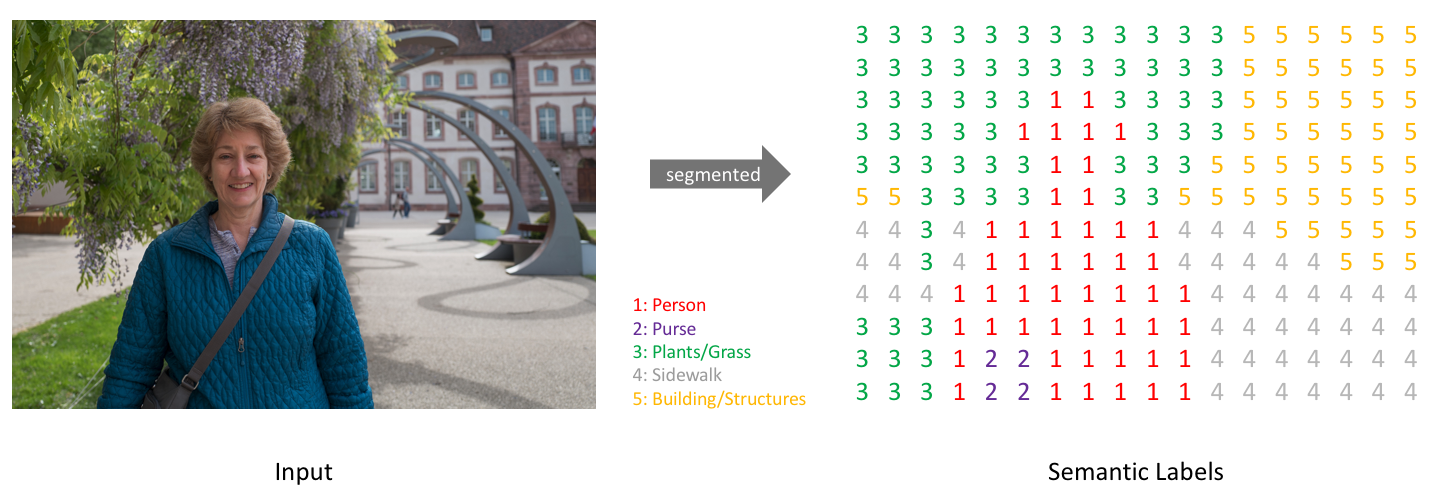
YOLACT++는 널리 알려진 물체 인식 기술인 YOLO에서 영감을 얻었으며, 실시간으로 빠르게 물체를 감지한다. DeepLab과 같이 객체 탐지와 달리 시맨틱 또는 인스턴스 세그먼테이션을 위한 대부분의 방법은 속도에 따른 성능에 중점을 두고 있다.
YOLACT가 인스턴스 세그먼테이션 문제를 해결하기 위해, 병렬로 실행되는 두 개의 작업 (프로토타입 마스크 딕셔너리 생성, 인스턴스 선형조합세트 예측)을 구분해 학습을 수행한다. 이를 통해 계산 시간을 크게 줄일 수 있다. YOLACT 모델은 ResNet50 모델에서 33.5 fps, 34.1 mAP로 높은 정확도와 예측 속도를 지원한다.
주요 객체 세그먼테이션 딥러닝 모델 성능(AP=Average Precision. FPS=Frame Per Second. NMS=Non-Maximum Suppression)
YOLACT 사용 방법
YOLACT 사용을 위해서는 미리 다음과 같은 개발환경이 구축되어 있어야 한다. 개발환경 구축은 많은 시행착오가 필요하다. 딥러닝 개발환경 구축과 관련해 이전 글 #1, #2, #3, #4을 참고 바란다.
다음 명령을 통해 데이터셋을 학습한다. batch_size 하나당 1.5GB GPU 메모리가 필요하고, 이 크기가 클수록 빠른 속도로 훈련이 가능하다. nvidia-smi 명령을 통해 GPU 메모리 크기를 확인하고 이 숫자를 정하자. 세그먼테이션 데이터 훈련을 위해서는 최소 4GB 이상 GPU 카드가 필요하다. 이 이하는 학습 속도나 품질에 문제가 있다.
참고로, 세그면테이션 데이터 훈련 시간은 기존 객체 인식 훈련에 비해 매우 오래 걸린다. 164,000개의 이미지를 가지고 있는 COCO의 세그먼테이션 데이터의 경우, 전이학습을 사용하지 않으면, 일주일이상이 걸릴 수 있다. 이 경우에는 딥러닝 데이터 모델 훈련에 대략 이틀이 걸렸다.
