이 글은 해리슨 체이스가 개발한 오픈소스인 랭체인(LangChain) 아키텍처와 동작 방법을 분석한다. 현재 개발자들 사이에 대중적으로 사용되고 있는 랭체인은 LLM 모델 통합과 다양한 데이터소스를 지원하여, LLM모델의 활용성을 극대화한다. 이 글을 통해, LLM 서비스 개발에 필요한 랭체인의 아키텍처와 동작 원리를 이해할 수 있다.

LLM 용어와 상세 개념은 다음 링크를 참고한다.
- 오픈소스 기반 LLM의 민주화, LLAMA-2 논문 분석 및 기술 요약하기
- Langchain 기반 개인화된 ChatGPT 대화, 코딩, QA 챗봇 자체 서비스 개발 방법
- 어텐션 기반 트랜스포머 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법 소개
- 트랜스포머 디코더 핵심 코드 구현을 통한 동작 메커니즘 이해하기
- 오픈소스 기반 LLM의 민주화, LLAMA-2 논문 분석 및 기술 요약
- 생성AI 멀티모달 모델 개발의 시작. OpenAI의 CLIP모델 이해, 코드 분석, 개발, 사용하기
- GPU 없는 로컬에서 서비스 가능한 경량 소형 LLM, LLAMA2.c 빌드, 실행, 학습 및 코드 분석하기
- 대중화된 멀티모달 생성AI 모델, Stable Diffusion 아키텍처 분석과 동작 원리 이해
소개
Langchain(랭체인)은 LLM에 원하는 결과를 얻을 수 있도록, 다양한 프롬프트 입력 및 구조화된 출력, RAG, 튜닝과 같은 기능을 제공하는 라이브러리다. 랭체인 설치는 다음과 같다(참고).
pip install langchain
다음 장에서는 랭체인의 기본 개념인 프롬프트, 메모리, 에이전트를 간단히 설명하고, 실습을 하도록한다.
작동 개념
목표
랭체인은 LLM이 다양한 작업에 사용할 수 있는 방법을 제공한다. 예를 들어, LLM은 분류, QA, 차트 해석, 그림 생성 등 다양한 곳에 사용될 수 있다. 랭체인은 이를 체계적으로 연결해 실행할 수 있다.

랭체인 작업 중 일부(Pinecone)
프롬프트
프롬프트는 보통 LLM에 대한 명령, 컨텍스트로 구성된다. 컨텍스트는 외부 정보를 의미한다. 그리고, LLM에 질문한다. 이 3개 구조는 다음 그림과 같다.

프롬프트 템플릿 구조(명령, 컨텍스트, 질문과 답변. Pinecone)
명령들: 모델에게 무엇을 하라고 지시함. 어떤 외부 정보가 있고, 이를 이용해 어떻게 출력을 생성하는 지 지시함.컨텍스트: 외부 정보이며, 프롬프트에 의해 수동 입력, 벡터데이터베이스 검색 혹은 API 등 Tool 에 의해 삽입됨.
질의: 사용자에 의해 입력되는 질문.
출력 지시자: 만약 생성되는 텍스트의 첫번째에 나와야 할 것을 지시함. 예를 들어, 파이썬 코드는 반듯이 import 문장으로 시작되어야 함.
랭체인의 프롬프트 템플릿은 동적으로 사용자 입력에 의해 생성될 수 있다.
template = """Answer the question based on the context below. If thequestion cannot be answered using the information provided answerwith "I don't know".Context: Large Language Models (LLMs) are the latest models used in NLP.Their superior performance over smaller models has made them incrediblyuseful for developers building NLP enabled applications. These modelscan be accessed via Hugging Face's `transformers` library, via OpenAIusing the `openai` library, and via Cohere using the `cohere` library.Question: {query}Answer: """prompt_template = PromptTemplate(input_variables=["query"],template=template)
메모리
대화형 메모리는 채팅과 같은 방식으로 질의에 응답할 수 있도록 한다. 이를 통해, 일관된 대화가 가능하다.

