이 글은 어텐션(Attention) 기반 트랜스포머(Transformer) 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법을 소개을 공유한다. 트랜스포머는 BERT(Bidirectional Encoder Representations from Transformers), GPT-3 등의 기반이 되는 기술이다.
트랜스포머를 이용하면, 기존 RNN, LSTM, CNN, GCN가 지역적 특징을 바탕으로 데이터를 학습 및 예측하는 한계를 해결할 수 있다. 트랜스포머는 셀프 어텐션을 포함하여, 전체 데이터셋을 순서에 관계없이 학습 과정에 포함시켜, 가중치를 계산하므로, 좀 더 높은 정확도의 학습 모델을 개발할 수 있다.
트랜스포머 모델 개념
논문 'Attention Is All You Need'는 트랜스포머 개념과 시퀀스-투-시퀀스 아키텍처에 대해 설명한다. Sequence-to-Sequence(Seq2Seq)는 문장의 단어 시퀀스와 같은 주어진 시퀀스를 다른 시퀀스로 변환하는 신경망이다.

Seq2Seq 모델은 한 언어의 단어 시퀀스가 다른 언어의 다른 단어 시퀀스로 변환되는 번역에 특히 좋다. 이 유형의 모델에 널리 사용되는 LSTM(장단기 메모리)은 시퀀스에 의미를 부여할 수 있다. 예를 들어 문장은 단어의 순서가 문장을 이해하는 데 중요하기 때문에 순서에 따른 의미를 훈련시킬 수 있다.
LSTM 이상패턴 사용 예시
Seq2Seq 모델은 인코더와 디코더로 구성된다. 인코더는 입력 시퀀스를 가져와 더 높은 차원 공간(n차원 벡터)에 매핑한다. 출력 시퀀스는 다른 언어, 기호, 입력 사본 등일 수 있다.
'Attention Is All You Need'라는 논문은 Transformer라는 아키텍처를 소개한다. LSTM과 마찬가지로 Transformer는 두 부분(Encoder 및 Decoder)으로 한 시퀀스를 다른 시퀀스로 변환하는 아키텍처이지만, RNN(Recurrent Neural Networks) 없이 어텐션(Attention. 주의) 메커니즘만 있는 아키텍처로 성능을 개선할 수 있음을 증명했다. 어텐션은 앞에서 입력된 글이 그 다음의 단어를 결정할 때, 어떤 단어가 출력되어야 하는 지를 수학적으로 계산할 수 있다.
어텐션 매커니즘
트랜스포머 모델의 인코더는 왼쪽에 있고 디코더는 오른쪽에 있다. Encoder와 Decoder는 모두 여러 번 서로 겹쳐질 수 있는 모듈로 구성된다. 입력 데이터는 토큰(예. 자연어 텍스트)으로 분리된 후, 행렬 텐서 계산을 위해, 토큰을 숫자로 변환한 임베딩 텐서를 계산한다.

텍스트-임베딩 텐서 변환 예시(Word2Vec)
텍스트의 경우, 토큰은 각자 순서가 있으므로, 위치 정보를 학습에 포함하기 위해, 포지션 인코딩한 결과를 임베딩 텐서에 더한다. 이제, 그 결과를 Multi-Head Attention 및 Feed Forward를 수행해 어텐션을 계산하고, ResNet과 같이 신경망 앞 부분의 가중치가 소실되지 않도록 더해주고 정규화(Add & Norma)시킨다.
한편, 라벨링된 출력은 자연어에서 보았을 때는 텍스트가 한 토큰(단어)씩 우측 쉬프트된 것과 같다. 이를 함께 학습과정에서 고려해 주어야, 손실을 계산하고, 전체 신경망의 weight 행렬을 업데이트할 수 있다. 손실을 계산해 주는 부분은 Multi-Head Attention을 통해 계산하고, 그 결과 텐서를 linear한후 softmax로 처리해, 다음에 올 토큰의 확률을 얻는다.

