 있고, 다음 그림과 같이 표에 Q값을 계산할 수 있다.

Q Table 예시
이 그림에서는 에이전트(자동차)가 목적지를 도달하는 액션을 선택할 때 Q(s, a)함수값이 1.0으로 제일 크게 하는 것을 알 수 있다(그림 표에서 4행 3열). Q함수값을 미리 계산할 수 있다면, 에이전트는 보상이 큰 쪽으로 따라가면, 자동적으로 목표에 도달할 수 있다. Q-Table이 액션이 탐색하는 경로를 보여준다는 것을 알 수 있다.
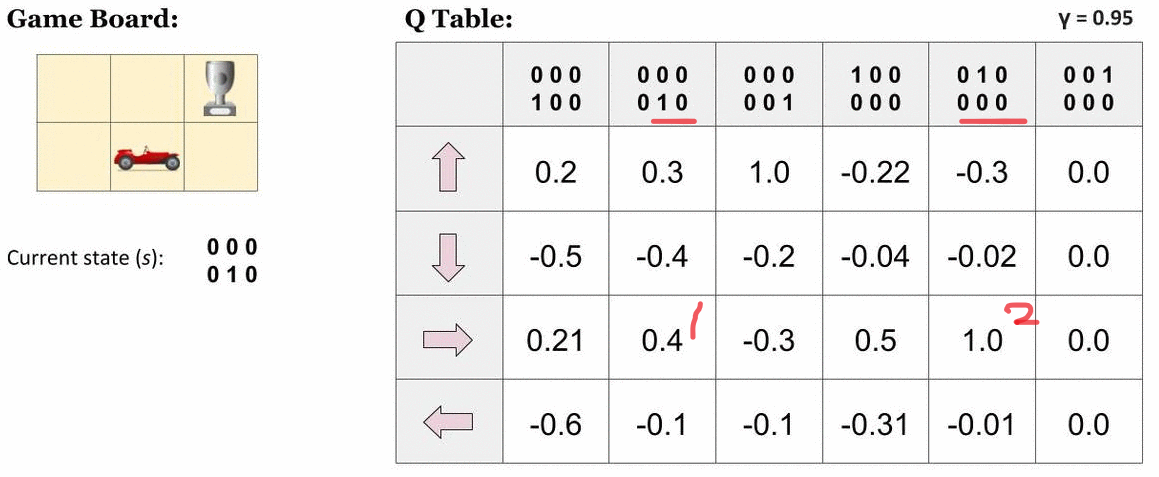
이를 바탕으로 한, Q-Learning 알고리즘은 여러 에피소드 실험을 반복해, 정책에 따라 생성된 데이터를 입력받아, 최적 해를 탐색한다. 지역해에 빠지지 않도록 e-greedy 방법을 이용해 임의의 탐색경로를 선택한다. 초기 Q 함수값은 램덤값으로 균등하게 분포되어 있다고 가정한다. 각 상태가 단계마다 업데이트될 때 보상값도 갱신될 수 있다. 보상값은 해탐색 공간에서 현재지점과 목표지점 간 거리 등을 사용할 수 있다.
Q-Learning은 그 자체만으로도 효과적인 학습이 가능하여, 자율주행, 게임, 로봇제어, 재고관리 등에 사용되고 있다. 다만, 이는 다음 같은 한계가 있다.
- 전체 탐색에 따른 보상을 미리 알고 있을 때 한해 탐색이 가능하다.
- 선택할 수 있는 상태가 무한대일 경우, Q Table이 메모리 계산 범위를 넘어간다(차원의 저주).
현실의 문제에서는 선택할 수 있는 상태가 무한히 많은 경우(예. 주식 트레이딩 등)가 일반적이다. 이 문제를 해결하고자, 에이전트가 처한 상태 s의 특징(예. 게임에서 플레이어와 먹이 혹은 몬스터와의 거리)을 계산하고, 이를 통해, 상태 s를 일반화하여, 각 특징의 가중치를 곱하는 Approximate Q-Learning을 사용할 수 있다. 하지만, 이 또한 차원의 저주에서는 자유롭지 않아, DQN 알고리즘이 개발된 것이다.