이제 아래와 같이 평가 테스트를 실행해 보자.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --output_coco_json
python run_coco_eval.py
python eval.py --trained_model=weights/yolact_base_54_800000.pth --output_coco_json --dataset=coco2017_testdev_dataset
다음 명령으로 이미지에서 객체 세그먼테이션을 해본다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --image=input_image.png:output_image.png
특정 폴더 내 이미지를 세그먼테이션하려면 아래 명령을 입력한다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --images=path/to/input/folder:path/to/output/folder
다음은 이미지 세그먼테이션 결과이다.
다음 명령으로 비디오 내 객체 세그먼테이션을 처리해 본다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=my_video.mp4
다음과 같이 비디오 이미지도 객체 세그먼테이션이 잘 실행된다. 다만, 일부 객체들이 사람이나 보트같은 것으로 구분되는 문제가 있다. 이는 전이학습을 통해 해결할 수 있어 보인다.
웹캡은 다음 명령으로 처리할 수 있다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=0
웹캡에서 처리된 객체 세그먼테이션 결과는 다음 명령으로 영상 저장이 가능하다.
python eval.py --trained_model=weights/yolact_base_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=4 --video=input_video.mp4:output_video.mp4
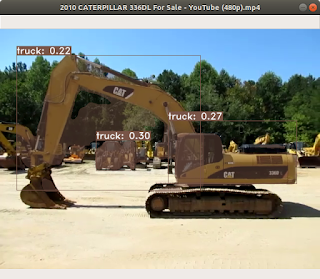
다음은 건설 객체가 얼마나 잘 인식되는 지 확인해본 YOLACT 실행 영상이다.
YOLACT 기반 객체 세그먼테이션 처리 영상
건설 객체의 세그먼트를 학습하지 않은 상태이므로, 오탐되는 경우가 발생한다. 앞서 언급했듯이 학습 데이터를 확보해 진행하면, 해당 이슈는 해결할 수 있다. 하지만, 세그먼테이션을 위해 학습 데이터를 확보하고 라벨링하는 것이 쉽지 않은 문제가 있다. 라벨링 방법은 다음 링크를 참고한다.
지금까지 YOLACT 모델을 이용한 객체 세그먼테이션 방법을 소개하고, 이를 이용해 이미지, 비디오 등에서 객체를 세그먼테이션해 보았다. 세그먼테이션은 다른 딥러닝 모델에 비해 많은 정보를 담고 있어 유용하다.
다만, 세그먼테이션은 클래스 분류, 객체 탐지에 비해 많은 계산 비용과 학습 노력이 필요하다. 학습을 위해서는 고사양의 GPU가 장착된 컴퓨터가 필요하며, 데이터셋 구축도 많은 노력이 필요하다. 실행 속도도 상대적으로 느리므로, 특정 영역경계를 정확히 찾아내야 하는 문제가 아니라면, 단순히 분류하거나 객체 탐지할 때 굳이 사용할 필요는 없을 것이다.
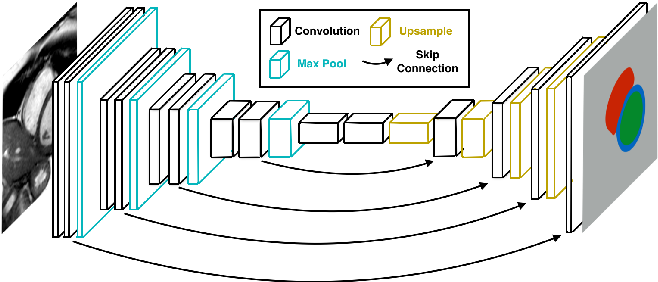
DeepLab은 2017년에 발표된 시멘틱 세그먼테이션 모델이다. 이 모델은 세그먼테이션을 위해 atrous convolution 기법을 사용한다. atrous는 hole을 의미한다. 이는 기존 컨볼루션과 다르게 필터 내부에 빈 공간을 두고 가중치를 조정하게 된다. 이를 통해 한 픽셀이 볼 수 있는 영역(field of view)을 크게 할 수 있다.
atorus convolution filter(DeepLab)
세그먼테이션은 한 픽셀의 입력값에서 어느 수준의 영역을 커버할 수 있는 지에 대한 receptive field 크기가 중요하다. atorus 구조를 통해 한 픽셀에 대한 세그먼테이션 성능과 처리 속도를 모두 개선할 수 있다.
atorus network(DeepLab)
DeepLab은 계속 발전하고 있으며, v3에서는 ResNet을 백본(backbone)으로 사용하였다.