트랜스포머 아키텍처
이런 이유로, 트랜스포머의 구성은 주로 Multi-Head Attention 및 Feed Forward 레이어로 되어 있다. 언급한 바와 같이, 문자열을 직접 사용할 수 없기 때문에 입력과 출력(목표 문장)은 먼저 임베딩 기법으로 수치화된 후 n차원 공간에 매핑된다.

이 결과, 모델의 전체 실행 순서 예는 다음과 같다.
- 전체 인코더 시퀀스(예. 프랑스어 문장)를 입력하고 디코더 입력으로, 첫 번째 위치에 문장 시작 토큰만 있는 빈 시퀀스를 사용한다.
- 해당 요소는 디코더 입력 시퀀스의 두 번째 위치에 채워지며, 문장 시작 토큰과 첫 번째 단어/문자가 들어 있다.
- 인코더 시퀀스와 새 디코더 시퀀스를 모두 모델에 입력한다. 출력의 두 번째 요소를 가져와 디코더 입력 시퀀스에 넣는다.
- 번역의 끝을 표시하는 문장 끝 토큰을 예측할 때까지 이 작업을 반복한다.
다음은 이 과정을 계산한다.
어텐션(주의 집중) 내부 메커니즘
트랜스포머에 사용된 Mult-Head Attention은 손실 함수에 영향을 주는 값을 계산하는 역할을 한다. 토큰을 인코더에 입력해서 계산된 특징벡터 텐서와 예측되어야 할 토큰의 특징벡터를 내적해 계산한다. 그 결과, 가중치가 고려된 텐서 행렬이 된다.

입력 토큰에 대한 어텐션 토큰 예시
이를 좀 더 자세히 살펴보면, 다중 헤더 어텐션은 학습되어야할 모델 텍스트 데이터의 어느 부분에 초점을 맞춰야 하는지를 학습한다. Mult-Head Attention은 앞서 차례대로 입력된 임베딩+포지션 벡터를 n차원 Query, n차원 Key, Value 벡터로 분리해, 학습을 시켜 어텐션 텐서 행렬을 구한다. 만약, 'the quick brown fox jumped' 문장이 있고, 이를 프랑스어 le renard brun rapide a sauté로 변환한다면, 키 행렬에서 개별 단어 토큰에 대한 가중치를 학습하고, 쿼리 행렬은 실제 입력 단어로 표현할 수 있다. 쿼리와 키 행렬의 내적을 구하면, 다음처럼 self-attention (자체 주의. 두 행렬의 유사도 값이 계산됨) 텐서를 얻을 수 있다.

셀프 어텐션의 계산 결과는 질의와 키 메트릭스 간 유사도 점수 매트릭스가 됨
이 텐서값은 차원수의 제곱근으로 나누어 정규화된다. 그 결과를 소프트맥스 함수에 입력해, 질의된 예측 토큰의 확률값을 얻을 수 있다. 그러므로, 어텐션 블럭의 함수식은 다음과 같이 표현할 수 있다.


Multi-head attention(2021, Hadamard Attentions: The Mighty Attentions Optimized)
동작 과정 설명
포지션 인코딩 동작 방식
포지션 인코딩은 입력 데이터의 순서를 기억할 수 있는 순환 네트워크가 없기 때문에, 시퀀스의 모든 단어/부분에 상대적인 위치를 계산하는 방식이다. 이러한 위치는 각 단어의 포함된 표현(n차원 벡터)에 추가된다. 보통, 이 방식은 다음의 sin, cos함수를 통해 토큰이 텍스트에서 사용된 i번째 위치 벡터를 계산한다.
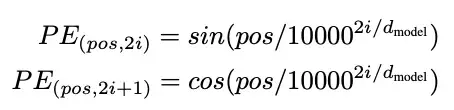
포지션 인코딩 함수
사용 예시
사용 예시를 간단히 확인해 본다. 이를 위해 아래 링크를 참고하도록 한다.
- Text Transformer: BERT, GPT-3같은 문서 종류 분류, 번역, 작문, 챗봇, 주가예측, 작사 등


- Vision Transformer (ViT): 객체 분류, 탐지, 세그먼테이션, 텍스트 캡션 생성 등


SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
- Point cloud Transformer (PCT): 점군 생성, 분류, 세그먼테이션 등