4. 강화학습 알고리즘의 분류
앞서 설명한 DQN은 강화학습 알고리즘 중 하나이다. 강화학습 알고리즘은 정책 최적화를 통해, 액션의 보상을 크게 만드는 것이 목적이다. 강화학습 알고리즘은 크게 Policy Optimization과 Q-Learning 계열로 나뉜다.
- Poicy optimization: 이 방법은 policy π의 parameter θ를 이용해, πθ(a|s) 함수를 정의하고, θ를 학습시킨다. 이를 위해, 비용함수 J(πθ)의 θ에 대한 기술기를 계산한다. 이를 위해서는 gradient ascent를 통해 ∇J(πθ)를 계산해야 한다. 이 알고리즘 계열은 A2C(Advantage Actor Critic), A3C, PPO 등이 있다.
- Q-learning: 앞서 언급한 최적해 Q*(s,a)를 구하기 위해, 근사해 Qθ(s,a)를 구한다. 이를 위해, 벨만 방정식을 사용한다. 이 방식은 최적화 과정에서 정책 파라메터인 θ를 직접 사용하지 않고, 관찰시점의 샘플데이터를 학습용으로 사용한다. 그러므로, off-policy라 불린다. 이 계열 알고리즘은 DQN, C51등이 있다.
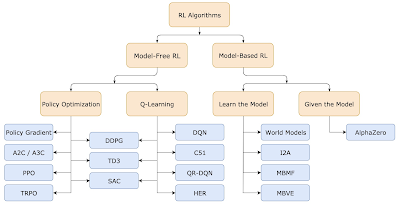
RL 알고리즘 계열
좀 더 상세한 강화학습의 기본개념은 아래 글을 참고한다.
- RL 및 Deep Q 네트워크 소개 | TensorFlow Agents
- Playing Atari with Deep Reinforcement Learning, DeepMind Technologies
- Markov chain
- Qrash Course: Reinforcement Learning 101 & Deep Q Networks in 10 Minutes | by Shaked Zychlinski | Towards Data Science
- Q-Learning (Q-Table) - Deep Learning Bible - 5. Reinforcement Learning
- Q-Learning (velog.io, tistory.com, approximate)
강화학습 기반 CartPole 기본 예제 테스트해보기
1. Keras-rl2 기반 CartPole 강화학습
강화학습 동작방식을 확인하기 위해 카트 위에 서 있는 막대를 시뮬레이션해 강화학습하는 예제를 실행해 보기로 한다. 이 기본예제를 통해 강화학습 방법을 좀 더 직관적으로 이해할 수 있다.
이를 위해 구글에서 개발된 keras-rl2 라이브러리를 사용한다. 현재 최신 버전 강화학습 라이브러리 활용 예제는 다음 장을 참고하라. 우선, virtualenv로 가상환경을 만든 후, 이와 관련된 패키지를 설치한다.
pip install gym pygame tensorflow-gpu keras-rl2
참고로, 현재 이 예제와 관련된 많은 코드는 keras-rl2 라이브러리 기반으로 개발되어 있다. 이 라이브러리 개발은 2021년부터 중단되었다(참고. dopamine). 아울러, 해당 예제를 실행해 보면, 최신 버전에서, fit() shape 불일치, display 라이브러리 불일치 등 수많은 에러가 발생한다. 그러므로, 다음과 같이 0.1.1버전을 설치한다.
pip install tf-agents==0.1.1
강화 학습의 기본 예제 테스트를 위해, gym라이브러리에서 미리 만들어 놓은 CartPole이란 막대기로 균형잡기 학습 환경을 준비해 본다. 이 예제는 조인트로 카트에 부착된 마찰없는 트랙을 따라 움직이는 막대기의 균형을 잡는 문제이다.

이 환경의 관측치(Observation) 상태는 4개의 튜플을 가진다. 관측 값은 카트의 위치 및 속도, 막대의 각도 및 각속도를 나타내는 4D 벡터이다. 이 값은 딥러닝 기반 강화학습 시 입력 데이터로 사용될 것이다.
Observation = {Cart Position, Cart Velocity, Pole Angle, Pole Velopcity At Tip}
모든 관측치에는 0.05사이의 균일 랜던값이 할당된다. 이 문제에서는 평균 보상이 특정 값 이상일때 문제가 해결된 것으로 판단한다.
에이전트는 두 가지 행동 중 하나를 취하여 시스템을 제어할 수 한다. 카트를 오른쪽 (+1) 또는 왼쪽 (-1)으로 움직인다. 막대가 똑바로 유지되는 모든 타임 스탭은 보상을 제공한다. 일부 각도 제한을 넘어가거나, 움직이는 레일 밖을 벗어나면 막대는 쓰러진다(참고). 에이전트 목표는 보상 합이 최대가 되는 정책을 학습하는 것이다.
다음 코드를 이용해 간단한 강화학습모델로 테스트를 수행한다.
import random
import gym
env = gym.make('CartPole-v1', render_mode='human')
episodes = 10
for episodes in range(1, episodes+1):
state = env.reset()
done = False
score = 0
while not done:
action = random.choice([0, 1])
n_state, reward, done, flag, info = env.step(action)
score += reward
env.render()
print('Episode:{} Score:{}'.format(episodes, score))
env.close()
실행 결과는 다음과 같다.

2. CartPole 딥러닝 강화학습 모델 개발
앞의 강화학습 환경의 입력, 출력, 보상을 이용해, 딥러닝 학습 모델을 만들고, 학습해 본다. 강화학습을 사용하지 않으면, 상태 x 액션 차원의 Q 테이블을 정의해야 한다. 이는 메모리에서 계산 범위를 넘어간다. 그러므로, DQN 기반 강화학습 기법을 이용한다.
다음 코드를 입력한다.
import random, gym, torch
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
env = gym.make('CartPole-v1') # , render_mode='human')
states = env.observation_space.shape[0]
actions = env.action_space.n
print('States {}, Actions {}'.format(states, actions))
model = Sequential()
model.add(Flatten(input_shape=(1, states)))
model.add(Dense(24, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(actions, activation='linear'))
agent = DQNAgent(
model=model,
memory=SequentialMemory(limit=50000, window_length=1),
policy=BoltzmannQPolicy(),
nb_actions=actions,
nb_steps_warmup=10,
target_model_update=1e-2
)
agent.compile(Adam(lr=1e-3), metrics=['mae'])
agent.fit(env, nb_steps=50000, visualize=False, verbose=1)
results = agent.test(env, nb_episodes=10, visualize=True)
print(np.mean(results.history['episode_reward']))
env.close()
실행하면, 다음과 같이 fit() 호출 후 학습을 시작한다.

학습된 최종 스코어 결과는 다음과 같다.