대화형 메모리 역할(좌: 메모리 있음. 우: 메모리 없음)
메모리는 ConversationChain을 통해 적용된다.
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory())
이 체인에 내장된 conversation.prompt.template 프롬프트 템플릿을 출력하면, {history}가 포함된 것을 알 수 있다. history는 지금까지 LLM과 주고 받은 질답의 리스트로 입력될 것이다.
history와 같은 메모리는 LLM에 컨텍스트와 함께 입력되므로, LLM의 시퀀스 토큰 최대 크기만큼만 기억이 가능하다(보통 4k). 다음 함수를 이용해 얼마의 토큰이 사용되었는지 알 수 있다.
from langchain.callbacks import get_openai_callback
def count_tokens(chain, query):
with get_openai_callback() as cb:
result = chain.run(query)
print(f'Spent a total of {cb.total_tokens} tokens')
return result
count_tokens(
conversation_buf,
"My interest here is to explore the potential of integrating Large Language Models with external knowledge"
)
메모리를 사용하면, 과도한 토큰 사용량으로 인한 비용증가가 발생한다. 그러므로, 이를 요약해 사용하는 ConverationSummaryMemory로 요약한 것을 LLM에 전달할 수도 있다.
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
이 경우, 프롬프트 템플릿에는 {summary} 변수가 포함되고, 메모리 요약이 LLM호출시 입력된다. 그럼에도 불구하고, 모든 대화를 요약한다는 것은 비효율적이다. ConversationSummaryBufferMemory 를 이용하면, k개 만큼 대화만 요약해 메모리로 사용한다.
지식 베이스 저장과 검색
LLM에서 학습되지 않은 지식은 외부에서 공급되어야 한다. 이를 위해 벡터데이터베이스에 미리 지식을 저장해 놓거나, Tool을 사용해 지식을 얻을 수 있다. 너무 큰 지식을 LLM에 전달하면 시퀀스 최대 토큰 크기를 넘어가므로, 지식 문서는 RecursiveCharacterTextSplitter 등을 이용해 청크란 작은 단위로 분해한다.
질문에 대한 지식 검색을 위해, 임베딩 벡터를 이용한다. 이를 이용해 질문에 가장 가까운 의미를 가진 임베딩 벡터를 얻을 수 있다. 임베딩 벡터는 지식을 가리키고 있어, 이를 LLM에 입력해 원하는 답을 얻는다.

텍스트 임베딩 예시(link)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
이 경우, 환각이 포함된 답변을 얻을 수 있어, RetrievalQAWithSourcesChain를 이용해 참조 소스를 포함해 답을 얻을 수 있다.
에이전트
ChatGPT 4버전까지는 문맥에 맞는 결과를 생성하지 못할 때가 있었다. 예를 들어, 3.14159 * 3.14159를 계산한다던지, 같은 용어를 사용하지만 새로운 개념일 때가 그렇다. 문맥을 고려하지 않고 확률적으로 그럴듯한 답을 생성하는 것을 환각현상이라 하는 데, 이를 에이전트 기술을 이용해 제어할 수 있다.
에이전트 개념
에이전트는 LLM을 위한 도구(tool)이다. 에이전트를 사용하면, 파이썬 코드를 작성하고 실행할 수 있고, SQL 질의도 가능하다.
에이전트는 다음 같은 종류가 있다.
- zero-shot-react-description: 에이전트와 단일 상호작용을 하며 메모리는 없음
- conversational-react-description: 이전 제로샷 리액트와 동일하지만 대화 메모리를 지원. 이 프롬프트는 {chat_history}가 포함됨.
- react-docstore: 랭체인의 docstore를 사용해 정보 검색 및 조회 수행.
- self-ask-with-search: 다단계 질문을 하여, 그 결과를 모아 추론 수행.
LCEL 언어
앞에서 설명한 바와 같이 랭체인은 모델 입출력, 데이터 검색, 에이전트 지원, 체인, 컨텍스트 메모리 기능을 제공한다. 이를 효과적으로 연결해 호출하도록 랭체인은 LCEL(LangChain Expression Language)를 지원한다.
LCEL를 이용해 각 구성요소를 유기적으로 연결시킬 수 있다. LCEL은 유닉스 파이프라인 개념을 차용했다. 다음은 LCEL 예시를 보여준다.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser
# LCEL 예시
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
이와 더불어, 목적에 맞는 다양한 프롬프트 템플릿, 구조화된 출력을 제공한다.
from langchain.output_parsers.json import SimpleJsonOutputParser
json_prompt = PromptTemplate.from_template(
"Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
)
json_parser = SimpleJsonOutputParser() # JSON 파서
# 프롬프트, 모델, 파서 체인 생성
json_chain = json_prompt | model | json_parser # 유닉스 파이프라인 개념 차용함.
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"}))
print(result_list)

