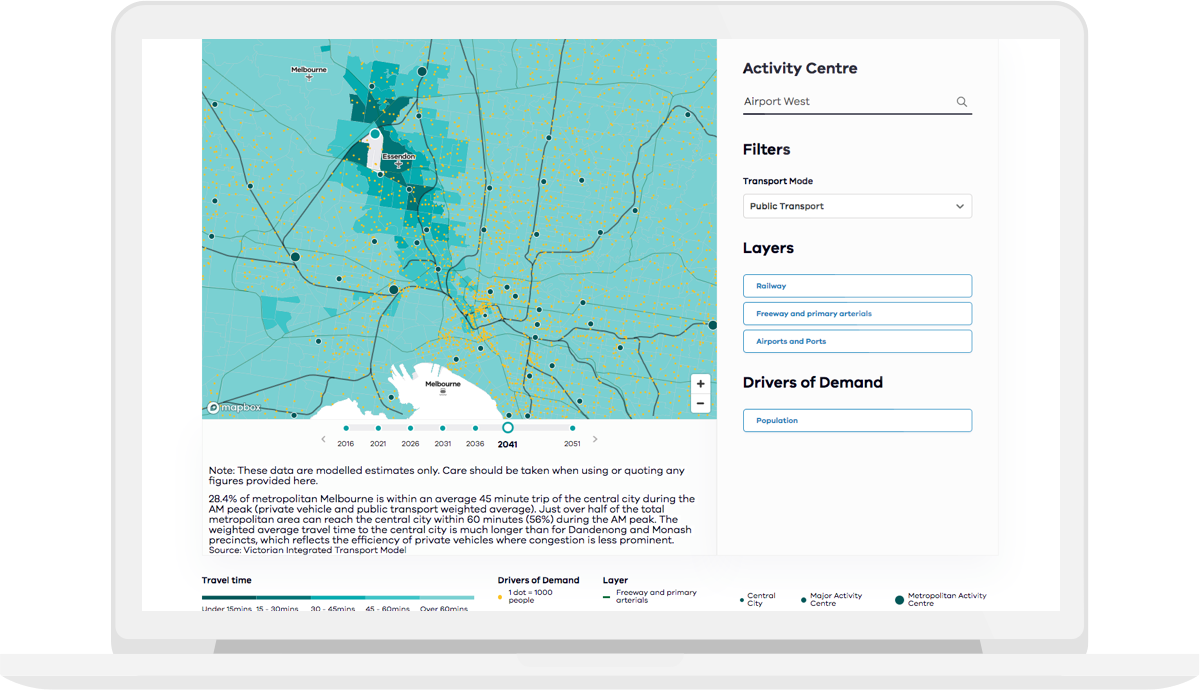
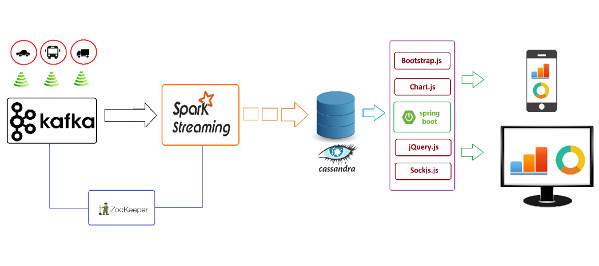
이 글은 GeoServer 기반 CesiumJS 지도 웹 서버 어플리케이션 개발 방법을 간략히 설명한다. Cesium을 이용하면 WebGL 기반 공간정보 서비스가 가능하며, 3차원 그래픽 모델 등을 표현하기 쉽다. Geoserver를 이용해 사용자가 직접 만든 지도 데이터를 레이어로 렌더링하여, Cesium 플랫폼 위에 보여줄 수 있다.
Cesium 개념 및 사용 방법을 전혀 모른다면 다음 링크를 미리 참고한다.
머리말
이 예제는 Google map, OSM(OpenStreetMap) 등에서 제공하지 않는 형태의 지도 데이터를 사용해 인터렉티브한 맵 어플리케이션을 개발하고 싶을 때 유용하다. 이 예제는 오픈소스로 유명한 GeoServer, PosgreSQL, PostGIS를 사용한다. 이 예제에 대한 좀 더 상세한 내용은 이 글의 마지막 레퍼런스들을 참고하길 바란다. 참고로, 이 예제는 윈도우즈10 환경에서 개발하지만, 환경 설치나 예제 실행은 우분투, 리눅스에서도 똑 같이 동작한다. 다음은 예제에서 사용하는 기술 스택이다.