DeepLab architecture
이제 COCO 데이터셋으로 학습한 DeepLab 모델이 실내 오피스 이미지가 얼마나 잘 인식되는 지 확인해 보겠다. 실행은 아래 CoLab에서 확인한다.
YOLACT(You Only Look At CoefficienTs)은 캘리포니아 대학교 (University of California)의 연구그룹이 2019년도 발표한 실시간 객체 세그먼테이션 기술이다. 다음은 이를 이용한 객체 세그먼테이션 결과이다. 이 모델은 ResNet50 에서 33.5 fps, 34.1 mAP로 높은 정확도와 예측 속도를 지원한다.
딥러닝 모델에서 이미지 객체를 탐지하고, 세그먼테이션하는 기법은 인공지능 전문가 그룹에 의해 큰 성과를 얻었고, 대부분의 경우 이러한 모델을 바탕으로 어플리케이션을 개발하는 것이 추세가 되었다. 이런 이유로, 초창기 이미지넷과 같은 대회는 딥러닝 모델 자체를 개발하는 데 촛점을 두었지만, 현재는 기존에 개발된 딥러닝 모델을 이용해 응용 목적 달성도를 경쟁하는 방식이 대부분이 되었다.
아직 몇몇 특수한 분야(3차원 포인트 클라우드 스캔 분야 등)에서는 품질과 성능이 원하는 수준까지 얻지 못하고 있지만, 이 부분도 GPU와 같은 하드웨어가 발전하고 있으므로 몇년내에 좋은 딥러닝 모델이 나오리라 생각한다.
이 글에서는 실내 객체 탐지를 위해 딥러닝 모델을 사용한 사례를 간략히 나열한다. 실내는 많은 작은 객체들이 오버랩되어 있는 특징이 있다. 그래서, 실내에 있는 모든 객체를 탐지하는 것 보다는 테이블과 같은 주요 객체를 탐지하는 사례가 대부분이다. 아울러, 배경이 되는 바닥과 벽체같은 부분은 세그먼테이션 기법을 사용하거나, 알고리즘 기반 탐색 기법을 사용하는 것이 더 유리하다.
실내 객체 탐지 딥러닝 모델 사례
실내 객체 탐지를 위해서는 의자, 테이블, 벽, 천정, 바닥과 같은 이미지 영역을 라벨링하고, 학습을 시켜야 한다. 만약, 응용 대상의 데이터 특성이 특수하지 않다면, 기존 개발된 실내 객체 탐지용 딥러닝 모델을 사용해도 무방할 것이다.
이 글은 YOLO v3 기반 시멘틱 객체 라벨링, 훈련 및 인식 기술 개발 방법을 간단히 다룬다. 참고로, YOLO v3는 이전 버전 욜로에 비해 정확도는 높아졌고, 속도는 다소 낮아 졌다. 이 글에서는 YOLO를 이용해 다음과 같이 건설 객체를 인식할 수 있는 딥러닝 모델을 개발해 본다.
건설 객체 탐지 딥러닝 모델 결과
YOLO 개요
본 내용은 이미 다크넷 및 YOLO 개발 환경이 구축되었다고 가정하고 진행한다. YOLO 개발환경이 준비되지 않았다면 아래 링크를 참고한다.
YOLO의 예측 결과는 클래스 별로 예측된 경계박스(anchor box={cx, cy, width, height})이다. 이 경계박스를 다음 그림과 같이 클래스별로 입력된 학습데이터에 맞게 조정해 학습모델을 만든다.
그러므로, YOLO의 학습 모델은 train data={image, {anchor box, label}*} 가 입력되고, 출력으로 output={anchor box, objectness score, class scores}* 가 된다(*=multiple). 이는 이미지를 격자화해, 3개의 aspect ratio별 anchor box로 출력되는 데, 이 결과로 COCO데이터셋 80개 클래스 경우 각 격자(cell)마다 depth 방향으로 (4 + 1 + 80) * 3 = 255 개 depth가 쌓이게 된다.
경계박스 정의
이미지 별 격자 크기는 13x13, 26x26, 52x52인 3가지 종류로 나뉜다. 다음 그림은 이를 보여준다.
모델 구조 재활용
앞서 설명한 부분을 제외한 나머지 부분은 기존에 개발된 CNN(Convolutional Neural Network), FCN(Fully Convolutional Network), ResNet 등을 재활용한다.