마치 유닉스 파이프라인과 같은 이 언어는 Runnables 클래스에서 파생받아 각 단계를 연결할 수 있도록 한다.

from langchain_core.runnables import RunnableLambda
def add_five(x):
return x + 5
def multiply_by_two(x):
return x * 2
# wrap the functions with RunnableLambda
add_five = RunnableLambda(add_five)
multiply_by_two = RunnableLambda(multiply_by_two)
chain = add_five | multiply_by_two
chain.invoke(3)
LCEL 언어 동작 구조
이 중에 핵심적인 것만 분석해 본다. 우선, LCEL의 동작 방식을 위해 어떤 디자인패턴을 구현하였는 지 확인한다. 이 부분은 runnables 패키지가 담당한다. 이 언어는 유닉스의 파이프라인 처리를 다음과 같이 흉내낸다. z = a | b | c
z.stream('abc')
이를 위해, 파이썬 문법을 적극 사용하고 있다. 우선 '|' 연산자를 오버로딩(overloading)하기 위해, 파이썬 Runnable 클래스를 정의해 __or__ 연산자를 구현한다. 이 연산자는 self object와 right object 두 객체를 입력받아 list를 만든 후 리턴하는 역할을 한다. 앞의 예시에서 보면, 'a | b'를 실행가능한 객체 리스트로 만들어 리턴한다. 결론적으로 a, b, c객체를 리스트로 만들고, 이 리스트를 z에 할당한다.
z의 stream()이 호출되면, a, b, c를 각각 invoke() 하여 실행하는 방식이다. 그러므로, 다음 그림과 같이, LCEL를 지원하는 객체는 Runnable을 파생받아야 하며, stream, invoke와 같은 주요 함수를 구현해야 한다.
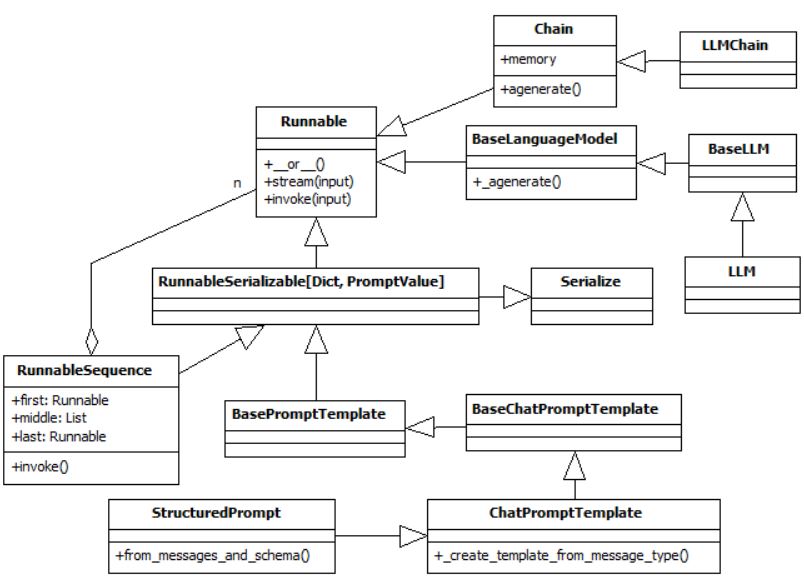
각 주요 클래스 함수의 동작방식을 좀 더 자세히 살펴본다. LCEL 파이프라인을 구현하는 __or__()함수는 다음과 같이 입력된 객체를 Sequence 형식의 steps 리스트로 담아두는 역할을 한다.
class Runnable():
...
def __or__(self, other: Union[Runnable[Any, Other], Callable[[Any], Other], ...]):
return RunnableSequence(self, coerce_to_runnable(other))
def stream(self, input: Input, config, **kwargs: Optional[Any]) -> Iterator[Output]:
yield self.invoke(input, config, **kwargs) # steam 호출 시 invoke 함수 호출
def invoke(self, input: Input, config: Optional[RunnableConfig] = None):
callback_manager = get_callback_manager_for_config(config)
run_manager = callback_manager.on_chain_start(dumpd(self), input)
for i, step in enumerate(self.steps):
input = step.invoke(input) # steps 리스트의 객체 invoke() 호출 후 input 갱신
invoke()가 호출되면, 담아둔 steps 리스트의 객체를 각각 invoke()한다. 이런 방식으로 파이프라인을 구현하고 있다.
프롬프트 템플릿 처리 방식
JSON과 같이 구조화된 출력을 생성할 때는 ...Template 이름을 가진 클래스가 create_template_from_message_type() 함수를 구현한다. 그 과정을 확인해 보자.
def create_template_from_message_type(message_type, template, template_format):
if message_type in ("human", "user"): # human, user 일 경우, human template 생성
message =HumanTemplate.from_template(template, template_format)