학습된 데이터는 다음과 같이 저장한 후 사용하면 된다.
model.save('trained_model_weights.h5') # agent.save_weights('trained_model_weights.h5')
env.close()
from keras.models import load_model
model = load_model('trained_model_weights.h5')
# predict
new_state = np.array([[0.1, 0.2, 0.3, 0.4]]) # Replace with your actual state
new_state = new_state.reshape(1,1,4)
q_values = model.predict(new_state)
predicted_action = np.argmax(q_values)
print(f'q_value = {q_values}, predict = {predicted_action}') # predicted_action==0 then left, not then right
실행 결과는 다음과 같다. 관찰 상태가 [0.1, 0.2, 0.3, 0.4] 이면, 액션이 1(우측 이동) 결과를 얻는 것을 확인할 수 있다.

3. DQN 강화학습 에이전트 코드 개발
앞서 사용한 딥러닝 개발 방식을 좀 더 깊게 살펴보기 위해, 케라스를 이용해 DQN 강화학습 시 사용된 에이전트를 직접 코딩해 본다.
이 예제에서는 딥러닝 모델을 어떻게 강화학습에 적용하는 지 확인할 수 있다. 앞서 수식에 있었던 대로, Q-Learning에서 얻은 상태 데이터들을 배치 학습으로 딥러닝 모델에 입력해 학습시키기 위해, 딥러닝 모델을 메인, 목표 네트워크 두개를 생성한다. 이 네트워크는 에피소드가 반복될 때마다, 가중치값을 학습된 모델과 동기화하여, 최적해를 탐색할 수 있도록 한다(참고). 실제 코드는 다음과 같다.
import json, random, time
from collections import deque
import gym
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import Adam
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
# 재생 메모리 버퍼 크기 설정. 큐 자료구조.
self.replay_buffer = deque(maxlen=40000)
# 하이퍼파리메터 설정
self.gamma = 0.99
self.epsilon = 1.
self.epsilon_min = 0.01
self.epsilon_decay = 0.98
self.learning_rate = 0.001
self.update_rate = 10
# 메인 및 목표 네트워크 생성
self.main_network = self.create_nn()
self.target_network = self.create_nn()
# 메인 네트워크 가중치와 동일하게 목표 네트워크 가중치 초기화
self.target_network.set_weights(self.main_network.get_weights())
def create_nn(self):
model = Sequential() # 3개 레이어를 가진 신경망 정의
model.add(Dense(32, activation='relu', input_dim=self.state_size))
model.add(Dense(32, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(learning_rate=self.learning_rate))
return model
def update_target_network(self):
# 메인 및 목표 네트워크 가중치 동일하게 설정
self.target_network.set_weights(self.main_network.get_weights())
def save_experience(self, state, action, reward, next_state, terminal):
# 재생 메모리에 경험 데이터를 추가함
self.replay_buffer.append((state, action, reward, next_state, terminal))
def sample_experience_batch(self, batch_size):
# 재생 메모리에서 경험 데이터들 샘플링. 배치크기만큼 획득
exp_batch = random.sample(self.replay_buffer, batch_size)
# s, a, r, s', 종료 정보에 대한 샘플링 데이터 획득
state_batch = np.array([batch[0] for batch in exp_batch]).reshape(batch_size, self.state_size)
action_batch = np.array([batch[1] for batch in exp_batch])
reward_batch = [batch[2] for batch in exp_batch]
next_state_batch = np.array([batch[3] for batch in exp_batch]).reshape(batch_size, self.state_size)
terminal_batch = [batch[4] for batch in exp_batch]
# 생성된 학습용 배치 데이터셋을 튜플 형태로 리턴
return state_batch, action_batch, reward_batch, next_state_batch, terminal_batch
def pick_epsilon_greedy_action(self, state):
# 확률 ε 로 액션 선택
if random.uniform(0, 1) < self.epsilon:
return np.random.randint(self.action_size)
# 메인 네트워크에서 주어진 s로 액션 선택
state = state.reshape((1, self.state_size)) # 배치 차원 형태로 텐서 차원 변환
q_values = self.main_network.predict(state, verbose=0)
return np.argmax(q_values[0]) # 최대 보상값을 얻는 액션 인덱스 획득
def train(self, batch_size):
# 경험 데이터에서 배치 데이터 샘플링
state_batch, action_batch, reward_batch, next_state_batch, terminal_batch = self.sample_experience_batch(batch_size)
# 목표(미래) 네트워크에서 최대 Q 보상값을 가진 액션 획득
next_q = self.target_network.predict(next_state_batch, verbose=0)
max_next_q = np.amax(next_q, axis=1)
# 메인(현재) 네트워크에서 보상값 획득
q_values = self.main_network.predict(state_batch, verbose=0)
# 현재 액션의 보상값은 미래 보상값의 감마(감쇠율)을 곱해 할당함
for i in range(batch_size):
q_values[i][action_batch[i]] = reward_batch[i] if terminal_batch[i] else reward_batch[i] + self.gamma * max_next_q[i]
# 과거 보상치와 현재 보상치의 loss가 없는 방향으로 메인(현재) 네트워크 학습시킴.
self.main_network.fit(state_batch, q_values, verbose=0)
if __name__ == '__main__':
# CartPole 환경 설정
env = gym.make("CartPole-v1")
state = env.reset()
# 환경의 상태, 액션 크기 설정
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# 에피소드, 에피소드 당 타임단계, 배치 크기 설정
num_episodes = 20 # 150
num_timesteps = 200 # 500
batch_size = 64
dqn_agent = DQNAgent(state_size, action_size)
time_step = 0 # 목표 네트워크 갱신에 사용되는 타임단계값 초기화
rewards, epsilon_values = list(), list() # 학습 후 출력위해 보상, 엠실론 값 리스트 초기화
for ep in range(num_episodes):
tot_reward = 0
state = env.reset()
print(f'\nTraining on EPISODE {ep+1} with epsilon {dqn_agent.epsilon}')
start = time.time()
for t in range(num_timesteps):
time_step += 1
# 타임스템마다 메인 네트워크 가중치로 목표 네트워크 갱신
if time_step % dqn_agent.update_rate == 0:
dqn_agent.update_target_network()
action = dqn_agent.pick_epsilon_greedy_action(state) # ε-greedy policy으로 미래 액션 선택
next_state, reward, terminal, _ = env.step(action) # 환경에서 액션 실행
dqn_agent.save_experience(state, action, reward, next_state, terminal) # 재생 메모리에 경험 저장
# 현재 상태를 다음 상태로 설정
state = next_state
tot_reward += reward
if terminal: # 강화학습 종료 조건 만족 시 루프 종료
print('Episode: ', ep+1, ',' ' terminated with Reward ', tot_reward)
break
# 재생 메모리가 가득차면, 딥러닝 모델 학습함
if len(dqn_agent.replay_buffer) > batch_size:
dqn_agent.train(batch_size)
rewards.append(tot_reward)
epsilon_values.append(dqn_agent.epsilon)
# 매 에피소드 종료 마다 엠실론 값을 감소시키로도록 갱신
if dqn_agent.epsilon > dqn_agent.epsilon_min:
dqn_agent.epsilon *= dqn_agent.epsilon_decay
# 수행 결과 출력
elapsed = time.time() - start
print(f'Time elapsed during EPISODE {ep+1}: {elapsed} seconds = {round(elapsed/60, 3)} minutes')
# 만약 최근 10개 에피소드 보상이 4990 보다 크면 종료
if sum(rewards[-10:]) > 4990:
print('Training stopped because agent has performed a perfect episode in the last 10 episodes')
break
# plot rewards
plt.plot(rewards)
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.title('Rewards of the training')
plt.show()
# plot epsilon values
plt.plot(epsilon_values)
plt.xlabel('Episode')
plt.ylabel('Epsilon')
plt.title('Epsilon values of the training')
plt.show()
# Save trained model. 앞의 예제와 같은 방식으로 저장된 학습 가중치를 로딩해 사용할 수 있도록 함
dqn_agent.main_network.save('trained_agent.h5')
print("Trained agent saved in 'trained_agent.h5'")
수행 결과는 보상은 다음과 같다. 에피소드를 충분히 크게 설정하면, 전체 보상이 최적해를 탐색하는 수준으로 증가, 수렴하는 것을 확인할 수 있다.