PCT using BERT(Bidirectional Encoder Representations from Transformers)
사용 방법
파이토치 등 유명한 딥러닝 라이브러리는 이미 트랜스포머 모듈을 구현해 두고 있다. 이를 이용해, 예측, 분류, 세그먼테이션 등을 다양한 데이터셋(텍스트, 이미지, 점군, 기하 벡터 등)에 대해 수행할 수 있다.
이 예제의 목표는 다음과 같은 입력에 대한 출력을 예측하는 것이다. 참고로, 데이터의 종류는 텍스트이지만, 수치화할 수 있다면, 이미지, 소리 등 종류에 구애받지 않는다.

이 예제는 학습 데이터를 Wikitext-2(https://github.com/pytorch/data)를 사용한다. 미리 다운로드 받아 둔다. 어휘의 토큰은 센서로 수치화되어 학습될 것이다. 이 텍스트 시퀀스는 batchify()란 함수에 의해, batch_size 수의 컬럼으로 변환된다. 예를 들어, 26개 알파벳 시퀀스를 batch_size=4로 정의할 때 다음과 같은 6개의 4개의 시퀀스로 변환된다.

파이토치 구현 코드는 다음과 같다.
import math
from typing import Tuple
import torch
from torch import nn, Tensor
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer # 트랜스포머 모듈
from torch.utils.data import dataset
class TransformerModel(nn.Module):
def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int,
nlayers: int, dropout: float = 0.5):
super().__init__()
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(d_model, dropout) # 포지션 인코딩
encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout) # 트랜스포머 인코딩 레이어
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers) # 트랜스포머 레이어
self.encoder = nn.Embedding(ntoken, d_model) # 임베딩
self.d_model = d_model
self.decoder = nn.Linear(d_model, ntoken)
self.init_weights()
def init_weights(self) -> None:
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src: Tensor, src_mask: Tensor) -> Tensor:
"""
Args:
src: Tensor, shape [seq_len, batch_size]
src_mask: Tensor, shape [seq_len, seq_len]
Returns:
output Tensor of shape [seq_len, batch_size, ntoken]
"""
src = self.encoder(src) * math.sqrt(self.d_model) # 임베딩 x 어텐션
src = self.pos_encoder(src) # 위치인코딩
output = self.transformer_encoder(src, src_mask) # 트랜스포머
output = self.decoder(output) # linear
return output
def generate_square_subsequent_mask(sz: int) -> Tensor: # 어텐션 마스크 처리
"""Generates an upper-triangular matrix of -inf, with zeros on diag."""
return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)
포지션 인코딩은 다음과 같다.
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x: Tensor, shape [seq_len, batch_size, embedding_dim]
"""
x = x + self.pe[:x.size(0)]
return self.dropout(x)
입력 텍스트를 배치 단위로 변환하는 코드는 다음과 같다.
from torchtext.datasets import WikiText2 # 학습 데이터
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
train_iter = WikiText2(split='train')
tokenizer = get_tokenizer('basic_english') # 기본영어 텍스트에서 토큰 획득
vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>'])
vocab.set_default_index(vocab['<unk>'])
def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor:
# 입력 텍스트를 토큰화해 수치 텐서로 변환함
data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
# 학습, 검증 및 테스트 데이터를 텐서로 변환
# so we have to create it again
train_iter, val_iter, test_iter = WikiText2()
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batchify(data: Tensor, bsz: int) -> Tensor:
# 주어진 배치개수 만큼 배치 데이터 생성
seq_len = data.size(0) // bsz
data = data[:seq_len * bsz]
data = data.view(bsz, seq_len).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size) # 배치데이터 생성. shape [seq_len, batch_size]
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
이제, 입력에 대한 출력(라벨) 데이터를 생성한다.
bptt = 35
def get_batch(source: Tensor, i: int) -> Tuple[Tensor, Tensor]:
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].reshape(-1)
return data, target
이제 하이퍼파라메터를 조정한다.
ntokens = len(vocab) # 단어 사전(어휘집)의 크기
emsize = 200 # 임베딩 차원
d_hid = 200 # nn.TransformerEncoder 에서 피드포워드 네트워크(feedforward network) 모델의 차원
