이 글은 자연어처리 NLP(Natural language processing) 오픈소스 기반 도구를 활용한 논문 검색 및 분석 방법을 간략히 소개한다. 이 방법을 통해, 비정형적인 문서 등에서 필요한 정보를 추출하는 텍스트 데이터 마이닝 기능을 구현하고, 통찰력있는 정보 모델을 얻을 수 있다.
논문 클러스터링 분석 예시
LitStudy
LitStudy는 과학 문헌 분석을 위한 파이썬 라이브러리이다. 주피터 노트북을 사용할 수 있다. 이 라이브러리는 논문 메타데이터로 부터 가시화, 네트워크 분석, 자연어 처리 등을 지원한다.
이 라이브러리는 문헌조사되어 다음과 같이 정리한 데이터셋에서 다양한 통계적 문헌분석과 차트를 출력할 수 있다.
예. IEEE 문헌 메타데이터 일부
"Document Title",Authors,"Author Affiliations","Publication Title",Date Added To Xplore,"Publication Year","Volume","Issue","Start Page","End Page","Abstract","ISSN",ISBNs,"DOI",Funding Information,PDF Link,"Author Keywords","IEEE Terms","INSPEC Controlled Terms","INSPEC Non-Controlled Terms","Mesh_Terms",Article Citation Count,Patent Citation Count,"Reference Count","License",Online Date,Issue Date,"Meeting Date","Publisher",Document Identifier
"Exploring a multi-resolution GPU programming model for Chapel","A. Hayashi; S. Raj Paul; V. Sarkar","Georgia Institute of Technology Atlanta,Georgia,USA; Georgia Institute of Technology Atlanta,Georgia,USA; Georgia Institute of Technology Atlanta,Georgia,USA","2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)","28 Jul 2020","2020","","","675","675","There is a growing need to support accelerators, especially GPU accelerators, since they are a common source of performance improvement in HPC clusters. As for ... CUDA/HIP/OpenCL and invoking these kernels from the Chapel program using the GPUIterator [3], [4] and Chapel's C interoperability feature.","","978-1-7281-7445-7","10.1109/IPDPSW50202.2020.00117","","https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9150427","","Graphics processing units;Programming;Kernel;Data transfer;Optimization;Conferences;Writing","parallel architectures;parallel programming;program compilers;public domain software","automatic compilation;GPU kernels;Chapel program;multiresolution GPU programming model;GPU accelerators;HPC clusters;forall loops;Chapel C interoperability feature;automatic compiler-based GPU code generation;CUDA;OpenCL;HIP","","","","6","","28 Jul 2020","","","IEEE","IEEE Conferences"
예. springer 문헌 메타데이터 일부
A comparative study of GPU programming models and architectures using neural networks The Journal of Supercomputing 61 3 10.1007/s11227-011-0631-3 Vivek K. PallipuramMohammad BhuiyanMelissa C. Smith 2012 http://link.springer.com/article/10.1007/s11227-011-0631-3 Article
설치는 다음과 같다.
pip install litstudy
(pip install git+https://github.com/NLeSC/litstudy)
다음 데이터셋은 다운로드한다.
엘스비어 문헌 검색을 위한 토큰키를 얻는다.
다음은 코딩 예시이다.
# Import other libraries
import os, sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sbs
# Options for plots
plt.rcParams['figure.figsize'] = (10, 6)
sbs.set('paper')
# Import litstudy
path = os.path.abspath(os.path.join('..'))
if path not in sys.path:
sys.path.append(path)
import litstudy
# Load the CSV files. 데이터셋은 여기 링크에서 다운로드.
docs1 = litstudy.load_ieee_csv('data/ieee_1.csv')
docs2 = litstudy.load_ieee_csv('data/ieee_2.csv')
docs3 = litstudy.load_ieee_csv('data/ieee_3.csv')
docs4 = litstudy.load_ieee_csv('data/ieee_4.csv')
docs5 = litstudy.load_ieee_csv('data/ieee_5.csv')
docs_ieee = docs1 | docs2 | docs3 | docs4 | docs5
print(len(docs_ieee), 'papers loaded from IEEE')
docs_springer = litstudy.load_springer_csv('data/springer.csv')
print(len(docs_springer), 'papers loaded from Springer')
# IEEE, springer 문헌 데이터 병합
docs_csv = docs_ieee | docs_springer
print(len(docs_csv), 'papers loaded from CSV')
docs_exclude = litstudy.load_ris_file('data/exclude.ris')
docs_remaining = docs_csv - docs_exclude # 특정 문헌 제외
print(len(docs_exclude), 'papers were excluded')
print(len(docs_remaining), 'paper remaining')