elif message_type in ("ai", "assistant"): # ai 일 경우, AI template 생성
message = AIMessagePromptTemplate.from_template(template, template_format)
elif message_type == "system":
message = SystemMessagePromptTemplate.from_template(...)
elif message_type == "placeholder": # 변수 형태로 출력할 경우, placeholder 생성
if isinstance(template, str):
var_name = template[1:-1]
message = MessagesPlaceholder(variable_name=var_name, optional=True)
elif len(template) == 2 and isinstance(template[1], bool):
var_name = var_name_wrapped[1:-1]
message = MessagesPlaceholder(variable_name=var_name, optional=is_optional)
프롬프트 템플릿에 따라 적절한 템플릿 객체를 생성해 처리한다. invoke() 했을 때, input에 대한 각각 적합한 프롬프트를 출력한다.
변수가 담긴 출력을 위해서는 메시지에서 변수를 예측해야 한다. 이 부분은 from_messages_and_schema()가 담당한다.
def from_messages_and_schema(messages, schema):
# 자동적으로 메시지로 부터 변수를 추정함
input_vars: Set[str] = set()
partial_vars: Dict[str, Any] = {}
for _message in _messages:
if isinstance(_message, MessagesPlaceholder) and _message.optional:
partial_vars[_message.variable_name] = []
elif isinstance(
_message, (BaseChatPromptTemplate, BaseMessagePromptTemplate)
):
input_vars.update(_message.input_variables) # 변수값 업데이트
출력 텍스트에서 구조화된 출력을 위해, 변수와 변수 유형을 검증해야 한다. 이 기능은 PyDantic을 이용해 처리한다.
앞서 정의된 클래스는 LLM에 입력할 프롬프트를 작성하고, 출력된 결과를 파싱하는 것에 초점을 맞추고 있다.
LLM 모델 호출과 임베딩 데이터베이스 처리
LLM 처리 부분은 llm.py, llms.py 소스에 구현되어 있다. Chain은 전문가가 질문에 답변하며 정보를 업데이트하는 연속된 질의를 담당한다. BaseLLM은 LLM 이 호출될 수 있도록 일반화한 클래스이다. invoke()가 호출되면 프롬프트, 입력과 함께 _agenerate()이 호출된다. 이 함수는 실제 설치된 라마와 같은 LLM혹은 OpenAI의 ChatGPT API를 호출해 출력을 생성하는 역할을 한다.
class LLMChain(Chain):
async def _agenerate(self, prompts: List[str], ..., **kwargs: Any) -> LLMResult:
class BaseLLM():
async def _agenerate(self, prompts: List[str], ..., **kwargs: Any) -> LLMResult:
return await run_in_executor(None, self._generate, prompts, stop, ..., **kwargs)
LangChain은 임베딩 벡터 데이터베이스를 지원함으로써 LlamaIndex와 함께 RAG를 처리한다. 이를 통해, 환각 현상을 줄여주고, 전문적인 응답이 가능하도록 한다. 이 부분은 VectorStore 기본 클래스에서 담당한다. LangChain은 Chroma 등 다양한 데이터베이스와 임베딩 벡터 간 유사도 계산을 지원한다. 벡터 유사도 검색을 통해, 질문의 배경이 되는 데이터를 미리 LLM에게 전달해준다.

def similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4, filter: Optional[dict] = None) -> List[Tuple[Document, float]]:
filter_condition = ""
if filter is not None: # 필터의 key, value, conditions을 얻어 SQL 문을 정의함
conditions = [
f"metadata->>{key!r} = {value!r}" for key, value in filter.items()
]
filter_condition = f"WHERE {' AND '.join(conditions)}"
# 쿼리문 생성
sql_query = f"""
SELECT *, l2_distance(embedding, :embedding) as distance
FROM {self.collection_name}
{filter_condition}
ORDER BY embedding <-> :embedding
LIMIT :k
"""
# 임베딩 검색 파라메터 설정
params = {"embedding": embedding, "k": k}
# 쿼리 질의 및 fetch 후 결과 획득
with self.engine.connect() as conn:
results: Sequence[Row] = conn.execute(text(sql_query), params).fetchall()
# 출력 형태로 반환
documents_with_scores = [
(
Document(
page_content=result.document,
metadata=result.metadata,
),
result.distance if self.embedding_function is not None else None,
)
for result in results
]
return documents_with_scores
임베딩 벡터 간 유사도 검색은 cosine 함수, kNN 등 다양한 것이 사용될 수 있다.
이외에도 에이전트는 HuggingGPT 등을 이용해 멀티모달 도구를 지원하게 할 수도 있다.
좀 더 다양한 에이전트 예시는 다음 링크를 참고한다.
LLamaIndex 구조 분석
LLamaIndex(라마 인덱스)는 LLM 클라우드에서 원하는 LLM을 검색하여, 모델을 다운로드받고, 사용하기 전까지 필요한 단계를 자동화한 라이브러리이다. 사용자 데이터 소스를 LLM에 연결하는 방법을 손쉽게 할 수 있도록 한다.
LLamaIndex는 RAG 애플리케이션에 대한 벡터 임베딩을 로드, 준비하는 데 도움이 되는 데이터 커넥터, 인덱스 및 쿼리 엔진과 같은 여러 도구를 제공한다. LLamaIndex는 다음 그림과 같이 RAG에 대한 지식 베이스를 생성하고, 이를 LLM에게 전해주는 기능을 구현하고 있다.

LLM과 지식베이스 관계
예를 들어, LLamaIndex는 사용자 데이터인 pdf documents를 load, parse, index, query하는 API를 제공한다. 여기서 index는 임베딩 벡터로 데이터 변환을 지원함을 의미한다.

