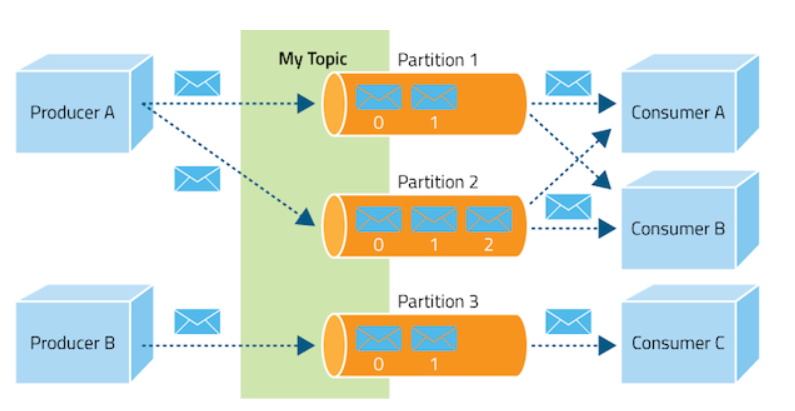
이 글은 빅데이터를 고려한 카프카 기반 Raspberry Pi(RPi) IoT 시스템을 개발하는 방법을 간단히 다루어 본다. 카프카는 대용량 메시지 처리, IoT 센서 데이터, 빅데이터 처리 등에 MongoDB와 함께 사용되는 경우가 많다. 참고로, 카프카 개발팀은 스타트업 Confluent 사를 설립했는 데, 시리즈 D에서 1억 2500만달러를 투자받았고, 자산가치는 25억달러로 평가받고 있다(참고). 현재, 카카오, 네이버 라인 등 많은 회사에서 카프카를 메시지 미들웨어 핵심 엔진으로 사용하고 있다.
이 내용은 다음 목적에 유용하다.
라즈베리파이는 임베디드 보드라 메모리 제약이 심하다. 이런 이유로 기대한 만큼 카프카 성능과 안전성이 좋지 않을 수도 있다. 만약, 라즈베리파이를 단지 IoT 데이터 취득 목적으로만 사용하고, 별도 서버(IBM 호환 PC, 엔비디아 보드 등)에 카프카와 주키퍼를 서비스한다면 파이썬의 카프카 라이브러리 함수인 KafkaProducer, KafkaConsumer를 사용하면 된다. 이 내용은 아래 부록이나 링크를 참고한다.
하드웨어를 다음과 같이 준비한다.
소프트웨어를 다음과 같이 준비한다.
vim /etc/hostname # and set a name like raspberry-8.
vim /etc/hosts # Replace raspberry with your new name.
카프카 서버 실행 화면
좀더 자세한 내용은 아래를 참고한다.
이 글에서 개발할 센서는 온습도, 거리 센서이다. 센서 회로 연결 시 아래 RPi 보드 핀 레이아웃을 참고한다. 빅데이터 분산 처리 메시지 스트리밍 개발의 목적이므로, 간단한 회로 작성을 위해 저항 등은 연결하지 않았다. 다음 예시의 회로 연결은 실습용이니 참고하길 바란다.
RPi 핀 번호
개발 환경 설치
우선 아래와 같이 파이선 라이브러리를 설치한다.
sudo apt-get update
sudo apt-get install python-pip
sudo python -m pip install --upgrade pip setuptools wheel
sudo pip install kafka-python
sudo pip install
Adafruit_DHT
데이터 분석, 비전을 개발한다면, 다음 패키지도 함께 설치한다(설치가 안된다면, 해당 패키지 github에서 설치방법을 확인한 후 수동으로 설치해야 한다).
sudo pip install scikit-learn numpy
sudo pip install opencv-python imageio Pandas Pillow
아두이노 개발하려면 아래를 설치한다.
sudo apt-get install arduino
DHT11을 라즈베리파이와 다음과 같이 연결한다.
DHT11 Vcc - RPi 5V
DHT11 GND - RPi GND
DHT11 Data - RPi GPIO No 2
DHT11 온습도 센서 핀 배치
다음과 같이 코딩한다. 카프카로 IoT 주제로 데이터를 생성한다.
from kafka import KafkaProducer
from json import dumps
import RPi.GPIO as GPIO
import Adafruit_DHT as ada
import time
producer = kafkaProducer(bootstrap_servers=['localhost:9092'], value_serializer=lambda x: dumps(x).encode('utf-8'))
dht = ada.DHT11
pin = 2 # GPIO No 2
print("start")
while True:
h, t = ada.read_retry(dht. pin)
data = {'temp': [h, t]}
if h is not None and t is not None:
producer.send("safety", value = data)
print("T={0}, H={1}".format(t, h))
else:
print("none")
time.sleep(0.5)
다음과 같이 실행되면 카프카로 센서 메시지 발행이 성공한 것이다.