일반적으로 활용되는 ResNet은 네트워크의 깊은 깊이로 인한 gradient vanishing/exploding 문제로 Degradation되는 현상을 피하기 위해, 개발된 것이다. 만약, 신경망 학습목적이 입력 x를 목적값 y로 맵핑하는 함수 H(x)를 탐색하는 것이라면, 학습방향은 H(x) − y를 최소화하는 것이다. ResNet에서는 관점을 바꿔 H(x) − x를 탐색하도록 수정한다. 입출력 잔차를 F(x) = H(x) − x로 정의를 하고 학습은 이 F(x)를 탐색한다. 이 F(x)가 잔차이므로, 이를 Residual learning, Residual mapping라 한다. 계산 상으로는 단순히 F(x) + x를 한 것으로 그 전 레이어 값을 더하고 relu연산 적용한 것 뿐인데 이런 문제를 개선해 높은 성능을 얻었다.
ResNet 핵심 구조(좌=기존. 우=ResNet)
Up-sampling은 저해상도에서 고해상도로 이미지 스케일 업할 때 사용된다. 이는 보간법과 유사한 방식으로, Transpose convolution, Deconvolution으로 불린다.
최종 YOLO 모델 구조
이런 입출력을 고려해 CNN 레이어를 개발하면, 다음과 같은 YOLO 딥러닝 모델이 된다.
./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
제대로 수행되면, 다음 단계에서 YOLO v3 기반 예측 모델을 개발해 보겠다.
딥러닝 기반 예측 모델 개발 순서
딥러닝 모델을 학습하고, 이를 통해 사용자 데이터에서 객체 예측 모델을 개발하는 순서는 다음과 같다.
이 글에서 딥러닝 모델 사용 목적은 건설 객체 중 건설장비와 작업자를 인식하는 것이다. 딥러닝 모델은 YOLO v3로 선정하였고, 전이학습을 사용한다. 이후 과정은 다음과 같다.
학습 데이터 준비
딥러닝의 가장 큰 장애물은 학습 데이터를 준비하는 것이다. 지금까지 딥러닝 연구자들의 많은 노력으로 수많은 딥러닝 모델이 이미 개발되어 있다. 잘 활용하면 되는 좋은 모델이 많다. 하지만, 각자 응용 영역에 적용할 수 있는 데이터는 매우 제한되어 있다.
딥러닝에서는 데이터가 소스코드나 마찬가지이므로, 학습용 데이터 확보가 매우 중요하다. 하지만, 학습 데이타를 만들기 위해서는 매우 노동집약적인 작업이 필요하다. 참고로, DQN(Deep Q-Networks)와 같은 강화학습(reinforcement learning)을 사용할 수도 있다. 하지만, 강화학습은 일정 규칙을 추출할 수 있어 바둑과 같이 학습 데이터 생성을 예상할 수 있는 문제에서 적용이 가능한 방법이다.
본 글에서는 학습 데이터를 건설 중장비 이미지를 준비해 본다. 그리고, CNN 기반 딥러닝 모델을 학습해 본다.
이미지 준비를 위해 구글에서 이미지를 다운로드하는 프로그램을 다음과 같이 설치하고, 실행한다. 이 작업을 위해서는 미리 아나콘다 개발 환경이 준비되어 있어야 한다(설치 방법 참고).
chromedriver.chromium.org/downloads 에서 구글 크롬 드라이버를 다운로드 받는다. 압축을 풀어 chromedriver.exe 파일을 얻는다. 만약, 리눅스라면, 다음과 같이 크롬을 설치한 후 리눅스용 chromedriver를 다운로드 받아야 한다. $ wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb $ sudo dpkg -i google-chrome-stable_current_amd64.deb
참고로, 이 도구는 최신 파이썬에서는 호환성 에러가 발생한다. 이 경우 에러를 수정해 사용하거나, 여기에 이미 수정한 소스를 다운로드 받아 사용한다.
라벨링 도구 에러 수정
이 도구를 이용해 각 이미지 별 경계 박스 설정 시 시간은 평균 1~10초 정도 걸린다. 한 장당 평균 2~5개의 경계박스를 선택해야 한다. 실제, 미리 준비한 중장비 이미지 데이터는 446장이었고, 이 데이터는 라벨링에 약 50분 시간이 소요되었다. 이 경우, 라벨링 속도는 10장/분이고, 6초당 1장 라벨링 속도이다. 실제 50분 가까이 라벨링하면, 손과 눈에 급격한 피로도가 몰린다(법정교육 동영상 클릭 노가다하는 느낌 -.-). 그래서 대략 10분 정도를 쉬면서 라벨링하였다. 참고로, 이미지 별 클래스 개수와 라벨 난이도에 따라 이 시간은 크게 달라질 수 있다.