각 컴포넌트 역할은 다음과 같다.
- CesiumJS: Cesium 기반 웹 서비스 개발을 지원하는 Javascript 모듈
- Cesium: WebGL 기반 동적 그래픽 지도 렌더링 및 이벤트 처리를 지원하는 플랫폼
- Geoserver: 다양한 형식의 지도 레이어 렌더링을 지원하는 서버
- PostGIS: PostgreSQL 데이터베이스의 정보 검색 SQL 질의 애드인(addin).
- PostgreSQL: 객체 관계형 데이터베이스. 다양한 형식의 지도 데이터를 체계적으로 저장, 관리하기 위해 사용
Geoserver, PostgreSQL, PostGIS 설치
자제 지도 데이터를 사용하기 위해서 다양한 형식의 지도 데이터를 렌더링할 수 있는 Geoserver를 사용한다. Geoserver를 설치하기 위해서는 Java SDK가 필요하다. 공간정보 데이터베이스가 필요하다면 PostgreSQL DBMS와 공간정보 질의 기능을 지원하는 PostGIS 애드인을 미리 설치해야 한다. 다음 링크에서 각 설치 프로그램을 다운로드할 수 있다.
Geoserver 설치
Geoserver start 화면
다음과 같이 PostgreSQL 설치 후 바로 실행되는 Stack Builder를 통해 PostGIS 애드인을 설치한다. 그 후, 설치된 pgAmin4를 실행해 PostgreSQL 데이터베이스 서버를 시작해 본다.
PostgreSQL과 PostGIS 설치
Stack Builder를 통한 PostGIS 설치 완료
설치된 프로그램 중 PostgreSQL DBMS 관리를 지원하는 pgAdmin4를 실행한다. 다음과 같은 화면이 보이면 성공한 것이다.
pgAdmin4를 통한 PostgreSQL 서버 실행 모습
CesiumJS Starter Kit 준비 및 실행
Javascript로 동작되는 cesiumjs는 9000 포트, GeoServer는 8080 포트를 사용한다. cesiumjs 어플리케이션 개발을 지원하기 위해, cesium에서는 예제 템플릿과 설명을 다음과 같이 제공한다.
다음과 같이 Starter Kit 소스코드를 다운로드한다.
git clone https://github.com/Cingulara/cesium-starterkit.git
git clone으로 코드를 다운로드 받으면 폴더 안에 index.html 이 있고, 그 안에 css, javascript import 등이 코딩되어 있다. 폴더 내 cesium-scripts.js는 cesiumjs API, 웹 맵 서버와 상호동작 등의 기능을 포함하고 있다. js 파일 18행에 cesium 사용을 위해 다음과 같이 cesium API key 값을 입력한다.
Cesium.Ion.defaultAccessToken = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiI5MDA1OGJhMi04NTY0LTQ0NDgtOWZkNi02ZWM1YzE1Y2VkODUiLCJpZCI6MjI3NzksInNjb3BlcyI6WyJhc3IiLCJnYyJdLCJpYXQiOjE1ODIwMzI3MTJ9.le7e8JdjCMK94zUohux5Wu-CWF0ydrrh7vSvxU3ZR4U';
이 예제를 웹 서버로 실행하려면 HTTP 서버를 먼저 설치해야 한다. 웹 서버 중에
아파치(
설치),
NGINX(
설치 및
사용법)가 유명하나 이 경우에는 간단하게 python에 내장된 SimpleHTTPServer(python 2.x 버전), http.server(python 3.x 버전)를 이용한다.
우선 Geoserver를 실행한다. 그 후, 다음처럼 HTTP 서버를 실행한다(python 3.x 버전의 경우. 상세 내용은
Local server, Mozilla 참고).
python -m http.server 9000
Geosever와 HTTP server 실행 모습
HTTP 서버 실행 후 크롬에서 localhost:9000 접속하면 다음 같은 결과를 볼 수 있다.