RPi기반 카프카 분산 메시지 스트리밍 실행 결과
네트웍 IP 주소가 있다면, 다른 컴퓨터에서 연결한 카프카 CONSUMER에서 라즈베리파이에서 발생한 센서 데이터 메시지를 스트리밍받아 볼 수 있다.
라즈베리파이 작업관리자를 확인해 보면, 카프카 실행상태에서 리소스 사용은 CPU 5-20%, 메모리 662MB/874MB이였으며, 다음과 같았다.
거리센서 설치 및 코딩
거리센서 HC-SR04를 아래와 같이 연결한다. 카프카 safety 주제(토픽)으로 data를 생성해본다.
회로 연결
RPi의 GPIO 라이브러리를 이용해 아래와 같이 dist.py파일을 코딩한다.
from kafka import KafkaProducer
from json import dumps
import RPi.GPIO as GPIO
import time
producer = kafkaProducer(bootstrap_servers=['localhost:9092'], value_serializer=lambda x: dumps(x).encode('utf-8'))
GPIO.setmode(GPIO.BCM) #Set GPIO pin numbering
trig = 23
echo = 24
GPIO.setup(trig,GPIO.OUT)
GPIO.setup(echo,GPIO.IN)
while True:
GPIO.output(trig, False)
time.sleep(1)
GPIO.output(trig, True)
time.sleep(0.00001)
GPIO.output(trig, False)
while GPIO.input(echo)==0:
start = time.time()
while GPIO.input(echo)==1:
end = time.time()
travelTime = end - start
distance = travelTime * 17150
distance = round(distance, 2)
data = {'dist': distance}
producer.send("safety", value = data)
print "D = ", distance,"cm"
그리고, dist.py를 실행한다.
python dist.py
정상 실행되면 아래와 같은 데이터 출력을 확인할 수 있다. 같은 방식으로 카프카 CONSUMER에서 데이터를 확인할 수 있다.
부록: 별도 카프카 서버 구축, 라즈베리파이 IoT 센서 데이터 스트리밍 및 성능 테스트
카프카 환경 설정
무선이나 유선 네트워크가 가능한 환경에서, 별도 컴퓨터에 카프카를 앞의 내용을 참고해 설치한다. 시스템 구조는 다음과 같다.
카프카를 설치한 컴퓨터에, 앞서 설명한 server.properties 파일의 아래 내용을 해당 컴퓨터 IP주소에 맞게 수정한다.
listeners=PLAINTEXT://IP주소:9092
advertised.listeners=PLAINTEXT://IP주소:9092
주키퍼와 카프카 서버를 각각 터미널에서 실행한다.
c:\kafka\bin\windows\zookeeper-server-start.bat ../../config/zookeeper.properties
c:\kafka\bin\windows\kafka-server-start.bat ../../config/server.properties
센서 데이터 획득 및 빅데이터 생성 코딩
라즈베리파이에서 앞에 설명한 초음파 거리센서 예제를 참고해, 파이썬으로 다음과 같이 코딩한다. 카프카 서버 IP주소는 앞의 IP주소와 동일해야 한다.
from kafka import KafkaProducer
from json import dumps
import RPi.GPIO as gpio
import time
producer = KafkaProducer(bootstrap_servers=['카프카 컴퓨터 서버 IP주소:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8'))
gpio.setmode(gpio.BCM)
trig = 23
echo = 24
gpio.setup(trig, gpio.OUT)
gpio.setup(echo, gpio.IN)
index = 0
while True:
gpio.output(trig, 0) # 0.01초 마다 센서 데이터 생성 및 전송
time.sleep(0.01)
gpio.output(trig, 1)
time.sleep(0.00001)
gpio.output(trig, 0)
while gpio.input(echo) == 0:
start = time.time()
while gpio.input(echo) == 1:
end = time.time()
travelTime = end - start
distance = travelTime * 17150 # / 58.0
index = index + 1
data = {'dist': [index, distance]}
producer.send("IoT", value = data)
print index, 'D = ', round(distance, 2), 'cm'
코딩 후 이 파이썬 프로그램을 실행한다.
카프카 서버에서 consumer를 실행해 네트워크를 통해 데이터가 제대로 전달되는 지를 확인한다. 다음과 같이 카프카 서버와 라즈베리파에서 실행되면 성공한 것이다.
카프카 서버 실행 모습
라즈베리파이 센서 데이터 획득 및 카프카 서버에 센서 데이터 스트림 네트워크 전송 모습
카프카 데이터 스트리밍 성능 테스트
카프카 메시지 스트리밍 성능 테스트를 위해 센서 데이터 전송을 초당 100개로 설정해 다음과 같이 확인해 보았다.
라즈베리파이 센서 값
인터넷 네트워크 회선에 큰 문제가 없다면, 카프카 서버에서 실시간 수준으로 데이터 스트리밍 처리하는 것을 확인할 수 있다. 데이터 패킷 크기가 50 bytes 인 경우, 초당 5K가 처리되는 수준이다. 좀 더 부하를 주기위해 초당 1000개 토픽을 생성해 전송하였고, 이때도 큰 무리 없이 실시간 수준으로 스트리밍처리되었다. 이 경우, 초당 50K가 처리되는 수준이다.