보상 및 엡실론 감쇠 결과(에피소드=20)
Stable Baseline3 기반 주식 트레이딩 강화학습 코딩
좀 더 실용적인 문제에 강화학습을 적용하기 위해, 주식 트레이딩 봇을 만들어 본다. 이 예제는 주식 데이터를 관찰해, 거래 시 높은 보상을 받을 수 있도록 모델을 강화학습한다.

강화학습을 위해 stable-baselines3 강화학습 라이브러리를 사용한다.

우선 다음과 같이 터미널에서 개발환경을 준비한다.
conda create -n venv_rl python=3.8
conda activate venv_rl
pip install mpi4py numpy pandas pytest psutil scipy seaborn tensorflow torch tqdm joblib ipython gym gymnasium[classic_control]
pip install stable_baselines3 shimmy yfinance
강화학습 전략은 널리 알려진 알고리즘인 PPO(Proximal Policy Optimization)을 사용한다. 참고로, PPO는 OpenAI가 공개한 것으로 기존 Policy Graident Learning의 에피소드 단위가 아닌 Step 단위로 학습데이터를 만들어 학습을 시키는 방식이다. 이 예제는 미리 정의된 PPO MLP모델을 사용한다. 만약 직접 설계한 딥러닝 아키텍처를 사용하고자 하면, stable-baseline3의 Custom Policy Network 정의하기 문서를 참고한다.
예제에서 거래 시 액션은 주식 매입, 판매, 보유 3가지이다. 보상은 순자산이 증가하는 방향으로 액션을 선택하는 단순한 방법을 사용한다. 학습 후, 테스트할 주식 데이터셋을 통해 시뮬레이션하여, 결과를 확인한다. 상세 코드는 다음과 같다.
import yfinance as yf
import numpy as np
import pandas as pd
# 강화 학습용 구글 주가 데이터 준비
ticker = "GOOG" # Google stock market symbol
data = yf.download(ticker, start="2018-01-01", end="2024-12-31") # Download the historical price data
print(data.head()) # Display the first few rows of the data
data = data.dropna() # 누락값이나 NaN 값을 제거
# 데이터 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_normalized = scaler.fit_transform(data)
data = pd.DataFrame(data_normalized, columns=data.columns)
# 학습용, 테스트용 데이터 분할
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
test_data = data[train_size:]
# 강화 학습 환경 준비
from stable_baselines3 import PPO
import gym
class TradingEnvironment(gym.Env):
def __init__(self, data):
self.data = data
self.action_space = gym.spaces.Discrete(3) # 액션은 주식 구입, 판매, 보유 3가지
self.observation_space = gym.spaces.Box(low=0, high=1, shape=(len(data.columns),)) # 샘플링공간 정의
def reset(self):
self.current_step = 0
self.account_balance = 100000 # 초기 주식 계좌 보유액. Initial account balance
self.shares_held = 0
self.net_worth = self.account_balance
self.max_net_worth = self.account_balance
return self._next_observation()
def _next_observation(self):
return self.data.iloc[self.current_step].values
def step(self, action):
self._take_action(action)
self.current_step += 1
if self.current_step > len(self.data) - 1:
self.current_step = 0
return self._next_observation(), self._get_reward(), self.net_worth, {}
def _take_action(self, action):
if action == 0: # 주식 구매
self.shares_held += self.account_balance / self.data.iloc[self.current_step].values[0] # 보유할 주식수
self.account_balance -= self.account_balance # 잔고 모두 주식 구매에 사용
elif action == 1: # 주식 판매
self.account_balance += self.shares_held * self.data.iloc[self.current_step].values[0] # 판매할 주식수
self.shares_held -= self.shares_held # 판매되고 남은 주식
self.net_worth = self.account_balance + self.shares_held * self.data.iloc[self.current_step].values[0] # 현가치
if self.net_worth > self.max_net_worth:
self.max_net_worth = self.net_worth
def _get_reward(self):
return self.net_worth - self.account_balance # 보상은 현가치와 잔고의 차
# 강화학습
env = TradingEnvironment(train_data) # Create the trading environment
model = PPO("MlpPolicy", env, verbose=1) # Initialize the PPO model
model.learn(total_timesteps=50000) # Train the model
# 학습된 모델로 주식 거래 시뮬레이션
def simulate_trading_strategy(model, data):
env = TradingEnvironment(data)
obs = env.reset()
net_worths = []
for i in range(len(data)):
action, _ = model.predict(obs)
obs, _, _, _ = env.step(action)
net_worths.append(env.net_worth)
return net_worths
import matplotlib.pyplot as plt
net_worth = simulate_trading_strategy(model, test_data)
# Plot the net worth over time
plt.plot(net_worth, color='green') # color = 'green'
plt.xlabel("Time")
plt.ylabel("Net Worth")
plt.title("Net Worth over Time")
plt.show()
input()
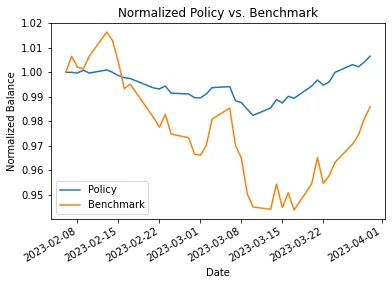
결과는 다음 그림과 같다. 강화학습된 모델을 사용했을 때, 시간이 지나면서 순자산이 어떻게 증가하는 지를 확인할 수 있다.
단, 이 결과는 패턴이 일관성있게 변화할 때 얻을 수 있는 결과이며, 펜데믹같이 예측하기 어려운 이벤트는 학습 데이터가 없었으므로 당연히 탐지하지 못한다. 다음은 주식 VWAP, RSI를 고려해, 강화학습한 모델로 주식 자동 트레이딩하였을때 자산가치를 보여준다.

Google stock trading net worth (timestemps=10000)

Apple stock trading net worth (timestemps=50000)
파이토치로 주식 트레이딩 강화학습 직접 구현하기
앞서 코딩된 강화학습은 stable baseline3 라이브러리를 사용한 것이다. 강화학습기술의 내부 메커니즘을 관찰하기 위해, 주식 자동 거래 강화학습 모델의 구현 코드를 확인해 본다.
주식 거래 데이터는 앞서 언급한것과 동일한 형식인 엑셀파일로 저장되어 있다. 다음은 강화학습 시 사용될 거래 데이터 이력이다.