실행 결과
다른 서버 도메인의 자바 스크립트 어플리케이션에서 GeoServer 를 사용하려면 GeoServer의 CORS(Cross-Origin Resource Sharing)을 활성화해야 한다(도메인이 서로 다르면 Javascript에서 Geoserver 데이터를 다운로드할 수 없다). 우선 GeoServer 가 설치된 경로에서 web.xml 파일을 찾아 CORS filter 및 filter-mapping xml 태그 주석을 아래와 같이 해제한다. 그리고, Geoserver를 재시작한다.
CORS에 대한 좀 더 상세한 내용은 다음 링크를 참고한다.
Geoserver와 CesiumJS 연동 코드 분석
Geoserver와 같은 지도 이미지 제공 서버를 위해 세슘은 Cesium.WebMapServiceImageryProvider 함수를 제공한다. cesium-scripts.js의 44행에는 상호 연동을 위한 코드가 다음과 같이 구현되어 있다. 이 함수는 Geoserver webservice API url 및 관련 parameters를 입력받는다. 코드를 분석해 보면, 2개의 레이어를 추가하고 있는 데, 플로리다 이미지(florida:NE1_50M_SR_W) 및 도로망 맵(florida:FL_planet_osm_roads)이다. 이 맵 데이터 모두 geoserver에서 webservice 방식인 wms(web mapping server)로 제공한다.
var worldMap = new Cesium.WebMapServiceImageryProvider({
url : 'http://localhost:8080/geoserver/wms',
parameters: {
format:'image/png',
transparent:'true',
tiled: true,
enablePickFeatures: true
},
layers : 'florida:NE1_50M_SR_W', // comma separated listing
maximumLevel : 12
});
...
var detailedMaps = new Cesium.WebMapServiceImageryProvider({
url : 'http://localhost:8080/geoserver/wms',
parameters: {
format:'image/png',
transparent:'true',
tiled: true,
enablePickFeatures: true
},
layers : 'florida:FL_planet_osm_roads', // comma separated listing
maximumLevel : 20
});
florida:NE1_50M_SR_W, florida:FL_planet_osm_roads 모두 geoserver에 등록되어 있지 않으므로, 해당 지도 데이터를 준비해 geoserver 레이어로 추가해야 한다.
참고로, js 소스 안에 레이어들을 켜고 끌 수 있는 changeLayer함수가 정의되어 있다. 원하면, 레이어를 이런 방식으로 조작할 수 있다.
function changeLayers(value) {
if (value == "satellite"){
viewer.imageryLayers._layers[0].show = true;
viewer.imageryLayers._layers[1].show = false;
viewer.imageryLayers._layers[2].show = false;
}
else if (value == "roads"){
viewer.imageryLayers._layers[0].show = true;
viewer.imageryLayers._layers[1].show = false;
viewer.imageryLayers._layers[2].show = true;
}
else if (value == "hybrid"){
viewer.imageryLayers._layers[0].show = false;
viewer.imageryLayers._layers[1].show = true;
viewer.imageryLayers._layers[2].show = true;
}
}
GeoServer 지도 데이터 레이어 추가
앞서 설명했듯이 본 예제의 js 소스코드에 두개 지도 데이터 형식을 Geoserver에 레이어로 추가해야 한다. 오픈소스
QGIS, Arcgis, CAD를 이용해 지도 데이터를 만들 수 있겠지만, 지금은 맵 서비스 개발 방법 이해가 중요하므로, 기존에 만들어진 지도 데이터를 다운로드해 사용할 것이다. 이 예제에서 지도 데이터를 가공해 맵 서비스를 개발하는 과정은 다음과 같다.
우선, florida:NE1_50M_SR_W 레이어 용 GeoTiff 형식 데이터를 준비한다. 이를 위해, naturalearthdata.com 을 방문하여
Shaded Relief and Water 데이터를 다음과 같이 다운로드 한다.
다운로드 압축파일을 풀고, geoserver의 data 폴더에 worldmap 폴더를 아래와 같이 만들어 넣는다.
Geoserver를 시작하고, 다음과 같이 새로운 작업공간을 만든다.
Geoserver에서 새로운 데이터 저장소를 선택하여, 다음과 같이 GeoTiff 메뉴를 선택해 앞에서 다운로드한 NE1_50M_SR_W.tif 파일을 업로드한다.
GeoTiff 파일이 추가되면, 다음과 같이 레이어 미리보기에서 해당 지도 데이터를 확인할 수 있다.