좀 더 명확한 성능 측정을 위해서는 다음 링크의 성능 분석 매트릭스 및 데쉬보드 도구를 설치해 확인할 수 있다.
카프카 데이터 패킷 구조에 대해 궁금하다면 다음 링크를 참고한다.
부록: 카프카, 스파크, NoSQL 빅데이터 처리 아키텍처
카프카 서버에 전송된 데이터는 스트리밍되어 다른 어플리케이션이나 컴퓨터에서 고속으로 데이터를 전송받을 수 있다. 이 데이터를 Mongo DB같은 NoSQL DB에 저장하고, 스파크 등으로 빅데이터 분석을 수행할 수 있다. 이에 대한 내용은 아래를 참고한다.
다음은 이를 고려한 빅데이터 처리 아키텍처 예시이다.
부록: RPi 카메라 설치
라즈베리파이 카메라를 RPi와
연결하고, 다음과 같이 카메라 설정한다.
sudo raspi-config
UI메뉴에서 5번 setting interfaces, 1번 Setting camera 를 선택해 카메라를 활성화한다. 이제 다음 명령을 입력한다.
raspivid -o video.h264 -t 10000 -w 640 -h 480 -p 0,0,640,480
그럼 다음과 같이 카메라 화면이 나타난다.
파이썬 OPENCV를 이용해 객체 감지 후 해당 메시지를 앞에서 설명한 것과 같은 방식으로 카프카 메시지로 스트리밍 서비스할 수 있다.
부록: 라즈베리파이 기반 카프카 클러스터 서버 생성
주키퍼 설정
다음과 같이 주키퍼 클러스터 설정용 conf/zoo.cfg을 수정한다.
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/zookeeper # Don't put under /tmp, it will be deleted.
clientPort=2181
server.1=192.168.0.18:2888:3888
server.2=192.168.0.15:2888:3888
server.3=192.168.0.16:2888:3888
각 RPi의 /var/zookeeper 아래 myid 파일에 설정 파일을 복사한다.
그리고 zookeeper 루트 폴더아래 ./bin/zkServer.sh start 를 입력해 주키퍼 서비스를 시작한다. 주키퍼가 적절히 실행된다면, 다음처럼 프롬프트에 보일 것이다.
pi@raspberrypi-16:~/apache/zookeeper-3.4.11 $ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/pi/apache/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: follower # (or leader)
카프카 설정
주키퍼 클러스터가 실행 되고 있으면, 이제 아파치 카프카를 RPi에 배포한다.
다음 같이, config/server.properties 파일을 수정한다.
broker.id=1 # 1/2/3 for each card
port=9092
host.name=192.168.0.16 # IP address
zookeeper.connect=192.168.0.18:2181,192.168.0.15:2181,192.168.0.16:2181
bin/kafka-server-start.sh 를 갱신한다.
export JMX_PORT=${JMX_PORT:-9999}
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" # Otherwise, JVM would complain not able to allocate the specified memory.
bin/kafka-run-class.sh 를 갱신한다.
KAFKA_JVM_PERFORMANCE_OPTS="-client -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true" # change -server to -client
카프카를 시작한다.
./bin/kafka-server-start.sh config/server.properties &
카프카가 적절히 시작되고 있다면, 다음과 같이 다른 콘솔 터미널에서 producer 를 실행해 본다.
./bin/kafka-console-producer.sh — broker-list 192.168.0.15:9092,192.168.0.16:9092,192.168.0.18:9092 — topic v-topic # create a topic
./bin/kafka-console-producer.sh --broker-list 192.168.0.15:9092,192.168.0.16:9092,192.168.0.18:9092 --topic v-topic # kick off a producer
카프카 consumer를 실행한다.
./bin/kafka-console-consumer.sh — zookeeper 192.168.0.16 — topic v-topic from-beginning
P.S. 최근 천억 규모의 연구과제가 발주되었다. 사실 1억도 매우 큰 돈이다. 국가 연구과제가 이렇게 크면 누수가 많아지고, 인하우스 기술 개발보단 아웃소싱만 많아진다. 몇천만원이라도 10년을 꾸준하게 연구하고 싶은 사람이나 팀에게 지원해 주고 그 연구에만 몰입할 수 있는 환경을 준다면, 선진국 보유 핵심기술이라도 충분히 개발할 수 있다고 생각한다. 대형 설비가 필요해 큰 펀딩이 있어야 하는 경우를 제외한다면, 이런 펀딩은 핵심기술은 겨녕 아웃소싱 연구행정관리만 하다 아까운 시간 낭비할 수 있다. 홍보하기는 좋겠지만, 지속적이지 않고, 전문성은 더욱 떨어질 수 있다. 간만 보다 끝날 수 있다고 생각한다.