LlamaIndex와 RAG 처리 방식
다음은 langchain과 함께 사용한 llama_index의 동작 방식을 보여준다.
from langchain import Chain
from llama_index import LLaMAIndex
class ProcessingChain(Chain): # LLM 체인 생성
def __init__(self):
super().__init__()
def _call(self, inputs):
return {"output": f"Processed: {inputs['input']}"} # 이해를 위해, 간단한 LLM 출력 가정
processing_chain = ProcessingChain() # LLM 체인 생성
index = LLaMAIndex() # 라마 인덱스 생성
# 문서 정의. 예를 들어, PDF, Image등 임베딩 처리될 수 있는 것이면 어떤 데이터도 가능
documents = [
{"id": 1, "content": "LangChain is a framework for building applications with large language models."},
{"id": 2, "content": "LLaMAIndex is used for indexing and querying text data."}
]
# 문서들 인덱싱 처리
for doc in documents:
processed_content = processing_chain.run({"input": doc["content"]})["output"]
index.add_document(doc["id"], processed_content) # 인덱스로 추가
query = "What is LangChain?" # 질의함
results = index.query(query) # 결과 리턴
print("Query results:") # 결과 출력
for result in results:
print(result)
에이전트 개발 실습
계산기 에이전트를 개발해 보기 위해 간단한 실습 코드를 준비하였다.
에이전트 개발을 위해 먼저 에이전트가 사용할 도구들을 만든다.
from langchain import OpenAI
llm = OpenAI(
openai_api_key="OPENAI_API_KEY",
temperature=0,
model_name="text-davinci-003"
)
from langchain.chains import LLMMathChain
from langchain.agents import Tool
llm_math = LLMMathChain(llm=llm)
# initialize the math tool
math_tool = Tool(
name='Calculator',
func=llm_math.run,
description='Useful for when you need to answer questions about math.'
)
# when giving tools to LLM, we must pass as list of tools
tools = [math_tool]
이제 에이전트를 앞의 도구를 이용해 생성한다. 여기서 zero-shot 의 의미는 에이전트가 현재 동작에 대해서만 작동되며 메모리는 사용하지 않음을 의미한다. react 프레임웍을 사용해 도구 설명 만을 기반으로 사용할 도구를 결정하게 된다.
from langchain.agents import initialize_agent
zero_shot_agent = initialize_agent(
agent="zero-shot-react-description",
tools=tools,
llm=llm,
verbose=True,
max_iterations=3
)
이제 다음과 같이 제대로 에이전트가 작업을 수행하는 지 테스트해보자.
zero_shot_agent("what is (4.5*2.1)^2.2?")
zero_shot_agent("if Mary has four apples and Giorgio brings two and a half apple boxes (apple box contains eight apples), how many apples do we have?")
제대로 실행되겠지만, 다음과 같은 질문을 하면 실패할 것이다.
zero_shot_agent("what is the capital of Norway?")
우리는 단 하나의 계산기 도구만 있으므로, 랭체인에 이미 만들어 놓은, 언어를 해석해 논리적으로 추론하는 도구를 추가해 넣는다.
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
prompt = PromptTemplate(
input_variables=["query"],
template="{query}"
)
llm_chain = LLMChain(llm=llm, prompt=prompt)
# initialize the LLM tool
llm_tool = Tool(
name='Language Model',
func=llm_chain.run,
description='use this tool for general purpose queries and logic'
)
tools.append(llm_tool)
# reinitialize the agent
zero_shot_agent = initialize_agent(
agent="zero-shot-react-description",
tools=tools,
llm=llm,
verbose=True,
max_iterations=3
)
이런 방식으로 에이전트를 확장해 나갈 수 있다.
사용자가 도구를 직접 만들 수도 있다. 다음은 원 둘래를 계산하는 도구 정의를 보여준다.
from langchain.tools import BaseTool
from math import pi
from typing import Union
class CircumferenceTool(BaseTool):
name = "Circumference calculator"
description = "use this tool when you need to calculate a circumference using the radius of a circle"
def _run(self, radius: Union[int, float]):
return float(radius)*2.0*pi
def _arun(self, radius: int):
raise NotImplementedError("This tool does not support async")
다음과 같이 삼각형의 빗변을 계산하기 위해 여러 파라메터를 입력받은 도구도 만들 수 있다.
from typing import Optional
from math import sqrt, cos, sin
desc = (
"use this tool when you need to calculate the length of a hypotenuse"
"given one or two sides of a triangle and/or an angle (in degrees). "
"To use the tool, you must provide at least two of the following parameters "
"['adjacent_side', 'opposite_side', 'angle']."
)
class PythagorasTool(BaseTool):
name = "Hypotenuse calculator"
description = desc
def _run(
self,
adjacent_side: Optional[Union[int, float]] = None,
opposite_side: Optional[Union[int, float]] = None,
angle: Optional[Union[int, float]] = None
):
# check for the values we have been given
if adjacent_side and opposite_side:
return sqrt(float(adjacent_side)**2 + float(opposite_side)**2)
elif adjacent_side and angle:
return adjacent_side / cos(float(angle))
elif opposite_side and angle:
return opposite_side / sin(float(angle))
else:
return "Could not calculate the hypotenuse of the triangle. Need two or more of `adjacent_side`, `opposite_side`, or `angle`."
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
tools = [PythagorasTool()]
랭체인 구조 분석
langchain 구조를 분석하기 위해, github clone 후 UML로 모델링해 본다. 주요 패키지는 다음과 같다.