애플 주가 이력 데이터
강화학습 코드 개발 순서는 다음과 같다.
- 보상 알고리즘이 포함된 환경 정책 클래스를 정의
- Q-네트워크 모델 정의
- 에이전트 정의
- 관찰 상태 데이터 학습에 사용될 재생 메모리 버퍼 정의
- DQN 기법으로 보상 최대화되도록 학습
다음은 이와 관련된 상세 코드이다.
import os, time, copy, random, logging
import numpy as np, pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
from collections import namedtuple, deque
# 주식 데이터 로딩
data = pd.read_csv('./AAPl2.csv')
data['Date'] = pd.to_datetime(data['Date'])
data = data.set_index('Date')
print(data.index.min(), data.index.max())
data.head()
# 학습, 테스트 데이터 분할
date_split = '2022-01-01'
train = data[:date_split]
test = data[date_split:]
print(len(train), len(test))
# 학습 데이터 그래프 출력
data = [
Candlestick(x=train.index, open=train['Open'], high=train['High'], low=train['Low'], close=train['Close'], name='train'),
Candlestick(x=test.index, open=test['Open'], high=test['High'], low=test['Low'], close=test['Close'], name='test')
]
layout = {
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)
# 주식 마켓 환경 정책
class StockMarketEnv:
def __init__(self, data, history_t=90):
self.data = data
self.history_t = history_t
self.reset()
def reset(self):
self.t = 0
self.done = False
self.total_profits = 0
self.profits = 0
self.positions = []
self.position_value = 0
self.history = [0 for _ in range(self.history_t)]
reward = 0
return [self.position_value] + self.history, reward ,self.done# obs
def step(self, act):
reward = 0
# 액션. 0=보유, 1=buy, 2=sell
if act == 1: # 구매, 구매 시점 종가 기록
self.positions.append(self.data.iloc[self.t, :]['Close'])
elif act == 2: # 판매
if len(self.positions) == 0: # 구매 기록이 없을 때
reward = -1
else:
profits = 0
for p in self.positions: # 구매 주식이 있을 때
profits += (self.data.iloc[self.t, :]['Close'] - p) # 이익 = 현재 종가 - 구매 주식 가격들
reward += profits # 리워드 최대치 계산(이익 총합)
self.profits += profits
self.positions = []
self.total_profits += self.profits
self.t += 1 # 관찰 시점 다음 이동
self.position_value = 0
for p in self.positions:
self.position_value += (self.data.iloc[self.t, :]['Close'] - p)
self.history.pop(0)
self.history.append(self.data.iloc[self.t, :]['Close'] - self.data.iloc[(self.t-1), :]['Close'])
# 보상치 계산
if reward > 0:
reward = 1
elif reward < 0:
reward = -1
return [self.position_value] + self.history, reward, self.done # 관찰, 보상, 에피소드 종료
import torch
import torch.nn as nn
import torch.nn.functional as F
class QNetwork(nn.Module):
def __init__(self, state_size, action_size, seed, fc1_units=64, fc2_units=64): # 상태 차원수, 액션 차원수, 램덤값, FC1 유닛수, FC2 유닛수
super(QNetwork, self).__init__()
self.seed = torch.manual_seed(seed)
self.fc1 = nn.Linear(state_size, fc1_units)
self.fc2 = nn.Linear(fc1_units, fc2_units)
self.fc3 = nn.Linear(fc2_units, action_size)
def forward(self, state):
x = F.relu(self.fc1(state)) # 관찰 상태 벡터 입력
x = F.relu(self.fc2(x))
return self.fc3(x) # 액션 출력
# 에이전트 학습 준비
BUFFER_SIZE = int(1e5) # 재생 메모리 버퍼 크기
MINI_BATCH_SIZE = 64 # 미니 배치 크기
GAMMA = 0.99 # 할인율 감마값
TAU = 1e-3 # 타겟 네트워크 파라메터 소프트 업데이트를 위한 타오 계수
LR = 5e-4 # 학습율
UPDATE_EVERY = 4 # 네트워크 갱신 빈도수
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Agent():
def __init__(self, state_size, action_size, seed, DDQN=False): # 상태 차원 크기, 액션 차원 크기, 램덤값, DDQN 학습 플래그
self.state_size = state_size
self.action_size = action_size
self.seed = random.seed(seed)
# Q-Network 지역, 타겟 네트워크 준비
print("state size :",self.state_size)
print("action size :",self.action_size)
self.qnetwork_local = QNetwork(state_size, action_size, seed).to(device)
self.qnetwork_target = QNetwork(state_size, action_size, seed).to(device)
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=LR)
# 재생 메모리 버퍼 준비
self.memory = ReplayBuffer(action_size, BUFFER_SIZE, MINI_BATCH_SIZE, seed)
# 타임 스템프 인덱스 설정
self.t_step = 0
self.DDQN = DDQN
print("DDQN is now :",self.DDQN)
def step(self, state, action, reward, next_state, done):
# 재생 메모리 버퍼에 상태, 액션, 보상, 다음 상태, 종료 플래그 저장
self.memory.add(state, action, reward, next_state, done)
# 매 시점별 타임스템프 업데이트
self.t_step = (self.t_step + 1) % UPDATE_EVERY
if self.t_step == 0: # 샘플수가 충분히 모이면, 재생버퍼에서 저장된 데이터 샘플링하여 학습
if len(self.memory) > MINI_BATCH_SIZE:
experiences = self.memory.sample()
self.learn(experiences, GAMMA)
def act(self, state, eps=0.): # 현재 상태, epsilon-greedy 액션 선택 엡실론값
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
self.qnetwork_local.eval()
with torch.no_grad():
action_values = self.qnetwork_local(state) # 상태값에 대한 로컬 모델 예측 액션값 획득
self.qnetwork_local.train() # 로컬 모델 네트워크 학습
# Epsilon-greedy 액션 선택
if random.random() > eps:
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
def learn(self, experiences, gamma): # 관찰 데이터(s, a, r, s', done), 할인율 감마값
states, actions, rewards, next_states, dones = experiences
Q_expected = self.qnetwork_local(states).gather(1, actions) # 현재 상태에 대한 지역 네트워크 모델 현재 보상 획득
# 다음 상태에 대한 타겟 네트워크 모델 미래 보상 획득
if self.DDQN: # DDQN 알고리즘