중장비 라벨링 과정
건설 작업자의 경우, 450장 라벨링하는 데, 60분이 소모되었다. 이는 7.5장/분 속도로 라벨링한 것이다. 꽤 많은 수의 데이터임에도 불구하고, 다양한 각도와 거리에서 촬영한 이미지 데이터는 부족한 편이다.
작업자 라벨링 과정
객체 대상에 따라 라벨링 작업 특성이 다를 수 있다. 예를 들어, 사람은 장비보다 겹치는 경우가 많다. 중장비의 경우 객체 대상을 본체만으로 하는 지, 부착장비까지로 하는 지에 따라 선택 범위가 달라진다.
라벨링된 결과는 Labels 폴더에 각 파일명별로 다음과 같이 기록된다.
라벨 파일 폴더
라벨 파일 데이터 구조
라벨 데이터 형식 변환 및 학습 파라메터 설정
이제 라벨 데이터 파일들을 darknet 형식으로 변환해야 한다. 참고로, 딥러닝 모델 학습시 사용하는 포맷 세부 내용은 다음 링크를 참고한다.
custom_data 폴더 내 다른 파일들 역할은 다음과 같다.
custom.name = class names
detector.data = 훈련용 데이터 파일 설정 정보
test.txt = 테스트용 파일 리스트
train.txt = 훈련용 파일 리스트
학습 파라메터를 담고 있는 detector.data 파일 구조는 다음과 같다.
classes=2
train=custom_data/train.txt
valid=custom_data/test.txt
names=custom_data/custom.names
backup=backup/
이 라벨 데이터셋의 경우에는 클래스가 2개 밖에 없지만, 이를 추가하고 싶다면, 앞에서 설명한 부분을 수정해야 한다. 이는 스크립트에서 다음 부분을 수정하면 자동 생성 된다.
# Modify the below parametercategoryCount = 2names = ['con_eq', 'worker']
사용자 데이터셋 딥러닝 학습
이제 사용자가 만든 데이터셋으로 욜로를 학습해 보자. 이를 위해, 클래스와 관련된 부분의 욜로 학습 설정 파일을 수정해야한다.
다크넷의 cfg/yolov3.cfg 를 custom_data/cfg/yolov3-custom.cfg 으로 복사한다.
그리고, yolov3-custom.cfg에서 아래 부분을 수정, 저장한다. 아래 글에서 () 안은 주석이다.
filters=21 (at line number 603, 689, 776. filters=(classes + 5) * 3)
학습은 다음 명령을 이용한다. 데이터셋 크기가 1,000개 미만이므로 전이학습(transfer learning) 기법을 사용한다.
./darknet detector train [.data file location] [.cfg file location] [pretrain weight model file]
참고로 학습전에 사전 학습된 darknet53.conv.74 모델 파일을 사용하면 학습분포가 많아지고, 학습시간도 단축된다. 이런 방법을 전이학습기법이라 한다.
전이학습은 새로운 모델로 학습할 때보다 이미지 분포가 더 크기 때문에 효율적 학습이 가능하다. 전이학습은 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델이다. 일반적으로, 큰 데이터셋으로 모델을 학습하는 것은 오랜 계산 시간과 연산량이 필요하므로, 보통 VGG, Inception, MobileNet 등 이미 잘 학습되어 있는 모델들을 가져와 사용한다(참고로, VGG, Inception같은 ConvNets 학습은 보통 다중 GPU 하에서도 2~3주 걸린다).
여기서 사용하는 darknet53.conv.74 은 이미지넷 데이터셋을 darknet으로 학습한 모델이다. 이 데이터셋은 본 건설 객체와 일부 유사한 객체들이 학습되어 있다. 다만, 본 데이터셋과 fitting되어야 제대로 학습할 수 있다. 전이학습에서는 이 모델을 backbone으로 사용한다(참고 - 차이점).
학습을 위해 다음과 같이 실행한다. 만약, 사전학습 모델을 사용하지 않는다면, 해당 파일명은 입력하지 않는다.