# 로그 라이브러리 임포트. scopus 논문 검색. 미리, open api key를 https://dev.elsevier.com/apikey/manage서 획득해야 함.
import logging
try:
import pybliometrics
pybliometrics.init()
logging.getLogger().setLevel(logging.CRITICAL)
docs_scopus, docs_notfound = litstudy.refine_scopus(docs_remaining)
except Exception as e: # 에러 발생 가능. https://pybliometrics.readthedocs.io/en/stable/access/errors.html
print(e)
exit()
print(len(docs_scopus), 'papers found on Scopus')
print(len(docs_notfound), 'papers were not found and were discarded')
# 특정 년도 논문 필터링
docs = docs_scopus.filter_docs(lambda d: d.publication_year >= 2000)
print(len(docs), 'papers remaining')
# 년도, 저자, 언어 등 히스토그램 차트 출력
litstudy.plot_year_histogram(docs, vertical=True);
litstudy.plot_affiliation_histogram(docs, limit=15);
litstudy.plot_author_histogram(docs);
litstudy.plot_language_histogram(docs);
litstudy.plot_number_authors_histogram(docs);
# 약어 논문 맵핑 처리.
mapping = {
"IEEE International parallel and distributed processing symposium IPDPS": "IEEE IPDPS",
"IEEE International parallel and distributed processing symposium workshops IPDPSW": "IEEE IPDPS Workshops",
}
litstudy.plot_source_histogram(docs, mapper=mapping, limit=15); # 출처 차트
litstudy.plot_cocitation_network(docs, max_edges=500) # 인용 네트워크 차트
# 말뭉치(corpus) 분석.
corpus = litstudy.build_corpus(docs, ngram_threshold=0.8) # 말뭉치(corpus) 생성
litstudy.compute_word_distribution(corpus).filter(like='_', axis=0).sort_index() # 단어 빈도수 계산
plt.figure(figsize=(20, 3))
litstudy.plot_word_distribution(corpus, limit=50, title="Top words", vertical=True, label_rotation=45); # 단어 빈도수 출력
# 토픽 간 유사도 거리 클러스터링을 위한 NMF(Non-negative Matrix Factorization) 분석 (여기 참고)
num_topics = 15
topic_model = litstudy.train_nmf_model(corpus, num_topics, max_iter=250)