next_actions = torch.max(self.qnetwork_local(next_states), dim=-1)[1]
next_actions_t = torch.LongTensor(next_actions).reshape(-1,1).to(
device=device)
target_qvals = self.qnetwork_target(next_states)
Q_targets_next = torch.gather(target_qvals, 1, next_actions_t).detach()
else: # DQN 알고리즘
Q_targets_next = self.qnetwork_target(next_states).detach().max(1)[0].unsqueeze(1)
Q_targets = rewards + (gamma * Q_targets_next * (1 - dones))
loss = F.mse_loss(Q_expected, Q_targets) # loss = 현재 보상 - 미래 보상
self.optimizer.zero_grad() # loss 최소화
loss.backward() # 네트워크 역전파
self.optimizer.step() # 한단계 실행
self.soft_update(self.qnetwork_local, self.qnetwork_target, TAU) # 목표 학습 모델 파라메터 갱신
def soft_update(self, local_model, target_model, tau): # 지역 모델, 목표 모델, 인터폴레이션 비율 타오값
# Soft update model. θ_target = τ*θ_local + (1 - τ)*θ_target
for target_param, local_param in zip(target_model.parameters(), local_model.parameters()):
target_param.data.copy_(tau*local_param.data + (1.0-tau)*target_param.data)
class ReplayBuffer:
def __init__(self, action_size, buffer_size, MINI_BATCH_SIZE, seed): # 액션 차원 크기, 재생 메모리 버퍼 크기, 미니배치 크기, 랜덤값
self.action_size = action_size
self.memory = deque(maxlen=buffer_size)
self.MINI_BATCH_SIZE = MINI_BATCH_SIZE
self.experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])
self.seed = random.seed(seed)
def add(self, state, action, reward, next_state, done): # 경험 및 재생 메모리에 현재 상태 데이터 추가
e = self.experience(state, action, reward, next_state, done)
self.memory.append(e)
def sample(self): # 미니배치 학습 데이터 샘플링하기
experiences = random.sample(self.memory, k=self.MINI_BATCH_SIZE)
states = torch.from_numpy(np.vstack([e.state for e in experiences if e is not None])).float().to(device)
actions = torch.from_numpy(np.vstack([e.action for e in experiences if e is not None])).long().to(device)
rewards = torch.from_numpy(np.vstack([e.reward for e in experiences if e is not None])).float().to(device)
next_states = torch.from_numpy(np.vstack([e.next_state for e in experiences if e is not None])).float().to(device)
dones = torch.from_numpy(np.vstack([e.done for e in experiences if e is not None]).astype(np.uint8)).float().to(device)
return (states, actions, rewards, next_states, dones)
def __len__(self):
return len(self.memory)
def train_DQN(n_episodes=1500, max_t=300, eps_start=1.0, eps_end=0.01, eps_decay=0.995,pth_file = 'checkpoint.pth'):
eps = eps_start # initialize the score
scores_window = deque(maxlen=100) # 스코어 저장 큐
scores = []
total_profits_history = []
logging.info('Starting of agent training ......')
for episode in range(1,n_episodes+1):
next_state, reward, done = env.reset() # 환경 초기화
state = next_state # 현재 상태 획득
score = 0
for time_step in range(max_t):
action = agent.act(np.array(state), eps) # 액션 선택
next_state, reward, done = env.step(action) # 액션에 대한 보상 획득
agent.step(state, action, reward, next_state, done) # 에이전트 액션 실행
score += reward # 보상 스코어값 누적
state = next_state # 다음 상태를 현재 상태로 설정
eps = max(eps_end, eps_decay * eps) # epsilon-greedy 액션 선택 엡실론값
if done:
break
scores.append(score)
scores_window.append(score) # 현재 스코어 저장
total_profits_history.append(env.total_profits)
print('\rEpisode {}\tAverage Score: {:.2f}'.format(episode, np.mean(scores_window)), end="")
if episode % 100 == 0:
print('\rEpisode {}\tAverage Score: {:.2f}'.format(episode, np.mean(scores_window)))
if np.mean(scores_window)>=5000:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(episode-100, np.mean(scores_window)))
torch.save(agent.qnetwork_local.state_dict(), pth_file)
break
return scores, reward
state_size = 91 # 90일 이전 가격 + 현재 가격 상태 데이터 획득을 위한 크기 변수
action_size = 3 # 보유 = 0 , 구매 = 1 , 판매 = 2
agent = Agent(state_size, action_size, 99, False)
env = StockMarketEnv(train)
start_time = time.time()
episode_count = 50 #
scores_dqn_base, reward = train_DQN(n_episodes=episode_count, pth_file='checkpoint_dqn.pth')
print("Total run time to achieve average score : %s seconds " % (time.time() - start_time))
# plot results
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(total_profits_history)), total_profits_history) # 이익
plt.ylabel('Profit')
plt.xlabel('Episode #')
plt.title('DQN Reward Graph over Time for Profit')
plt.show()
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores_dqn_base)), scores_dqn_base) # 개별 보상 스코어
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.title('DQN Reward Graph over Time for Stock Price')
plt.show()
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(pd.Series(scores_dqn_base).rolling(10).mean())), pd.Series(scores_dqn_base).rolling(10).mean()) # 평균 보상 스코어
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.title('DQN Reward Graph over Time for Stock Price')
plt.show()
input()
실행 결과는 다음과 같다. 보상이 최대값으로 해가 수렴하는 것을 볼 수 있다.