./darknet detector train custom_data/detector.data custom_data/cfg/yolov3-custom.cfg darknet53.conv.74
실행 결과, 다음과 같이 학습이 진행될 것이다. 이 로그는 각 이미지의 학습 상황을 알려준다. Region 82, 94, 106 은 학습 마스크 크기를 말한다. 마스크 크기가 클수록 작은 객체를 예측 가능하다. IOU 는 서브디비전에서 실제와 예측된 경계박스의 교차율을 뜻하며, 1에 가까울수록 좋다. 클래스 값은 1에 가까울 수록 학습이 잘되고 있다는 의미이다. No Obj 는 작은 값일 수록 좋다.
count=positive classes 를 의미한다. .5R, .75R는 recall/count를 의미한다. Recall, IoU, Precision의미는 다음 그림을 참고하라.
이 사례에서는 학습 시간이 대략 12시간 30분 걸렸다(i7. GTX 1070 8G. 16G). 생성된 학습 모델 크기는 346.3MB이다(Model Download).
객체 예측모델 학습결과 객체탐지 정확도 테스트
학습이 끝났으면, 테스트를 해 보자.
우선 비교를 위해, 기존 yolov3.weight 모델로 예측해 본다. 다음 그림과 같이 아무것도 인식되지 않는다.
./darknet detect cfg/yolov3.cfg yolov3.weights custom_data/images/con_eq_65.jpg
다음과 같이 학습된 모델 파일을 이용해 이미지를 예측해 보자. 결과와 같이 잘 예측된다. 커스텀된 학습 모델이 훨씬 높은 인식률을 보이고 있는 것을 알 수 있다.
./darknet detector test custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights ./custom_data/images/con_eq_65.jpg
각 객체의 탐지 정확도는 89%, 87%,78%로 높은 편이다.
다른 이미지도 인식해 본자. 기존 yolov3.weight 모델로 인식한 결과는 다음과 같다. 객체 4개만 인식되고 1개는 오탐되었다.
다음과 같이, 새로 학습한 모델로 테스트해본다. 모두 제대로 인식된다. 기존보다는 직접 학습한 custom weight 모델 결과가 더 나은 것을 확인할 수 있다.
./darknet detector test custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights ./custom_data/images/con_worker_392.jpg
다음은 웹캠으로 학습된 중장비, 작업자를 인식해본 결과이다. 해상도가 그리 좋지 못함에도 잘 인식된다. 다만, YOLO v2 보다 속도가 느리다(v3가 체감상 2배 이상이 느리나, 정확도는 더 높다).
참고로, 미리 준비된 동영상으로 테스트하고 싶다면, 다음처럼 명령을 입력해 보자.
./darknet detector demo custom_data/detector.data custom_data/cfg/yolov3-custom.cfg yolov3-custom_final.weights test7.MOV
다음은 건설 현장 영상을 학습된 모델에 입력해 객체를 인식한 결과이다. 학습 데이터에 전혀 없는 Top view 등은 인식이 잘 되지 않지만, 비슷한 각도의 이미지들은 잘 인식되는 것을 알 수 있다.
이제 잘 인식되지 않는 부분을 확인하였으니, 이를 보완해 모델을 개선해 본다. 다음은 개선된 모델을 이용해 객체를 인식한 결과이다. 훈련한 건설 장비 객체 탐색이 잘 되는 것을 알 수 있다.
마무리
지금까지 사용자가 학습 데이터를 준비하고 학습 시켜야 할 때 욜로에서 어떻게 작업하는 지 전체적인 프로세스를 나눔해 보았다. 기존 욜로의 학습 모델로는 건설과 같이 특정한 분야에 대한 객체 인식은 제대로 되지 않는다. 이 경우, 별도 학습 데이터를 준비해 딥러닝 훈련 시켜야 한다. 학습 데이터가 부족한 경우, 정확도가 높아지지 않는다. 이 사례에서는 학습 데이터가 많은 편은 아니다. 다만, 객체 인식에 큰 문제가 없는 수준으로 학습 데이터를 구축하고 훈련을 진행해서, 큰 문제 없이 테스트에서 건설 객체들이 학습되는 것을 확인할 수 있었다. 학습 데이터가 많아지고, 클래스 수가 높아질수록 데이터 준비 및 학습에 많은 노력과 시간이 들어간다.
당연한 말이지만, 이렇게 학습된 커스텀 모델은 해당 분야 데이터에서만 유효하다. 이를 고려해, 딥러닝에 필요한 데이터셋, 학습모델 등을 활용해야 한다.