이 글은 최신 딥러닝 기반 3차원 스캔 데이터, 포인트 클라우드 학습, 세그먼테이션 논문 분석 내용을 요약한다. 이 분야는 무인 자율차, 로보틱스 비전 등 관련 분야에서 필수적인 기술을 연구한다. 분석을 위해,
Papers with code에 올라온 레퍼런스를 참고하였다.
참고로, 이 사이트는 페이스북 Meta AI Research에서 운영하는 머신러닝 최신 논문, 코드, 데이터셋을 업데이트하는 가장 유명한 사이트이다.
기술 조사 분석 준비
영향력 높은 논문 조사
관련 모든 연구를 조사, 분석한다는 것은 불가능하다. 그러므로, 다음과 같이 영향력을 정의해, 이에 근거한 방법으로 논문을 조사한다. 철저히 코드로 제대로 구현된 연구만을 조사 대상으로 한다.
Research Impact = {dataset, benchmarking, performance, github impact}
다음은 공개된 3차원 데이터셋에서 가장 성능이 좋은 베스트 모델을 표시한것이다.
데이터셋마다 mAcc, mIoU 등 성능 지표가 가장 뛰어난 모델을 확인한다.
이 중 코드가 있고, 영향력이 높은 연구 논문들을 선정한다. 참고로, 이 연구는 3년 내로 제한한다. 이전 PointNet, PointNet++ 등 기술 분석은
여기를 참고한다.
- Point Transformer. https://paperswithcode.com/paper/point-transformer-1
- KPConv: Flexible and Deformable Convolution for Point Clouds. https://paperswithcode.com/paper/kpconv-flexible-and-deformable-convolution
- PCT: Point cloud transformer. https://paperswithcode.com/paper/pct-point-cloud-transformer
- PointCutMix: Regularization Strategy for Point Cloud Classification. https://paperswithcode.com/paper/pointcutmix-regularization-strategy-for-point
- Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis. https://paperswithcode.com/paper/walk-in-the-cloud-learning-curves-for-point
- PointMixer: MLP-Mixer for Point Cloud Understanding. https://paperswithcode.com/paper/pointmixer-mlp-mixer-for-point-cloud
- Point-PlaneNet: Plane kernel based convolutional neural network for point clouds analysis. https://paperswithcode.com/paper/point-planenet-plane-kernel-based
- Dense-Resolution Network for Point Cloud Classification and Segmentation. https://paperswithcode.com/paper/dense-resolution-network-for-point-cloud
- FG-Net: Fast Large-Scale LiDAR Point Clouds Understanding Network Leveraging Correlated Feature Mining and Geometric-Aware Modelling. https://paperswithcode.com/paper/fg-net-fast-large-scale-lidar-point
- RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. https://paperswithcode.com/paper/191111236
- Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. https://paperswithcode.com/paper/cylinder3d-an-effective-3d-framework-for
- Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform. https://paperswithcode.com/paper/multi-scale-interaction-for-real-time-lidar
- Automatic labelling of urban point clouds using data fusion. https://paperswithcode.com/paper/automatic-labelling-of-urban-point-clouds
연구 핵심 아이디어, 기술 조사 및 분석
선정된 논문을 다음과 같이 분석한다.
Point Transformer. https://paperswithcode.com/paper/point-transformer-1
홍콩대에서 개발. 공간 데이터 특징을 캡쳐할 수 있는 Self-attention 네트웍 특징을 3차원 포인트 클라우드 처리에 적용. S3DIS데이터셋에 적용 후 mIoU 70.4% 획득.
Point Transformer는 셀프 주의 네트웍을 구성하는 위치 인코딩, MLP, softmax를 사용함.
이를 다음과 같이 residual point transformer 로 중첩하고, U-Net을 적용한 Transition Down, Up을 통해, 포인트를 세그먼테이션하고, pooling, MLP를 통해 객체 분류함. 위치 인코딩은 delta = theta(Pi - Pj) 식으로 정의됨. 각 층은 [N, N/4, N/16, N/64, N/256]으로 축소되고, 특징 텐서는 증가되도록 설계됨(N=입력 포인트수).
테스트 결과는 다음과 같음. 이 결과는 실내 3차원 스캔 데이터셋만 적용된 한계가 있음.
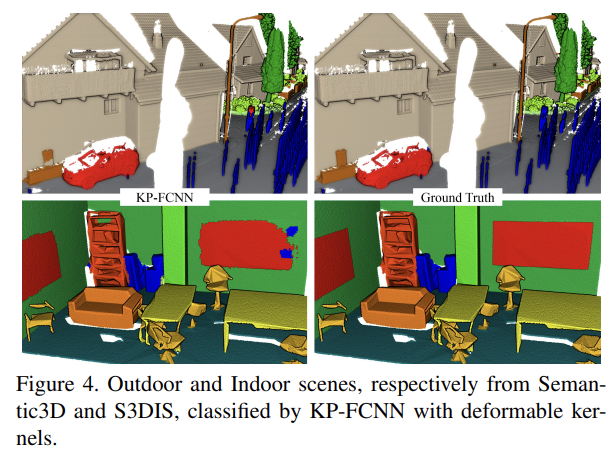
KPConv: Flexible and Deformable Convolution for Point Clouds. https://paperswithcode.com/paper/kpconv-flexible-and-deformable-convolution
Kernel Point Convolution 기술 제안. 커널 포인트의 유클리드 거리를 사용해 특징 추출.
좋은 성능을 가지며, 테스트 결과 ModelNet40에서 mIoU 86.4를 가짐.