보상 스코어 및 마켓 거래 총 이익 그래프
사실, 대부분 시장 제품 거래(에너지, 상품, 무역, 물류 등)는 거의 구현방식이 유사하다. 주식 마켓 트레이딩 강화학습과 관련된 좀 더 상세한 내용은 다음을 참고한다.
참고로, 주식 거래 이력 데이터는 다음 링크에서 다운로드할 수 있다.
마무리
지금까지 전체적으로 강화학습 개념, 발전역사, OpenAI의 gym을 사용한 강화학습 실험 및 직접 DQN의 딥러닝 에이전트를 개발하는 과정을 확인해 보았다. 이를 통해, 특정 게임과 같이 정책이 있는 환경은 보상 알고리즘을 설계한 후, 강화학습을 적용해, 용이하게 학습모델을 개발해 사용할 수 있다.
좀 더 많은 강화학습 응용 예시는 부록을 참고하길 바란다.
레퍼런스
- Welcome to Spinning Up in Deep RL! — Spinning Up documentation (openai.com)
- Reinforcement Learning for Trading Tutorial | $GME RL Python Trading
- Building a Custom Environment for Deep Reinforcement Learning with OpenAI Gym and Python
- Deep Reinforcement Learning Tutorial for Python in 20 Minutes
- Deep Reinforcement Learning with OpenAI Gym in Python
- Deep Reinforcement Learning TO Predict Stock
- Reinforcement Learning to Reduce Building Energy Consumption | by Enrico Busto - EN | Analytics Vidhya | Medium
- Deep RL in the Real World | Dibya's School
- Institute for Machine Learning @ JKU | Reinforcement Learning (ml-jku.github.io)
- DQN vs PPO. Discussion with my mentors (jerrickliu.com)
- Stock Trading AI Bot Using Python | ML Trading - PyCodeMates
강화학습을 이용해 규칙과 보상이 있는 주식 트레이딩 모델을 개발할 수 있다. 상세 내용은 다음 자료를 참고 한다.
도시 건물 에너지 관련 딥러닝 모델 개발 시 참고할만한 예시는 다음과 같다.
- Urban building energy performance prediction and retrofit analysis using data-driven machine learning approach - ScienceDirect
- Energy consumption forecast in peer to peer energy trading | Discover Applied Sciences
- Full article: Implementing a web-based optimized artificial intelligence system with metaheuristic optimization for improving building energy performance
- Building Energy Data Analysis Part One | by Will Koehrsen | Medium
- A three-year dataset supporting research on building energy management and occupancy analytics | Scientific Data
- A three-year building operational performance dataset for informing energy efficiency
도시 건물 에너지 및 운영 데이터셋은 다음을 참고한다.
- Predicting_the_Energy_Efficiency_of_Buildings: In this section, predicting the energy efficiency of buildings with machine learning algorithms
- Building Performance Database (lbl.gov)
- Tools & Guides | Building Technology and Urban Systems (lbl.gov)
- Buildings Datasets (trynthink.github.io)
- OEDI: AlphaBuilding - Synthetic Buildings Operation Dataset (openei.org)
- Scientific Data (nature.com)
- A Synthetic Building Operation Dataset | AlphaBuilding-SyntheticDataset (lbnl-eta.github.io)
- Performance dataset on a nearly zero-energy office building in temperate oceanic climate based on field measurements - ScienceDirect
- Field measurement dataset of a nearly zero-energy office building in temperate oceanic climate - Harvard Dataverse
- NREL/BuildingsBench: Large-scale pretraining and benchmarking for short-term load forecasting. (github.com)
- Mendeley Data
- Building Performance Database API (BPD API) v2.1 (Software) | OSTI.GOV
- ROBOD, room-level occupancy and building operation dataset | Building Simulation (springer.com)
- Energy Efficiency Dataset (kaggle.com)
- Energy Data Resources | The Nicholas Institute for Energy, Environment & Sustainability (duke.edu)
- Building Energy Performance | Open Data DC
- Big Data for Building Energy Management - What Can it Do? (buildingsiot.com)
- Building Energy Performance | Open Data DC
- samy101/lead-dataset: A Large-scale annotated dataset for Energy Anomaly Detection in commercial buildings (github.com)
- Resources - SIGENERGY (acm.org)
- UCLA Engage Building Performance Dataset — Institute of the Environment and Sustainability at UCLA
부록: 건물 도시 에너지 활용 최적화를 위한 강화학습 도구
건물 도시 에너지 활용 최적화를 위한 강화학습 도구도 개발되어 있다. 이 경우, 정책에 대한 보상과 관찰 데이터는 보통 다음과 같다.
Observation data
energy_per_price(kW)
outdoor_temp
comfort_temp_max
comfort_temp_min
Policy
reward = comfort + 1 / device_switching_cost - energy_cost
이에 관심이 있다면, 다음 링크를 참고한다.
- CityLearn: Official reinforcement learning environment for demand response and load shaping
- building-energy-storage-simulation: An open source playground energy storage environment to explore reinforcement learning and model predictive control
- Energym is an open source building simulation library designed to test climate control and energy management strategies on buildings in a systematic and reproducible way
- TheGreenCitySolutionsGroup: Forecasting building energy demand through time series analysis and machine learning. (github.com)
- Stock_DRL: Using Deep reinforcement learning (DRL) agent to learn from historical data
- European wholesale electricity price data | Ember
- Data Platform – Open Power System Data