cli는 langchain의 command line interface, core는 langchain의 핵심 구현 코드가 정의된다. 이 부분은 다음 패키지로 구성된다.

참고로, 이 패키지들은 다음 그림의 일부이다.

Langchain v.0.2.0 패키지
마무리
LangChain을 개발한 해리슨 체이스(Harrison Chase)은 머신러닝 프로그래머로 일하며, LLM을 사용할 때 불편한 점을 재빨리 개선한 사람이다. 그는 2022년 말 랭체인(LangChain)을 공동 설립했다. 그는 누구보다도 파이썬 언어를 잘 알고 있었던 것 같다. 앞서 분석한 대로, 파이썬의 일반화 구문을 적극 활용해 누구나 GPT-4와 같은 대규모 언어 모델로 구동되는 앱을 단 20줄의 코드로 개발할 수 있는 LangChain을 개발했다. 2023년 3월 1000만 달러의 시드 투자를 주도했고, 불과 몇 주 뒤 2000만 달러 규모의 투자를 진행하였다. 이때 이미 회사는 93k 팔로워를 보유하고 있었다. 대중 속의 그는 앤드류 응과 같은 AI 석학과 잘 소통하는 모습을 보인다.
이렇게 빠르게 성장한 LangChain에 대한 첫 번째 커밋은 프롬프트 템플릿을 위한 Python의 가벼운 래퍼 클래스로써 시작된 것이다. 그는 2022년 초에 Notion 채팅 구현 시 LLM만으로는 쉽지 않다는 것을 발견했다. 이 문제를 가만두지 않고, LangChain 라이브러리를 재빨리 개선했다.
현재 LangChain은 LLM과 더불어 전문적인 채팅, 에이전트 서비스, 정보 생성 서비스 개발에 필수적인 기술이 되었다.
레퍼런스
- Chroma Multi-Modal Demo with LlamaIndex - LlamaIndex
- 오픈소스 기반 LLM의 민주화, LLAMA-2 논문 분석 및 기술 요약하기
- 머신러닝 딥러닝 신경망 개념, 종류 및 개발
- 어텐션 기반 트랜스포머 딥러닝 모델 이해, 활용 사례 및 파치토치를 통한 간단한 사용방법 소개
- 트랜스포머 디코더 핵심 코드 구현을 통한 동작 메커니즘 이해하기
- 오픈소스 기반 LLM의 민주화, LLAMA-2 논문 분석 및 기술 요약
- 생성AI 멀티모달 모델 개발의 시작. OpenAI의 CLIP모델 이해, 코드 분석, 개발, 사용하기
- Computer vision deep learning: computer vision based on deep learning lecture materials, github
- GPU 없는 로컬에서 서비스 가능한 경량 소형 LLM, LLAMA2.c 빌드, 실행, 학습 및 코드 분석하기
- 대중화된 멀티모달 생성AI 모델, Stable Diffusion 아키텍처 분석과 동작 원리 이해
댓글 없음:
댓글 쓰기