PCT: Point cloud transformer. https://paperswithcode.com/paper/pct-point-cloud-transformer
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions. https://paperswithcode.com/paper/benchmarking-robustness-of-3d-point-cloud
앞에서 설명한 논문과 같은 attention을 사용함. 관련 초기 논문으로 테스트 데이터셋 부족. 구조는 Point Transformer와 유사하며 다음과 같음. 영향력 낮음.
PointCutMix: Regularization Strategy for Point Cloud Classification. https://paperswithcode.com/paper/pointcutmix-regularization-strategy-for-point
소규모 데이터셋에서만 테스트됨.
Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis. https://paperswithcode.com/paper/walk-in-the-cloud-learning-curves-for-point
포인트의 커브를 탐지하는 커브넷을 정의하고, 이를 통해, 분류 적용. 테스트 소규모.
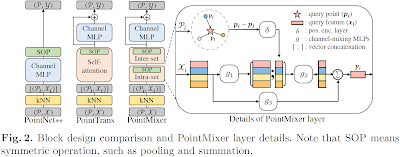
PointMixer: MLP-Mixer for Point Cloud Understanding. https://paperswithcode.com/paper/pointmixer-mlp-mixer-for-point-cloud
이 연구는 최근 CNN, 트랜스포머 기술 적용된 세그먼테이션 방식에서, 다른 접근을 취함. 3차원 스캔 데이터셋은 사진 이미지와는 다르게, 본질적으로 분산, 정렬되지 않음, 비규칙성 등의 한계로 MLP를 직접 사용할 수 없음. 이 논문은 토큰 혼합 MLP(token-mixing MLP)와 softmax를 사용한 PointMixer 제안.
Point-PlaneNet: Plane kernel based convolutional neural network for point clouds analysis. https://paperswithcode.com/paper/point-planenet-plane-kernel-based
스캔 데이터셋에서 평면을 학습할 수있는 PlaneConv제안.
다음은 그 결과임.
Dense-Resolution Network for Point Cloud Classification and Segmentation. https://paperswithcode.com/paper/dense-resolution-network-for-point-cloud
다양한 해상도 스캔 데이터셋을 학습할 수 있는 Dense resolution network(DRNet)을 제안.
FG-Net: Fast Large-Scale LiDAR Point Clouds Understanding Network Leveraging Correlated Feature Mining and Geometric-Aware Modelling. https://paperswithcode.com/paper/fg-net-fast-large-scale-lidar-point
빠른 대용량 스캔 라이다 데이터셋 모델 학습 FG-Net 기술 제안.
이 모델 개발 순서는 같음.
- 스캔 데이터에서 밀도 낮은 노이즈 및 아웃라이어 제거
- 포인트 지역 특징 캡쳐하는 FG-Conv 정의. 포인트 상관 특정 추출기 PFM, 형상 컨볼루션 모델 GCM, 어텐션 수집 AG로 구성됨.
- 특징 피라미트 잔차 계층 구조 적용. ResNet, Encoder-decoder 기반 구조 설계.
디자인된 구조는 다음과 같음.
테스트 결과는 mIoU 70.8임. 상세 성능은 다음과 같음.
GTX 1080 GPU with 8 GB memory.
The sampling methods include Random Sampling (RS), Reinforcement Learning based Sampling (RLS) [48], GSS [46],
IDS, Farthest Point Sampling (FPS), and Generative Network
(GS) [49]
테스트에 사용된 데이터셋은 다음과 같음.
다음은 테스트 결과 일부임. 이 연구는 코드 개발에
KPConv(Flexible and Deformable Convolution for Point Clouds) 등을 사용함. 코드 빌드 및 사용은 다소 불편함.
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. https://paperswithcode.com/paper/191111236
이 기술은 스캔 데이터 지역 특징 수집을 위한, 지역 특징 수집기를 램덤 샘플링을 이용해 처리. 이를 통해, 대용량 스캔 데이터 처리 지원.
입력 포인트는 (N, 3+d) 텐서 모양. 지역 공간 인코딩 LocSE를 통해, 특징 수집 후 Attentive Pooling 수행해 데이터 특징 일반화해 분류함. 확산 잔자 블럭을 사용해 ResNet과 같이 기울기 소멸 문제 해결하고, Encoding-decoding 구조로 세그먼테이션함.
RTX 2080 에서 SemanticKITTI 8번 데이터셋 평가에 전체 185초 소요됨. mIoU는 77.4임. 결과는 다음과 같음.
Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. https://paperswithcode.com/paper/cylinder3d-an-effective-3d-framework-for
스캔 데이터 분산을 격자를 사용하지 않고, 실린더를 사용해 성능을 높임.
Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform. https://paperswithcode.com/paper/multi-scale-interaction-for-real-time-lidar
임베디드 보드에서도 초당 24 스캔 데이터 처리 가능한 기술 제안. 많은 딥러닝 모델이 실제 데이터에서 성능과 정확도 문제가 있었음. 이런 문제 해결을 시도함.
Automatic labelling of urban point clouds using data fusion. https://paperswithcode.com/paper/automatic-labelling-of-urban-point-clouds
이 논문은 라벨링하는 방법을 region-growing 알고리즘 등을 이용해 자동화하는 기술을 제안함. 기술적 내용은 비전 분야에 알려진 알고리즘 사용.
마무리
지금까지 딥러닝 최신 기술을 조사해 분석하였다. 13개 연구를 조사해 본 결과 이중 유의미한 결과는 가지는 기술은 몇개로 추려진다. 개발된 코드에 대한 품질과 사용성은 논문을 통해 알수는 없다. 이는 딥러닝 학습 가능한 개발 환경에서 직접 소스 설치, 빌드 후 테스트해야 하는 것으로, 좀 더 정확한 분석에는 더 많은 시간이 필요하다.
레퍼런스