nlayers = 2 # nn.TransformerEncoder 내부의 nn.TransformerEncoderLayer 개수
nhead = 2 # nn.MultiheadAttention의 헤드 개수
dropout = 0.2 # 드랍아웃(dropout) 확률
model = TransformerModel(ntokens, emsize, nhead, d_hid, nlayers, dropout).to(device)
모델을 학습한다. 손실함수는 CrossEntropyLoss로 SGD 함수를 사용하고, step learning rate를 설정하며, nn.utils.clip_grad_norm_ 함수를 사용해 기울이가 발산하지 않도록 한다.
import copy
import time
criterion = nn.CrossEntropyLoss()
lr = 5.0 # 학습률(learning rate)
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
def train(model: nn.Module) -> None:
model.train() # 학습 모드 시작
total_loss = 0.
log_interval = 200
start_time = time.time()
src_mask = generate_square_subsequent_mask(bptt).to(device)
num_batches = len(train_data) // bptt
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
seq_len = data.size(0)
if seq_len != bptt: # 마지막 배치에만 적용
src_mask = src_mask[:seq_len, :seq_len]
output = model(data, src_mask)
loss = criterion(output.view(-1, ntokens), targets) # 손실함수 계산
optimizer.zero_grad()
loss.backward() # 가중치 업데이트
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
if batch % log_interval == 0 and batch > 0:
lr = scheduler.get_last_lr()[0]
ms_per_batch = (time.time() - start_time) * 1000 / log_interval
cur_loss = total_loss / log_interval
ppl = math.exp(cur_loss)
print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | '
f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | '
f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}')
total_loss = 0
start_time = time.time()
def evaluate(model: nn.Module, eval_data: Tensor) -> float:
model.eval() # 평가 모드 시작
total_loss = 0.
src_mask = generate_square_subsequent_mask(bptt).to(device)
with torch.no_grad():
for i in range(0, eval_data.size(0) - 1, bptt):
data, targets = get_batch(eval_data, i)
seq_len = data.size(0)
if seq_len != bptt:
src_mask = src_mask[:seq_len, :seq_len]
output = model(data, src_mask)
output_flat = output.view(-1, ntokens)
total_loss += seq_len * criterion(output_flat, targets).item()
return total_loss / (len(eval_data) - 1)
이제 Epoch 마다 학습 및 평가를 수행하는 train(), evaluate()함수를 호출한다.
best_val_loss = float('inf')
epochs = 3
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(model)
val_loss = evaluate(model, val_data)
val_ppl = math.exp(val_loss)
elapsed = time.time() - epoch_start_time
print('-' * 89)
print(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | '
f'valid loss {val_loss:5.2f} | valid ppl {val_ppl:8.2f}')
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = copy.deepcopy(model)
scheduler.step()
그 결과는 다음과 같다.


학습 결과를 다음 코드로 평가한다.
test_loss = evaluate(best_model, test_data)
test_ppl = math.exp(test_loss)
print('=' * 89)
print(f'| End of training | test loss {test_loss:5.2f} | '
f'test ppl {test_ppl:8.2f}')
print('=' * 89)
마무리
트랜스포머의 어텐션 메커니즘을 응용하면, 학습 데이터의 전역적인 특징을 고려한, 데이터 분류, 예측, 탐지, 생성이 가능하다. 임베딩 기법을 이용해, 영상 등 비정형적인 데이터를 학습데이터로 활용할 수 있어, 그 활용도가 더욱 높아질 것이다.
레퍼런스
- Transformer Wiki
- What is Transfomer
- Transformer Illustration
- List Transformer
- Transformer Chatbot (wiki)
- Attention, self-attention, transformer (2nd)
- Build your own Transformer from scratch using Pytorch | by Arjun Sarkar | Towards Data Science
- A complete Hugging Face tutorial: how to build and train a vision transformer | AI Summer (theaisummer.com)
- Fast Transformer Inference with Better Transformer — PyTorch Tutorials 2.1.1+cu121 documentation
댓글 없음:
댓글 쓰기