for i in range(num_topics):
print(f'Topic {i+1}:', topic_model.best_tokens_for_topic(i))
plt.figure(figsize=(15, 5))
litstudy.plot_topic_clouds(topic_model, ncols=5);
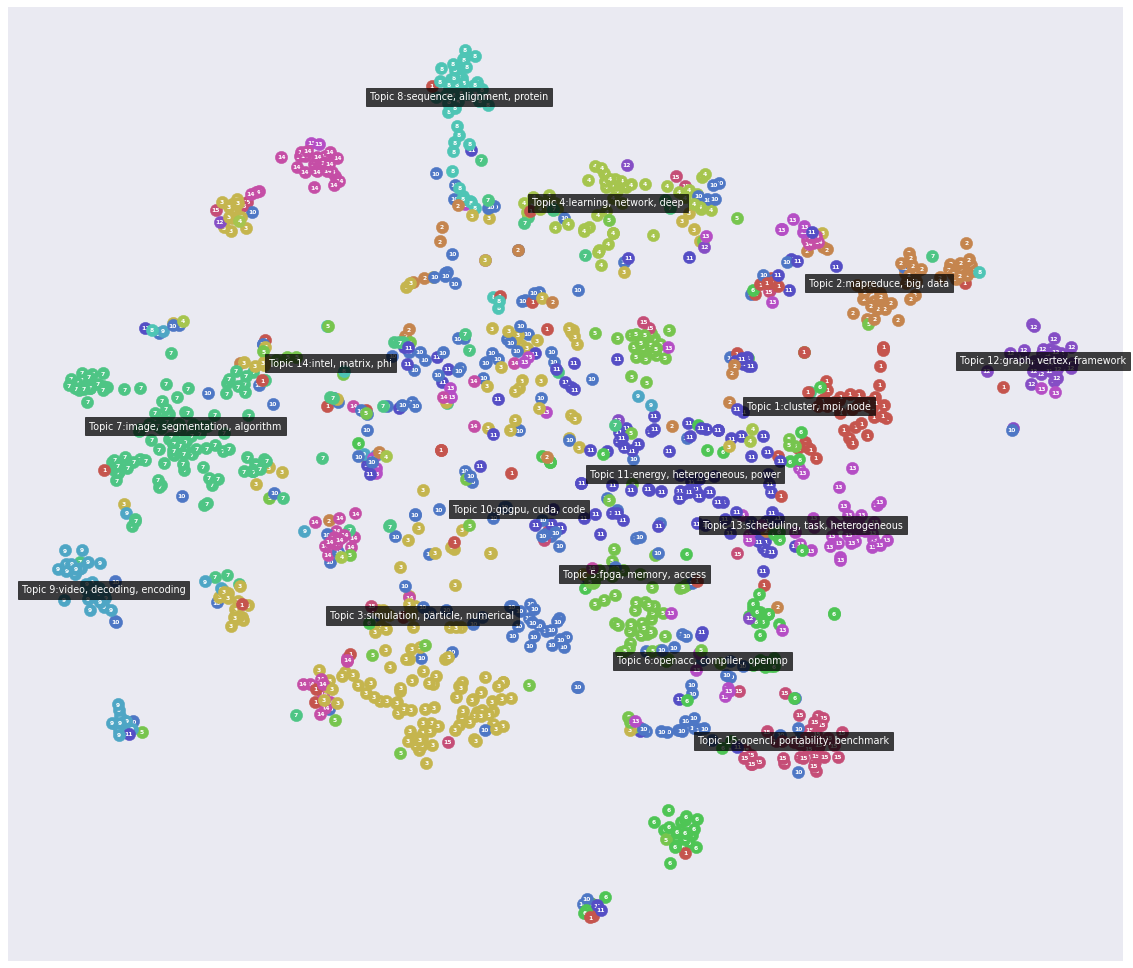
plt.figure(figsize=(20, 20))
litstudy.plot_embedding(corpus, topic_model);
결과는 다음과 같다. 단, scopus 검색 시 특정 서비스 요청 건수가 넘어갈 경우 예외가 발생할 수 있다(참고 - pybliometrics.readthedocs.io/en/stable/access/errors.html).




Scholarly
Scholarly는 구글 스칼라에서 학술 논문들을 검색하고, 메타데이터를 얻을 수 있는 라이브러리이다. 앞의 litstudy는 메타데이터가 얻어진 후에 모델 분석이 가능하므로, 이런 도구를 이용해, 메타데이터와 같은 소스를 먼저 구축할 필요가 있다.
설치는 다음과 같다.
pip3 install scholarly
사용 방법은 다음과 같다.
from scholarly import ProxyGenerator, scholarly
try:
# pg = ProxyGenerator()
# pg.FreeProxies()
# scholarly.use_proxy(pg)
title = 'Deep Learning based Anomaly Detection' # 검색할 논문 타이틀
search_query = scholarly.search_pubs(f'title:"{title}"')
while(True):
pub = next(search_query) # 검색된 논문 메타데이터 출력
if pub == None:
break
print(pub['bib'])
# scholarly.fill(pub, sections=['abstract'])
# print(pub['bib']['abstract'])
except Exception as e: # maxtriesexceededexception
# https://scholarly.readthedocs.io/en/stable/ProxyGenerator.html
print(e)
실행 결과는 다음과 같다.

단, 이 도구는 DDoS(Distributed Denial of Service) 공격을 막기 위해, 구글 서버에서 호출 횟수, 시간 등이 빈번할 경우 max tries exceeded exception 를 발생시킬 수 있다. 이 경우, 앞의 코드의 ProxyGenerator 주석 부분을 제거하고 실행해 보기를 바란다(다른 IP로 변경해야 함).
레퍼런스
- Litstudy, GitHub - NLeSC/litstudy: Using the power of Python and Jupyter notebooks to automate analysis of scientific literature
- Scholarly, pypi.org/project/scholarly
- Scholarly document, scholarly.readthedocs.io/en/stable/quickstart.html
- Scholarly example, snyk.io/advisor/python/scholarly/example
- 오픈소스 NLP 텍스트 마이닝 도구 spacy 기반 텍스트 컨텐츠 유사도 계산 및 분석 방법
댓글 없음:
댓글 쓰기