부록: 거주환경 쾌적성 지속을 위한 강화학습 예시
- Implementation of Research paper, Deep reinforcement learning based framework for energy optimization and thermal comfort control in smart buildings
- hvac-rl: Testing environment for Reinforcement Learning Solutions in HVAC deployment
부록: 배터리 운영 최적화를 위한 강화학습 예시
BEMS(Building Energy Management System), HEMS (Home EMS), CEMS(Community EMS)와 같은 배터리 충방전을 효과적으로 사용하는 운영모델을 개발할 수 있다. 이 경우, 관찰 데이터는 보통 다음과 같다.
전력비용SOC 충전상태부하에 따른 장비 전력 소모
관련 자료는 다음과 같다.
부록. 파이토치 기반 딥러닝 강화학습 개발
파이토치 기반으로 개발하고자 하면, 다음 링크를 참고한다.

각 페이소드 당 최대 보상을 얻을 때 타임스텝 수(시간이 지날수록 타임스텝이 적더라도 최대보상을 얻는 경우가 많아짐)
부록. 기타 응용 별 딥러닝 강화학습 예제
기타 다른 응용 별 딥러닝 강화학습 예제는 다음 링크를 참고한다.
부록. 사용자 Custom Enviroment 개발 방법
- Creating Custom Environments in OpenAI Gym | Paperspace Blog
- Reinforcement Learning using Stable Baselines — Omniverse IsaacSim latest documentation (nvidia.com)
- Gym Trading Environment (gym-trading-env.readthedocs.io)
- How to create a custom Open-AI Gym environment? with codes and example
- Creating an Automated Stock Trading System using Reinforcement Learning | by Sam Erickson | Dec, 2023 | Medium
부록. OpenAI LLM 과 강화학습