이제 florida:FL_planet_osm_roads 지도 데이터 레이어를 만들 차례다. psql CLI(command line interface)를 실행해 다음과 같은 순서로 PostgreSQL에 데이터베이스를 만들고, postgis를 사용하기 위해 확장 구조를 DB에 등록한다.
create database floridamaps;
\c floridamaps;
create extension postgis;
create extension postgis_topology;
create extension hstore;
psql 명령 입력 모습
PostgreSQL DB 생성 결과
geofabrik.de 사이트에서
OSM 지도 데이터를 다운로드 받는다. 압축울 풀고, osm2pgsql 프로그램(
설치 방법)을 이용해 다음과 같이 PostgreSQL DB(database)로 변환한다.
osm2pgsql -C 2048 -s -H localhost -P 5432 -d floridamaps ./florida-latest.osm -C 2048 --slim --number-processes 2 --password --username postgres
osm2pgsql 의 --username 은 PostgreSQL DB username 과 동일하다. PostgreSQL 설치 시 디폴트는 postgres 이다. --password 옵션을 추가하면 사용자 암호 입력을 받는다. 설치 시 postgres 유저에 대한 암호를 입력하면, 다음과 같이 변환 과정이 실행된다.
osm2pgsql 변환 과정
변환 작업이 끝나면, 다음과 같이 pgAdmin의 SQL창에서 변환된 지도 데이터를 확인해 본다. 쿼리 결과가 올바르면 OSM 지도 데이터가 정상 변환 된 것이다.
SELECT COUNT(*) FROM public.planet_osm_point
UNION
SELECT COUNT(*) FROM public.planet_osm_line
UNION
SELECT COUNT(*) FROM public.planet_osm_polygon
쿼리 결과
이제 다음과 같이 새로운 저장소로 PostGIS을 추가한다. 앞서 생성한 PostgreSQL database, user, password를 입력한다.
다음과 같이 Geoserver에 생성된 저장소의 planet_osm_roads를 florida:FL_planet_osm_roads 레이어로 추가한다. 이 때, 레이어 최소 경계 영역은 '데이터로부터 계산하기', '원본 영역으로부터 계산하기'버튼을 클릭해 자동 입력해 넣는다.
레이어 추가 화면
레이어가 정상 추가되었다면 다음과 같이 레이어 미리보기를 할 수 있다. OpenLayers 버튼을 클릭해 지도가 제대로 표시되는 지 확인하자.
레이어 미리보기
미리보기 결과
GeoServer에 다음과 같이 레이어 맵이 추가되어 있다면, Cesium에서 이 레이어를 렌더링해 오버레이 할 수 있다.
레이어 명과 앞서 설명한 cesium-scripts.js 소스코드 안에 지정된 레이어 명은 서로 같아야 함에 주의한다.
다시 HTTP server를 실행해 Geoserver에서 제공되는 레이어가 표시된 CesiumJS 지도 앱 어플리케이션 실행 결과를 확인해 본다.
Cesium Roads 레이어 켜졌을 때 지도 앱 모습
지도 앱 어플리케이션 실행 결과
Geoserver에서 다운로드되는 지도 데이터 로그와 PostgreSQL Transactions 처리 모습
CesiumJS 기반 지도 앱 서버가 잘 실행되는 것을 확인할 수 있다. 만약, 제대로 동작하지 않는 다면
크롬에서 개발자 도구로 디버깅 로그를 확인해 보길 바란다. 각 단계를 따라하였다면 잘 실행될 것이다.
마무리
최근 스마트시티, 디지털 트윈, 스마트 건설과 같은 서비스 요구가 많아지고 있다. 이런 서비스에 공간정보는 중요한 서비스 기반이다. 세슘 플랫폼을 이용하면 다양한 데이터 소스와 연결하여 공간정보 기반으로 시각화하고 의사결정 데이터 서비스를 쉽게 개발할 수 있다.
본 글에서 설명한 Cesium Start kit 예제를 목적에 맞게 확장하기는 어렵지 않다. Geoserver를 사용하면 사용자가 Cesium에서 기본 제공하지 않은 지도 형식을 쉽게 확장할 수 있다. cesuim은 webgl을 기반으로 하는 다양한 데이터 소스 연결, 2D/3D 그래픽 생성, 이벤트 처리, 서버 연결 방법 등을 제공하고 있기 때문에 인터렉티브한 맵 어플리케이션 서버 개발이 그리 어렵지 않을 것이다.
레퍼런스